溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
學習爬蟲,最初的操作便是來模擬瀏覽器向服務器發出一個請求,那么我們需要從哪個地方做起呢?請求需要我們自己來構造嗎?我們需要關心請求這個數據結構的實現嗎?我們需要了解 HTTP、TCP、IP 層的網絡傳輸通信嗎?我們需要知道服務器的響應和應答原理嗎?
可能你不知道無從下手,不用擔心,Python 的強大之處就是提供了功能齊全的類庫來幫助我們完成這些請求,最基礎的 HTTP 庫有 Urllib、Httplib2、Requests、Treq 等。
拿 Urllib 這個庫來說,有了它,我們只需要關心請求的鏈接是什么,需要傳的參數是什么以及可選的請求頭設置就好了,不用深入到底層去了解它到底是怎樣來傳輸和通信的。有了它,兩行代碼就可以完成一個請求和響應的處理過程,得到網頁內容,是不是感覺方便極了?
接下來,就讓我們從最基礎的部分開始了解這些庫的使用方法吧。
在 Python2 版本中,有 Urllib 和 Urlib2 兩個庫可以用來實現Request的發送。而在 Python3 中,已經不存在 Urllib2 這個庫了,統一為 Urllib,其官方文檔鏈接為:https://docs.python.org/3/lib...
我們首先了解一下 Urllib 庫,它是 Python 內置的 HTTP 請求庫,也就是說我們不需要額外安裝即可使用,它包含四個模塊:
在這里重點對前三個模塊進行下講解。
使用 Urllib 的 request 模塊我們可以方便地實現 Request 的發送并得到 Response,我們本節來看下它的具體用法。
urllib.request 模塊提供了最基本的構造 HTTP 請求的方法,利用它可以模擬瀏覽器的一個請求發起過程,同時它還帶有處理authenticaton(授權驗證),redirections(重定向),cookies(瀏覽器Cookies)以及其它內容。
我們來感受一下它的強大之處,以 Python 官網為例,我們來把這個網頁抓下來:
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.read().decode('utf-8'))
Python資源分享qun 784758214 ,內有安裝包,PDF,學習視頻,這里是Python學習者的聚集地,零基礎,進階,都歡迎看一下運行結果,如圖 3-1 所示:
圖 3-1 運行結果
真正的代碼只有兩行,我們便完成了 Python 官網的抓取,輸出了網頁的源代碼,得到了源代碼之后呢?我們想要的鏈接、圖片地址、文本信息不就都可以提取出來了嗎?
接下來我們看下它返回的到底是什么,利用 type() 方法輸出 Response 的類型。
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(type(response))輸出結果如下:
<class 'http.client.HTTPResponse'>通過輸出結果可以發現它是一個 HTTPResposne 類型的對象,它主要包含的方法有 read()、readinto()、getheader(name)、getheaders()、fileno() 等方法和 msg、version、status、reason、debuglevel、closed 等屬性。
得到這個對象之后,我們把它賦值為 response 變量,然后就可以調用這些方法和屬性,得到返回結果的一系列信息了。
例如調用 read() 方法可以得到返回的網頁內容,調用 status 屬性就可以得到返回結果的狀態碼,如 200 代表請求成功,404 代表網頁未找到等。
下面再來一個實例感受一下:
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))運行結果如下:
200
[('Server', 'nginx'), ('Content-Type', 'text/html; charset=utf-8'), ('X-Frame-Options', 'SAMEORIGIN'), ('X-Clacks-Overhead', 'GNU Terry Pratchett'), ('Content-Length', '47397'), ('Accept-Ranges', 'bytes'), ('Date', 'Mon, 01 Aug 2016 09:57:31 GMT'), ('Via', '1.1 varnish'), ('Age', '2473'), ('Connection', 'close'), ('X-Served-By', 'cache-lcy1125-LCY'), ('X-Cache', 'HIT'), ('X-Cache-Hits', '23'), ('Vary', 'Cookie'), ('Strict-Transport-Security', 'max-age=63072000; includeSubDomains')]
nginx可見,三個輸出分別輸出了響應的狀態碼,響應的頭信息,以及通過調用 getheader() 方法并傳遞一個參數 Server 獲取了 headers 中的 Server 值,結果是 nginx,意思就是服務器是 nginx 搭建的。
利用以上最基本的 urlopen() 方法,我們可以完成最基本的簡單網頁的 GET 請求抓取。
