溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關爬取大學本學期績點的方法的內容。小編覺得挺實用的,因此分享給大家做個參考。一起跟隨小編過來看看吧。
本篇目標
1.模擬登錄學生成績管理系統
2.抓取本學期成績界面
3.計算打印本學期成績
1.URL的獲取
恩,博主來自山東大學~
先貼一個URL,讓大家知道我們學校學生信息系統的網站構架,主頁是 http://jwxt.sdu.edu.cn:7890/zhxt_bks/zhxt_bks.html,山東大學學生個人信息系統,進去之后,Oh不,他竟然用了frame,一個多么古老的而又任性的寫法,真是驚出一身冷汗~
算了,就算他是frame又能拿我怎么樣?我們點到登錄界面,審查一下元素,先看看登錄界面的URL是怎樣的?
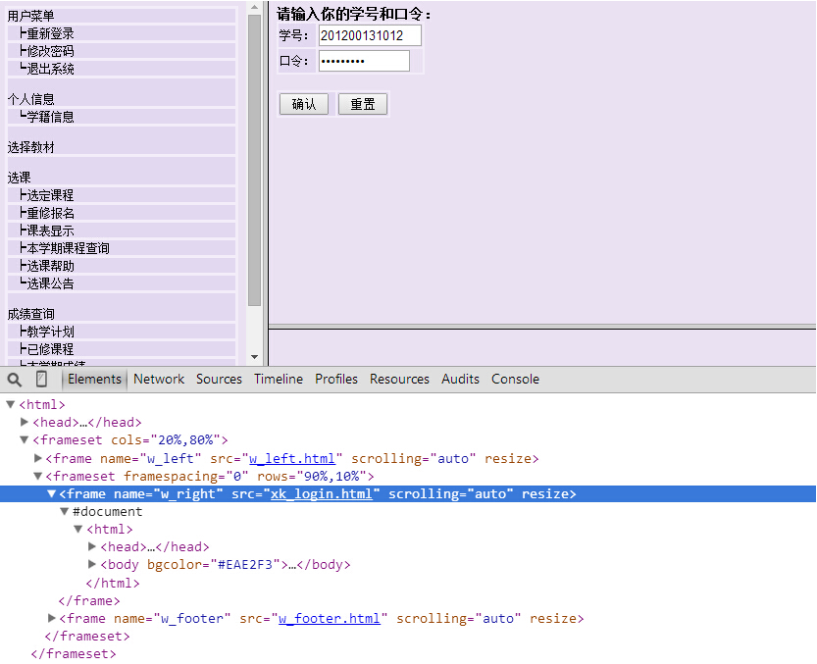
恩,看到了右側的frame名稱,src=”xk_login.html”,可以分析出完整的登錄界面的網址為 http://jwxt.sdu.edu.cn:7890/zhxt_bks/xk_login.html,點進去看看,真是棒棒噠,他喵的竟然是清華大學選課系統,醉了,你說你抄襲就抄襲吧,改改名字也不錯啊~
算了,就不和他計較了。現在,我們登錄一下,用瀏覽器監聽網絡。
我用的是獵豹瀏覽器,審查元素時會有一個網絡的選項,如果大家用的Chrome,也有相對應的功能,Firefox需要裝插件HttpFox,同樣可以實現。
這個網絡監聽功能可以監聽表單的傳送以及請求頭,響應頭等等的信息。截個圖看一下,恩,我偷偷把密碼隱藏了,你看不到~
大家看到的是登錄之后出現的信息以及NetWork監聽,顯示了hearders的詳細信息。
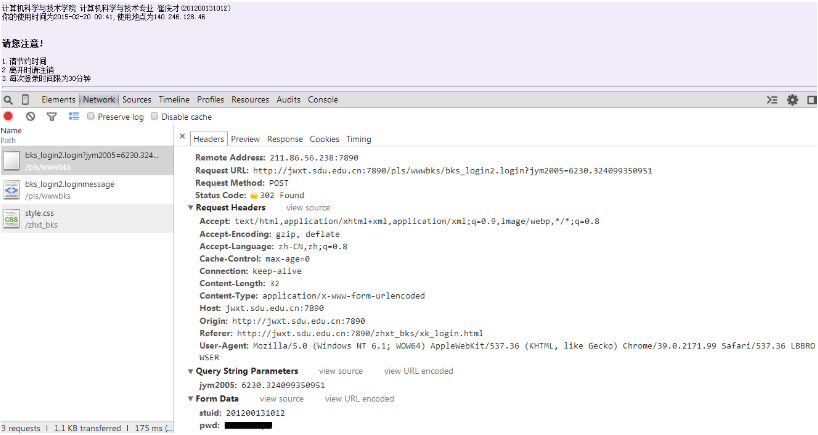
最主要的內容,我們可以發現有一個表單提交的過程,提交方式為POST,兩個參數分別為stuid和pwd。
請求的URL為 http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login,沒錯,找到表單數據和目標地址就是這么簡單。
在這里注意,剛才的 http://jwxt.sdu.edu.cn:7890/zhxt_bks/xk_login.html 只是登錄界面的地址,剛剛得到的這個地址才是登錄索要提交到的真正的URL。希望大家這里不要混淆。
不知道山大這個系統有沒有做headers的檢查,我們先不管這么多,先嘗試一下模擬登錄并保存Cookie。
2.模擬登錄
好,通過以上信息,我們已經找到了登錄的目標地址為 http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login
有一個表單提交到這個URL,表單的兩個內容分別為stuid和pwd,學號和密碼,沒有其他的隱藏信息,提交方式為POST。
好,現在我們首先構造以下代碼來完成登錄。看看會不會獲取到登錄之后的提示頁面。
__author__ = 'CQC'
# -*- coding:utf-8 -*-
import urllib
import urllib2
import cookielib
import re
#山東大學績點運算
class SDU:
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login'
