溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關c++ atomic原子編程中Memory Order的示例分析的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
但是,基于內核對象的同步,會帶來昂貴的上下文切換(用戶態切換到內核態,占用1000個以上的cpu周期)。就需要使用另一種方法 —— 原子指令。
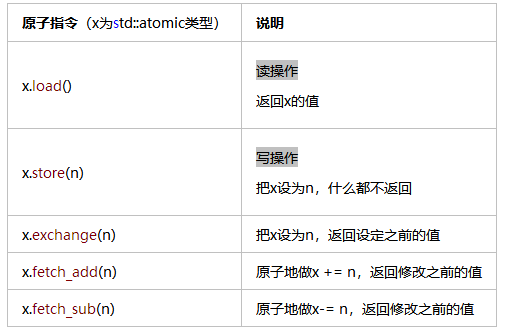
僅靠原子技術實現不了對資源的訪問控制,即使簡單計數操作,看上去正確的代碼也可能會crash。
這里的關鍵在于編譯器和cpu實施的重排指令導致了讀寫順序的變化。只要沒有依賴,代碼中在后面的指令就可能跑到前面去,編譯器和CPU都會這么做。
注1:單線程代碼不需要關心亂序的問題。因為亂序至少要保證這一原則:不能改變單線程程序的執行行為
注2:內核對象多線程編程在設計的時候都阻止了它們調用點中的亂序(已經隱式包含memory barrier),不需要考慮亂序的問題。
注3:使用用戶模式下的線程同步時,亂序的效果才會顯露無疑。
程序員可以使用c++11 atomic提供了6種memory order,來在編程語言層面對編譯器和cpu實施的重排指令行為進行控制
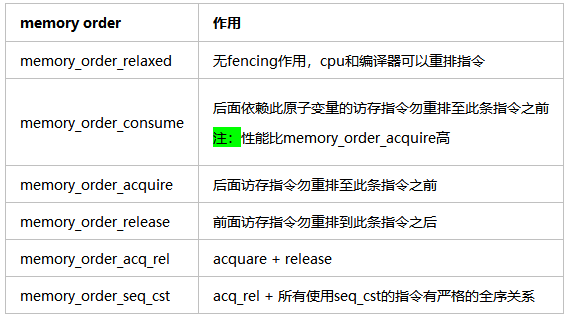
多線程編程時,通過這些標志位,來讀寫原子變量,可以組合出4種同步模型:
Relaxed ordering
Release-Acquire ordering
Release-Consume ordering
Sequentially-consistent ordering
默認情況下,std::atomic使用的是Sequentially-consistent ordering(最嚴格的同步模型)。但在某些場景下,合理使用其它3種ordering,可以讓編譯器優化生成的代碼,從而提高性能。
在這種模型下,std::atomic的load()和store()都要帶上memory_order_relaxed參數。Relaxed ordering僅僅保證load()和store()是原子操作,除此之外,不提供任何跨線程的同步。
先看看一個簡單的例子:
std::atomic<int> x = 0; // global variable std::atomic<int> y = 0; // global variable Thread-1: Thread-2: r1 = y.load(memory_order_relaxed); // A r2 = x.load(memory_order_relaxed); // C x.store(r1, memory_order_relaxed); // B y.store(42, memory_order_relaxed); // D
執行完上面的程序,可能出現r1 == r2 == 42。理解這一點并不難,因為編譯器允許調整 C 和 D 的執行順序。
如果程序的執行順序是 D -> A -> B -> C,那么就會出現r1 == r2 == 42。
如果某個操作只要求是原子操作,不需要其它同步的保障,就可以使用 Relaxed ordering。程序計數器是一種典型的應用場景。
#include <cassert>
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> cnt = {0};
void f()
{
for (int n = 0; n < 1000; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
}
}
int main()
{
std::vector<std::thread> v;
for (int n = 0; n < 10; ++n) {
v.emplace_back(f);
}
for (auto& t : v) {
t.join();
}
assert(cnt == 10000); // never failed
return 0;
}在這種模型下,store()使用memory_order_release,而load()使用memory_order_acquire。這種模型有兩種效果,第一種是可以限制 CPU 指令的重排:
(1)在store()之前的所有讀寫操作,不允許被移動到這個store()的后面。 // write-release語義
(2)在load()之后的所有讀寫操作,不允許被移動到這個load()的前面。 // read-acquire語義
該模型可以保證:如果Thread-1的store()的那個值,成功被 Thread-2的load()到了,那么 Thread-1在store()之前對內存的所有寫入操作,此時對 Thread-2 來說,都是可見的。
下面的例子闡述了這種模型的原理:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<bool> ready{ false };
int data = 0;
void producer()
{
data = 100; // A
ready.store(true, std::memory_order_release); // B
}
void consumer()
{
while (!ready.load(std::memory_order_acquire)) // C
;
assert(data == 100); // never failed // D
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}讓我們分析一下這個過程:
首先 A 不允許被移動到 B 的后面。
同樣 D 也不允許被移動到 C 的前面。
當 C 從 while 循環中退出了,說明 C 讀取到了 B store()的那個值,此時,Thread-2 保證能夠看見 Thread-1 執行 B 之前的所有寫入操作(也即是 A)。
下面單件為例來說明:
class Singleton