如果我們想給鏈接傳遞一些參數該怎么實現呢?我們首先看一下 urlopen() 函數的API:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)可以發現除了第一個參數可以傳遞 URL 之外,我們還可以傳遞其它的內容,比如 data(附加數據)、timeout(超時時間)等等。
下面我們詳細說明下這幾個參數的用法。
data 參數是可選的,如果要添加 data,它要是字節流編碼格式的內容,即 bytes 類型,通過 bytes() 方法可以進行轉化,另外如果傳遞了這個 data 參數,它的請求方式就不再是 GET 方式請求,而是 POST。
下面用一個實例來感受一下:
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read())在這里我們傳遞了一個參數 word,值是 hello。它需要被轉碼成bytes(字節流)類型。其中轉字節流采用了 bytes() 方法,第一個參數需要是 str(字符串)類型,需要用 urllib.parse 模塊里的 urlencode() 方法來將參數字典轉化為字符串。第二個參數指定編碼格式,在這里指定為 utf8。
在這里請求的站點是 httpbin.org,它可以提供 HTTP 請求測試,本次我們請求的 URL 為:http://httpbin.org/post,這個鏈接可以用來測試 POST 請求,它可以輸出 Request 的一些信息,其中就包含我們傳遞的 data 參數。
運行結果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"word": "hello"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "10",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.7"
},
"json": null,
"origin": "124.126.3.94, 124.126.3.94",
"url": "https://httpbin.org/post"
}我們傳遞的參數出現在了 form 字段中,這表明是模擬了表單提交的方式,以 POST 方式傳輸數據。
timeout 參數可以設置超時時間,單位為秒,意思就是如果請求超出了設置的這個時間還沒有得到響應,就會拋出異常,如果不指定,就會使用全局默認時間。它支持 HTTP、HTTPS、FTP 請求。
下面來用一個實例感受一下:
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get', timeout=1)
print(response.read())運行結果如下:
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "/var/py/python/urllibtest.py", line 4, in <module> response = urllib.request.urlopen('http://httpbin.org/get', timeout=1)
...
urllib.error.URLError: <urlopen error timed out>在這里我們設置了超時時間是 1 秒,程序 1 秒過后服務器依然沒有響應,于是拋出了 URLError 異常,它屬于 urllib.error 模塊,錯誤原因是超時。
因此我們可以通過設置這個超時時間來控制一個網頁如果長時間未響應就跳過它的抓取,利用 try except 語句就可以實現這樣的操作,代碼如下:
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get', timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('TIME OUT')在這里我們請求了 http://httpbin.org/get 這個測試鏈接,設置了超時時間是 0.1 秒,然后捕獲了 URLError 這個異常,然后判斷異常原因是 socket.timeout 類型,意思就是超時異常,就得出它確實是因為超時而報錯,打印輸出了 TIME OUT。
運行結果如下:
TIME OUT常理來說,0.1 秒內基本不可能得到服務器響應,因此輸出了 TIME OUT 的提示。
這樣,我們可以通過設置 timeout 這個參數來實現超時處理,有時還是很有用的。
還有 context 參數,它必須是 ssl.SSLContext 類型,用來指定 SSL 設置。
cafile 和 capath 兩個參數是指定 CA 證書和它的路徑,這個在請求 HTTPS 鏈接時會有用。
cadefault 參數現在已經棄用了,默認為 False。
以上講解了 urlopen() 方法的用法,通過這個最基本的函數可以完成簡單的請求和網頁抓取,如需更加詳細了解,可以參見官方文檔:https://docs.python.org/3/lib...。
由上我們知道利用 urlopen() 方法可以實現最基本請求的發起,但這幾個簡單的參數并不足以構建一個完整的請求,如果請求中需要加入 Headers 等信息,我們就可以利用更強大的 Request 類來構建一個請求。