self.cookies = cookielib.CookieJar()
self.postdata = urllib.urlencode({
'stuid':'201200131012',
'pwd':'xxxxxx'
})
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookies))
def getPage(self):
request = urllib2.Request(
url = self.loginUrl,
data = self.postdata)
result = self.opener.open(request)
#打印登錄內容
print result.read().decode('gbk')
sdu = SDU()
sdu.getPage()測試一下,竟然成功了,山大這網竟然沒有做headers檢查,很順利就登錄進去了。
說明一下,在這里我們利用了前面所說的cookie,用到了CookieJar這個對象來保存cookies,另外通過構建opener,利用open方法實現了登錄。如果大家覺得這里有疑惑,請看 Python爬蟲入門六之Cookie的使用,這篇文章說得比較詳細。
好,我們看一下運行結果
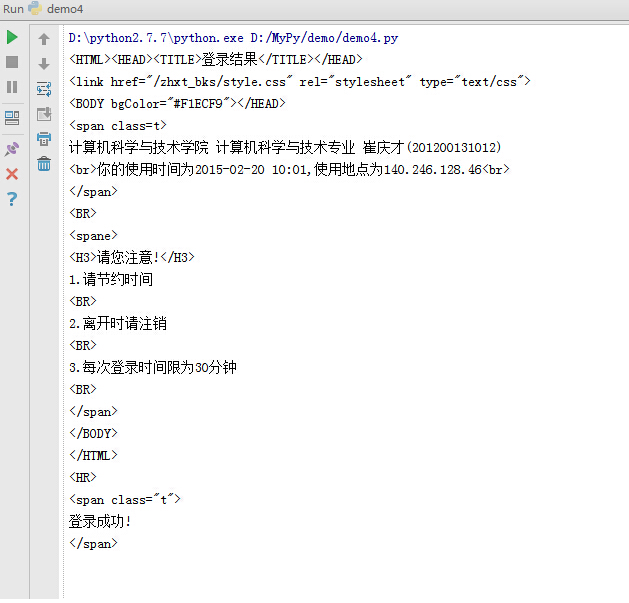
酸爽啊,接下來我們只要再獲取到本學期成績界面然后把成績抓取出來就好了。
3.抓取本學期成績
讓我們先在瀏覽器中找到本學期成績界面,點擊左邊的本學期成績。
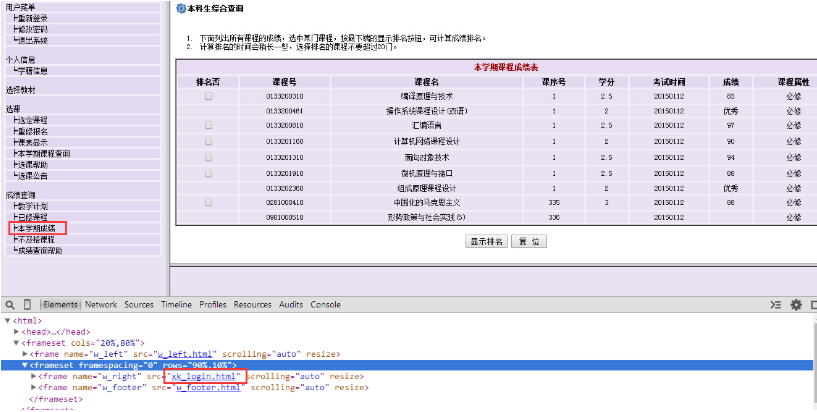
重新審查元素,你會發現這個frame的src還是沒有變,仍然是xk_login.html,引起這個頁面變化的原因是在左邊的本學期成績這個超鏈接設置了一個目標frame,所以,那個頁面就顯示在右側了。
所以,讓我們再審查一下本學期成績這個超鏈接的內容是什么~
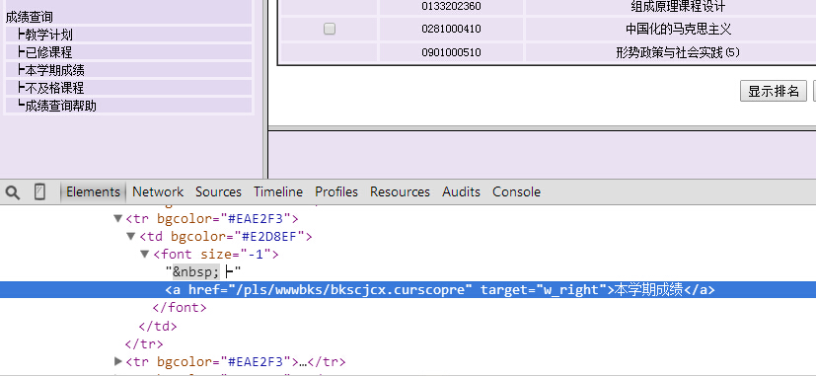
恩,找到它了,<a href=”/pls/wwwbks/bkscjcx.curscopre” target=”w_right”>本學期成績</a>
那么,完整的URL就是 http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bkscjcx.curscopre,好,URL已經找到了,我們繼續完善一下代碼,獲取這個頁面。
__author__ = 'CQC'
# -*- coding:utf-8 -*-
import urllib
import urllib2
import cookielib
import re
#山東大學績點運算
class SDU:
def __init__(self):
#登錄URL
self.loginUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login'
#本學期成績URL
self.gradeUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bkscjcx.curscopre'
self.cookies = cookielib.CookieJar()
self.postdata = urllib.urlencode({
'stuid':'201200131012',
'pwd':'xxxxxx'
