溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關C++高并發場景下讀多寫少的優化方案是什么,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
一談到高并發的優化方案,往往能想到模塊水平拆分、數據庫讀寫分離、分庫分表,加緩存、加mq等,這些都是從系統架構上解決。單模塊作為系統的組成單元,其性能好壞也能很大的影響整體性能,本文從單模塊下讀多寫少的場景出發,探討其解決方案,以其更好的實現高并發。
不同的業務場景,讀和寫的頻率各有側重,有兩種常見的業務場景:
讀多寫少:典型場景如廣告檢索端、白名單更新維護、loadbalancer
讀少寫多:典型場景如qps統計
本文針對讀多寫少(也稱一寫多讀)場景下遇到的問題進行分析,并探討一種合適的解決方案。
讀多寫少的場景,服務大部分情況下都是處于讀,而且要求讀的耗時不能太長,一般是毫秒或者更低的級別;更新的頻率就不是那么頻繁,如幾秒鐘更新一次。通過簡單的加互斥鎖,騰出一片臨界區,往往能到達預期的效果,保證數據更新正確。
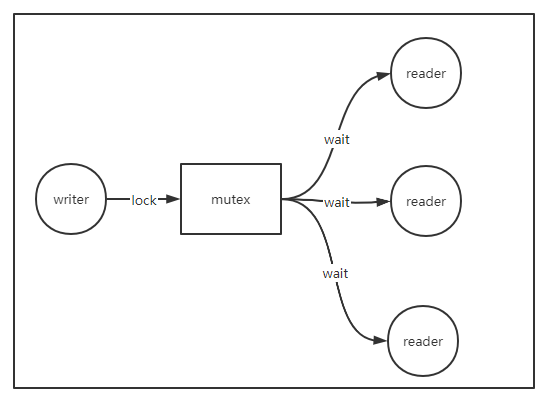
但是,只要加了鎖,就會帶來競爭,即使加的是讀寫鎖,雖然讀之間不互斥,但寫一樣會影響讀,而且讀寫同時爭奪鎖的時候,鎖優先分配給寫(讀寫鎖的特性)。例如,寫的時候,要求所有的讀請求阻塞住,等到寫線程或協程釋放鎖之后才能讀。如果寫的臨界區耗時比較大,則所有的讀請求都會受影響,從監控圖上看,這時候會有一根很尖的耗時毛刺,所有的讀請求都在隊列中等待處理,如果在下個更新周期來之前,服務能處理完這些讀請求,可能情況沒那么糟糕。但極端情況下,如果下個更新周期來了,讀請求還沒處理完,就會形成一個惡性循環,不斷的有讀請求在隊列中等待,最終導致隊列被擠滿,服務出現假死,情況再惡劣一點的話,上游服務發現某個節點假死后,由于負載均衡策略,一般會重試請求其他節點,這時候其他節點的壓力跟著增加了,最終導致整個系統出現雪崩。
因此,加鎖在高并發場景下要盡量避免,如果避免不了,需要讓鎖的粒度盡量小,接近無鎖(lock-free)更好,簡單的對一大片臨界區加鎖,在高并發場景下不是一種合適的解決方案
有一種數據結構叫雙緩沖,其這種數據結構很常見,例如顯示屏的顯示原理,顯示屏顯示的當前幀,下一幀已經在后臺的buffer準備好,等時間周期一到,就直接替換前臺幀,這樣能做到無卡頓的刷新,其實現的指導思想是空間換時間,這種數據結構的工作原理如下:
數據分為前臺和后臺
所有讀線程讀前臺數據,不用加鎖,通過一個指針來指向當前讀的前臺數據
只有一個線程負責更新,更新的時候,先準備好后臺數據,接著直接切指針,這之后所有新進來的讀請求都看到了新的前臺數據
有部分讀還落在老的前臺那里處理,因為更新還不算完成,也就不能退出寫線程,寫線程需要等待所有落在老前臺的線程讀完成后,才能退出,在退出之前,順便再更新一遍老前臺數據(也就當前的新后臺),可以保證前后臺數據一致,這點在做增量更新的時候有用
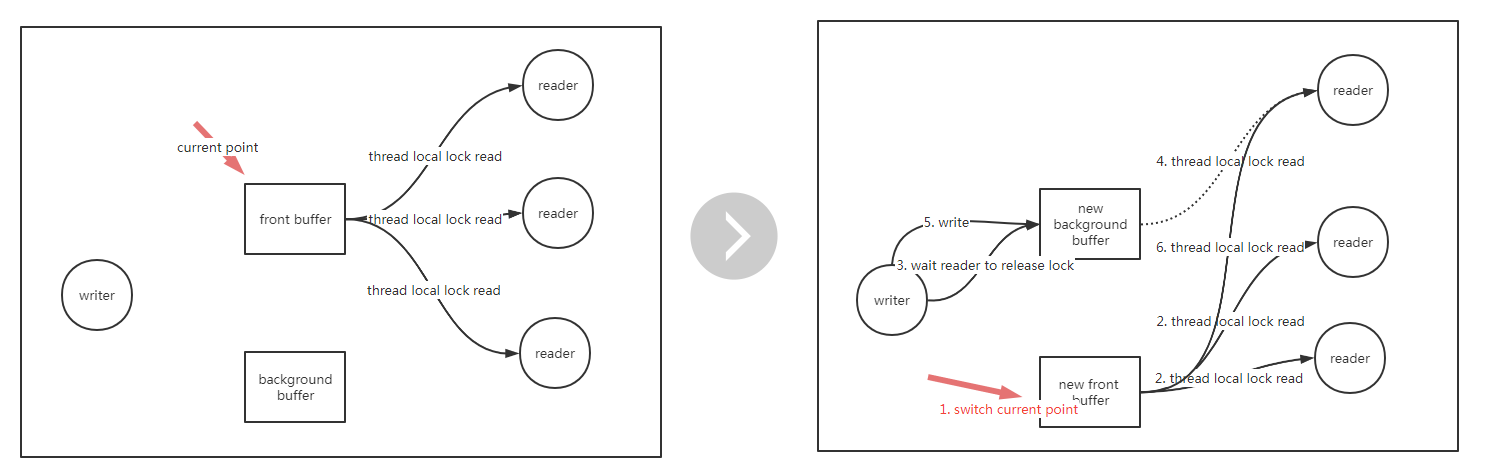
寫線程要怎么知道所有的讀線程在老前臺中的讀完成了呢?