首先我們用一個實例來感受一下 Request 的用法:
import urllib.request
request = urllib.request.Request('https://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
Python資源分享qun 784758214 ,內有安裝包,PDF,學習視頻,這里是Python學習者的聚集地,零基礎,進階,都歡迎可以發現,我們依然是用 urlopen() 方法來發送這個請求,只不過這次 urlopen() 方法的參數不再是一個 URL,而是一個 Request 類型的對象,通過構造這個這個數據結構,一方面我們可以將請求獨立成一個對象,另一方面可配置參數更加豐富和靈活。
下面我們看一下 Request 都可以通過怎樣的參數來構造,它的構造方法如下:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)添加 Request Headers 最常用的用法就是通過修改 User-Agent 來偽裝瀏覽器,默認的 User-Agent 是 Python-urllib,我們可以通過修改它來偽裝瀏覽器,比如要偽裝火狐瀏覽器,你可以把它設置為:
Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11下面我們傳入多個參數構建一個 Request 來感受一下:
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent': ,
'Host': 'httpbin.org'
}
dict = {
'name': 'Germey'
}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))在這里我們通過四個參數構造了一個 Request,url 即請求 URL,在headers 中指定了 User-Agent 和 Host,傳遞的參數 data 用了 urlencode() 和 bytes() 方法來轉成字節流,另外指定了請求方式為 POST。
運行結果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "mark"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "9",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"
},
"json": null,
"origin": "124.126.3.94, 124.126.3.94",
"url": "https://httpbin.org/post"
}
通過觀察結果可以發現,我們成功設置了 data,headers 以及 method。
另外 headers 也可以用 add_header() 方法來添加。
req = request.Request(url=url, data=data, method='POST')
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')如此一來,我們就可以更加方便地構造一個 Request,實現請求的發送啦。
有沒有發現,在上面的過程中,我們雖然可以構造 Request,但是一些更高級的操作,比如 Cookies 處理,代理設置等操作我們該怎么辦?
接下來就需要更強大的工具 Handler 登場了。
簡而言之我們可以把它理解為各種處理器,有專門處理登錄驗證的,有處理 Cookies 的,有處理代理設置的,利用它們我們幾乎可以做到任何 HTTP 請求中所有的事情。
首先介紹下 urllib.request 模塊里的 BaseHandler類,它是所有其他 Handler 的父類,它提供了最基本的 Handler 的方法,例如 default_open()、protocol_request() 方法等。
接下來就有各種 Handler 子類繼承這個 BaseHandler 類,舉例幾個如下:
它們怎么來使用,不用著急,下面會有實例為你演示。
另外一個比較重要的類就是 OpenerDirector,我們可以稱之為 Opener,我們之前用過 urlopen() 這個方法,實際上它就是 Urllib為我們提供的一個 Opener。
那么為什么要引入 Opener 呢?因為我們需要實現更高級的功能,之前我們使用的 Request、urlopen() 相當于類庫為你封裝好了極其常用的請求方法,利用它們兩個我們就可以完成基本的請求,但是現在不一樣了,我們需要實現更高級的功能,所以我們需要深入一層進行配置,使用更底層的實例來完成我們的操作。
所以,在這里我們就用到了比調用 urlopen() 的對象的更普遍的對象,也就是 Opener。
Opener 可以使用 open() 方法,返回的類型和 urlopen() 如出一轍。那么它和 Handler 有什么關系?簡而言之,就是利用 Handler 來構建 Opener。
下面我們用幾個實例來感受一下他們的用法:
有些網站在打開時它就彈出了一個框,直接提示你輸入用戶名和密碼,認證成功之后才能查看頁面,如圖 3-2 所示:
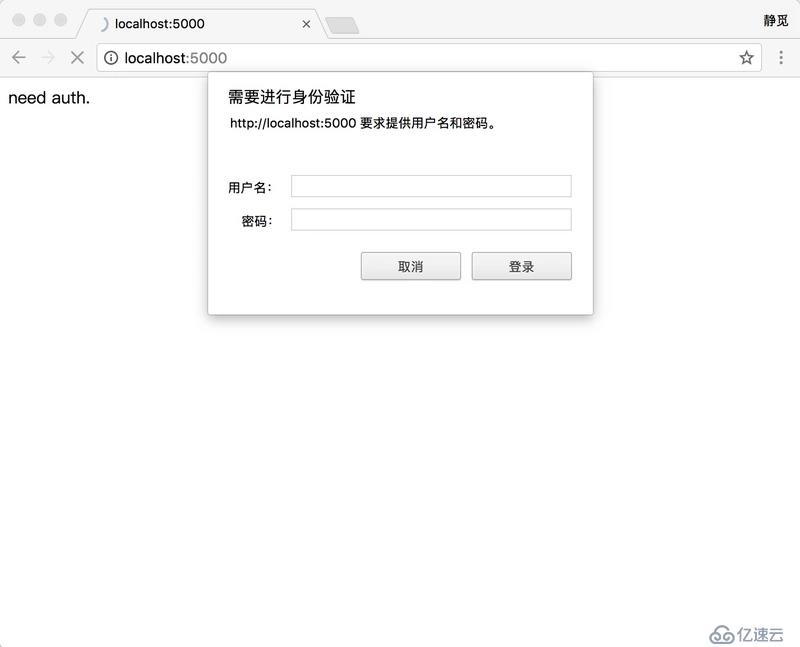
圖 3-2 認證頁面
那么我們如果要請求這樣的頁面怎么辦呢?