})
#構建opener
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookies))
#獲取本學期成績頁面
def getPage(self):
request = urllib2.Request(
url = self.loginUrl,
data = self.postdata)
result = self.opener.open(request)
result = self.opener.open(self.gradeUrl)
#打印登錄內容
print result.read().decode('gbk')
sdu = SDU()
sdu.getPage()上面的代碼,我們最主要的是增加了
result = self.opener.open(self.gradeUrl)
這句代碼,用原來的opener 訪問一個本學期成績的URL即可。運行結果如下
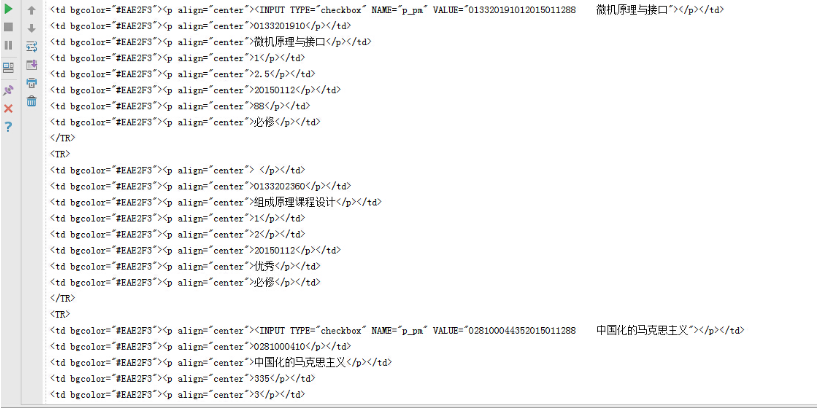
恩,本學期成績的頁面已經被我們抓取下來了,接下來用正則表達式提取一下,然后計算學分即可
4.抓取有效信息
接下來我們就把頁面內容提取一下,最主要的便是學分以及分數了。
平均績點 = ∑(每科學分*每科分數)/總學分
所以我們把每科的學分以及分數抓取下來就好了,對于有些課打了良好或者優秀等級的,我們不進行抓取。
我們可以發現每一科都是TR標簽,然后是一系列的td標簽
<TR> <td bgcolor="#EAE2F3"><p align="center"><INPUT TYPE="checkbox" NAME="p_pm" VALUE="013320131012015011294 面向 對象技術"></p></td> <td bgcolor="#EAE2F3"><p align="center">0133201310</p></td> <td bgcolor="#EAE2F3"><p align="center">面向對象技術</p></td> <td bgcolor="#EAE2F3"><p align="center">1</p></td> <td bgcolor="#EAE2F3"><p align="center">2.5</p></td> <td bgcolor="#EAE2F3"><p align="center">20150112</p></td> <td bgcolor="#EAE2F3"><p align="center">94</p></td> <td bgcolor="#EAE2F3"><p align="center">必修</p></td> </TR>
我們用下面的正則表達式進行提取即可,部分代碼如下
page = self.getPage()
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',page,re.S)
for item in myItems:
self.credit.append(item[0].encode('gbk'))
self.grades.append(item[1].encode('gbk'))主要利用了findall方法,這個方法在此就不多介紹了,前面我們已經用過多次了。
得到的學分和分數我們都用列表list進行存儲,所以用了 append 方法,每獲取到一個信息就把它加進去。
5.整理計算最后績點