{
public:
static Singleton* get_instance() {
Singleton* tmp = instance_.load(std::memory_order_acquire);
if (tmp == nullptr) {
std::unique_lock<std::mutex> lk(mutex_);
tmp = instance_;
if (tmp == nullptr) {
tmp = new Singleton();
instance_.store(std::memory_order_release);
}
}
return tmp;
}
private:
Singleton() = default;
static std::atomic<Singleton*> instance_;
static std::mutex mutex_;
};獲取和釋放語義,是實現鎖的基礎(Spinlock, Mutex, RWLock, ...),所有被[Read Acquire,Write Release]包含的區域,即構成了一個臨界區,臨界區里的內存操作,不會亂序到臨界區之外執行。
read-acquire(判斷是否加鎖,沒則加鎖,否則循環等待)
-------------------------------------------------------------------------
all memory operation stay between the line(臨界區)
-------------------------------------------------------------------------
write-release(釋放鎖)
實現代碼如下:
#include <atomic>
class simple_spin_lock
{
public:
simple_spin_lock() = default;
void lock()
{
while (flag.test_and_set(std::memory_order_acquire))
continue;
}
void unlock()
{
flag.clear(std::memory_order_release);
}
private:
simple_spin_lock(const simple_spin_lock&) = delete;
simple_spin_lock& operator =(const simple_spin_lock&) = delete;
std::atomic_flag flag = ATOMIC_FLAG_INIT;
};①對std::atomic_flag的操作具有原子性,保證了同一時間,只有一個線程能夠lock成功,其余線程全部在while循環
②使用了acquire內存屏障, 所以lock具有獲取語義
③使用了release內存屏障, 所以unlock具有釋放語義
在這種模型下,store()使用memory_order_release,而load()使用memory_order_consume。這種模型有兩種效果,第一種是可以限制 CPU 指令的重排:
(1)在store()之前的所有讀寫操作,不允許被移動到這個store()的后面。
(2)在load()之后的所有依賴此原子變量的讀寫操作,不允許被移動到這個load()的前面。
注:不依賴此原子變量的讀寫操作可能會CPU指令重排
下面的例子闡述了這種模型的原理:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
// thread1
void producer()
{
std::string* p = new std::string("Hello"); // A
data = 42; // B
ptr.store(p, std::memory_order_release); // C
}
// thread2
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_consume))) // D
;
assert(*p2 == "Hello"); //E always true: *p2 carries dependency from ptr
assert(data == 42); // F may be false: data does not carry dependency from ptr
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}所有以memory_order_seq_cst為參數的原子操作(不限于同一個原子變量),對所有線程來說有一個全局順序(total order)
并且兩個相鄰memory_order_seq_cst原子操作之間的其他操作(包括非原子變量操作),不能reorder到這兩個相鄰操作之外
enum class EMemoryOrder
{
// Provides no guarantees that the operation will be ordered relative to any other operation.
Relaxed,
// Establishes a single total order of all other atomic operations marked with this.
SequentiallyConsistent // Load和Store函數缺省為該類型
};詳見:UnrealEngine\Engine\Source\Runtime\Core\Public\Templates\Atomic.h
Atomic相關的測試代碼見:UnrealEngine\Engine\Source\Runtime\Core\Private\Tests\Misc\AtomicTest.cpp
感謝各位的閱讀!關于“c++ atomic原子編程中Memory Order的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





