溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章和大家了解一下使用python爬取吉首大學網站成績單的操作介紹。有一定的參考價值,有需要的朋友可以參考一下,希望對大家有所幫助。
https://github.com/chen0495/pythonCrawlerForJSU
python 3.5即以上
request、BeautifulSoup、numpy、pandas.
安裝BeautifulSoup使用命令pip install BeautifulSoup4
登陸學校成績單查詢網站,修改cookie.

按F12后按Ctrl+R刷新一下,獲取cookie的方法見下圖:
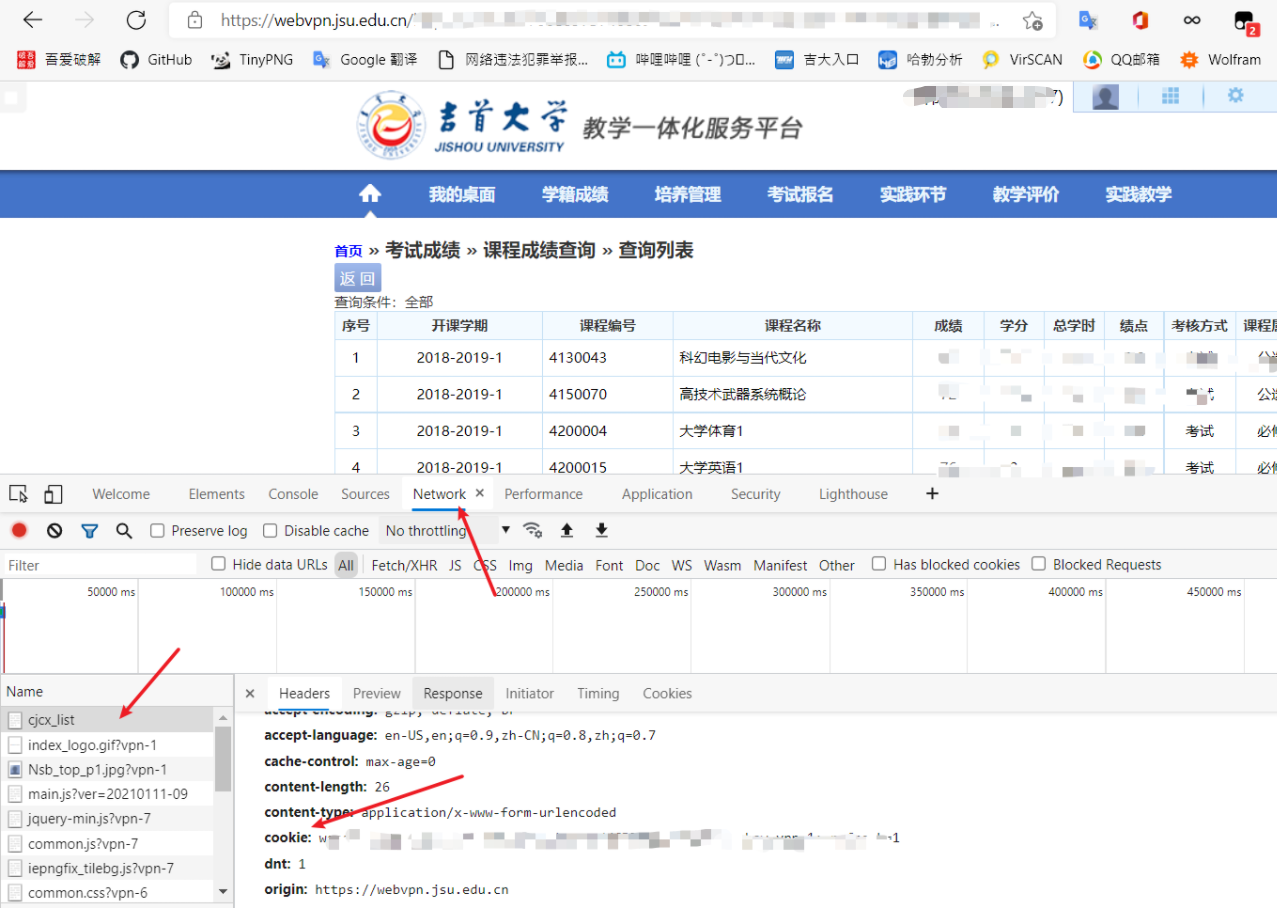
修改爬蟲url為自己的成績單網址.

運行src/main.py文件即可在/result下得到csv文件.
# -*- coding: utf-8 -*-
# @Time : 5/29/2021 2:13 PM
# @Author : Chen0495
# @Email : 1346565673@qq.com|chenweiin612@gmail.com
# @File : main.py
# @Software: PyCharm
import requests as rq
from bs4 import BeautifulSoup as BS
import numpy as np
import pandas as pd
rq.adapters.DEFAULT_RETRIES = 5
s = rq.session()
s.keep_alive = False # 關閉多余連接
header = { # 請更改cookie
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4501.0 Safari/537.36 Edg/92.0.891.1',
'cookie' : 'wengine_vpn_ticketwebvpn_jsu_edu_cn=xxxxxxxxxx; show_vpn=1; refresh=1'
}
# 請更改url
r = rq.get('https://webvpn.jsu.edu.cn/https/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx/jsxsd/kscj/cjcx_list', headers = header, verify=False)
soup = BS(r.text,'html.parser')
head = []
for th in soup.find_all("th"):
head.append(th.text)
while '' in head:
head.remove('')
head.remove('序號')
context = np.array(head)
x = []
flag = 0
for td in soup.find_all("td"):
if flag!=0 and flag%11!=1:
x.append(td.text)
if flag%11==0 and flag!=0:
context = np.row_stack((context,np.array(x)))
x.clear()
flag+=1
context = np.delete(context,0,axis=0)
data = pd.DataFrame(context,columns=head)
print(data)
# 生成文件,親更改文件名
data.to_csv('../result/result.csv',encoding='utf-8-sig')以上就是使用python爬取吉首大學網站成績單的操作介紹的簡略介紹,當然詳細使用上面的不同還得要大家自己使用過才領會。如果想了解更多,歡迎關注億速云行業資訊頻道哦!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