一種做法是讓各個讀線程都維護一把鎖,讀的時候鎖住,這時候不會影響其他線程的讀,但會影響寫,讀完后釋放鎖(某些時候可能會有通知寫線程的開銷,但寫本身很少),寫線程只需要確認鎖有沒有釋放了,確認完了后馬上釋放,確認這個動作非常快(小于25ns,1s=103ms=106us=10^9ns),讀線程幾乎不會感覺到鎖的存在。
每個線程都有一把自己的鎖,需要用全局的map來做線程id和鎖的映射嗎?
不需要,而且這樣做全局map就要加全局鎖了,又回到了剛開始分析中遇到的問題了。其實,每個線程可以有私有存儲(thread local storage,簡稱TLS),如果是協程,就對應這協程的TLS(但對于go語言,官方是不支持TLS的,想實現類似功能,要么就想辦法獲取到TLS,要么就不要基于協程鎖,而是用全局鎖,但盡量讓鎖粒度小,本文主要針對C++語言,暫時不深入討論其他語言的實現)。這樣每個讀線程鎖的是自己的鎖,不會影響到其他的讀線程,鎖的目的僅僅是為了保證讀優先。
對于線程私有存儲,可以使用pthread_key_create, pthread_setspecific,pthread_getspecific系列函數
讀
template <typename T, typename TLS>
int DoublyBufferedData<T, TLS>::Read(
typename DoublyBufferedData<T, TLS>::ScopedPtr* ptr) { // ScopedPtr析構的時候,會釋放鎖
Wrapper* w = static_cast<Wrapper*>(pthread_getspecific(_wrapper_key)); //非首次讀,獲取pthread local lock
if (BAIDU_LIKELY(w != NULL)) {
w->BeginRead(); // 鎖住
ptr->_data = UnsafeRead();
ptr->_w = w;
return 0;
}
w = AddWrapper();
if (BAIDU_LIKELY(w != NULL)) {
const int rc = pthread_setspecific(_wrapper_key, w); // 首次讀,設置pthread local lock
if (rc == 0) {
w->BeginRead();
ptr->_data = UnsafeRead();
ptr->_w = w;
return 0;
}
}
return -1;
}寫
template <typename T, typename TLS>
template <typename Fn>
size_t DoublyBufferedData<T, TLS>::Modify(Fn& fn) {
BAIDU_SCOPED_LOCK(_modify_mutex); // 加鎖,保證只有一個寫
int bg_index = !_index.load(butil::memory_order_relaxed); // 指向后臺buffer
const size_t ret = fn(_data[bg_index]); // 修改后臺buffer
if (!ret) {
return 0;
}
// 切指針
_index.store(bg_index, butil::memory_order_release);
bg_index = !bg_index;
// 等所有讀老前臺的線程讀結束
{
BAIDU_SCOPED_LOCK(_wrappers_mutex);
for (size_t i = 0; i < _wrappers.size(); ++i) {
_wrappers[i]->WaitReadDone();
}
}
// 確認沒有讀了,直接修改新后臺數據,對其新前臺
const size_t ret2 = fn(_data[bg_index]);
return ret2;
}完整實現請參考brpc的DoublyBufferData
普通的雙緩沖加載實現
基于計數器,用atomic,保證原子性,讀進入臨界區,計數器+1,退出-1,寫判斷計數器為0則切換,但計數器是全局鎖。這種方案C++也可以采取,只是計數器畢竟也是全局鎖,性能會差那么一丟丟。即使用智能指針shared_ptr,也會面臨智能指針引用計數互斥的問題。之所以用計數器,而不用TLS,是因為go不支持TLS,對比TLS版本和計數器版本,TLS性能更優,因為沒有搶計數器的互斥問題,但搶計數器本身很快,性能沒測試過,可以試試。
sync.Map的實現
也是基于計數器,只是計數器是為了讓讀前臺緩存失效的概率不要太高,有抑制和收斂的作用,實現了讀的無鎖,少部分情況下,前臺緩存讀不到數據的時候,會去讀后臺緩存,這時候也要加鎖,同時計數器+1。計數器數值達到一定程度(超過后臺緩存的元素個數),就執行切換
是否適用于讀少寫多的場景
不合適,雙緩沖優先保證讀的性能,寫多讀少的場景需要優先保證寫的性能。
上述就是小編為大家分享的C++高并發場景下讀多寫少的優化方案是什么了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