恩,像上面那樣把學分績點都保存到列表list中了,所以我們最后用一個公式來計算學分績點就好了,最后整理后的代碼如下:
# -*- coding: utf-8 -*-
import urllib
import urllib2
import cookielib
import re
import string
#績點運算
class SDU:
#類的初始化
def __init__(self):
#登錄URL
self.loginUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login'
#成績URL
self.gradeUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bkscjcx.curscopre'
#CookieJar對象
self.cookies = cookielib.CookieJar()
#表單數據
self.postdata = urllib.urlencode({
'stuid':'201200131012',
'pwd':'xxxxx'
})
#構建opener
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookies))
#學分list
self.credit = []
#成績list
self.grades = []
def getPage(self):
req = urllib2.Request(
url = self.loginUrl,
data = self.postdata)
result = self.opener.open(req)
result = self.opener.open(self.gradeUrl)
#返回本學期成績頁面
return result.read().decode('gbk')
def getGrades(self):
#獲得本學期成績頁面
page = self.getPage()
#正則匹配
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',page,re.S)
for item in myItems:
self.credit.append(item[0].encode('gbk'))
self.grades.append(item[1].encode('gbk'))
self.getGrade()
def getGrade(self):
#計算總績點
sum = 0.0
weight = 0.0
for i in range(len(self.credit)):
if(self.grades[i].isdigit()):
sum += string.atof(self.credit[i])*string.atof(self.grades[i])
weight += string.atof(self.credit[i])
print u"本學期績點為:",sum/weight
sdu = SDU()
sdu.getGrades()好,最后就會打印輸出本學期績點是多少,小伙伴們最主要的了解上面的編程思路就好。
最主要的內容就是Cookie的使用,模擬登錄的功能。
感謝各位的閱讀!關于爬取大學本學期績點的方法就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