借助于 HTTPBasicAuthHandler 就可以完成,代碼如下:
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = 'username'
password = 'password'
url = 'http://localhost:5000/'
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url, username, password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode('utf-8')
print(html)
except URLError as e:
print(e.reason)在這里,首先實例化了一個 HTTPBasicAuthHandler 對象,參數是 HTTPPasswordMgrWithDefaultRealm 對象,它利用 add_password() 添加進去用戶名和密碼,這樣我們就建立了一個處理認證的 Handler。
接下來利用 build_opener() 方法來利用這個 Handler 構建一個 Opener,那么這個 Opener 在發送請求的時候就相當于已經認證成功了。
接下來利用 Opener 的 open() 方法打開鏈接,就可以完成認證了,在這里獲取到的結果就是認證后的頁面源碼內容。
在做爬蟲的時候免不了要使用代理,如果要添加代理,可以這樣做:
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
'http': 'http://127.0.0.1:9743',
'https': 'https://127.0.0.1:9743'
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)在此本地搭建了一個代理,運行在 9743 端口上。
在這里使用了 ProxyHandler,ProxyHandler 的參數是一個字典,鍵名是協議類型,比如 HTTP 還是 HTTPS 等,鍵值是代理鏈接,可以添加多個代理。
然后利用 build_opener() 方法利用這個 Handler 構造一個 Opener,然后發送請求即可。
Cookies 的處理就需要 Cookies 相關的 Handler 了。
我們先用一個實例來感受一下怎樣將網站的 Cookies 獲取下來,代碼如下:
import http.cookiejar, urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+"="+item.value)首先我們必須聲明一個 CookieJar 對象,接下來我們就需要利用 HTTPCookieProcessor 來構建一個 Handler,最后利用 build_opener() 方法構建出 Opener,執行 open() 函數即可。
運行結果如下:
BAIDUID=4329C4F53C9D52CA1E6AC6CA18DA356F:FG=1
BIDUPSID=4329C4F53C9D52CA1E6AC6CA18DA356F
H_PS_PSSID=26522_1449_21090_29135_29238_28519_29098_29368_28834_29221_26350_20719
PSTM=1560743836
delPer=0
BDSVRTM=0
BD_HOME=0可以看到輸出了每一條 Cookie 的名稱還有值。
不過既然能輸出,那可不可以輸出成文件格式呢?我們知道 Cookies 實際也是以文本形式保存的。
答案當然是肯定的,我們用下面的實例來感受一下:
filename = 'cookies.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)這時的 CookieJar就需要換成 MozillaCookieJar,生成文件時需要用到它,它是 CookieJar 的子類,可以用來處理 Cookies 和文件相關的事件,讀取和保存 Cookies,它可以將 Cookies 保存成 Mozilla 型瀏覽器的 Cookies 的格式。
運行之后可以發現生成了一個 cookies.txt 文件。
內容如下:
# Netscape HTTP Cookie File
# http://curl.haxx.se/rfc/cookie_spec.html
# This is a generated file! Do not edit.
.baidu.com TRUE / FALSE 3708227627 BAIDUID 7270D7398BA0805A388F14699840D7DC:FG=1
.baidu.com TRUE / FALSE 3708227627 BIDUPSID 7270D7398BA0805A388F14699840D7DC
.baidu.com TRUE / FALSE H_PS_PSSID 1430_21093_29135_29237_28518_29098_29368_28837_29221
.baidu.com TRUE / FALSE 3708227627 PSTM 1560743980
.baidu.com TRUE / FALSE delPer 0
www.baidu.com FALSE / FALSE BDSVRTM 0
www.baidu.com FALSE / FALSE BD_HOME 0
另外還有一個 LWPCookieJar,同樣可以讀取和保存 Cookies,但是保存的格式和 MozillaCookieJar 的不一樣,它會保存成與 libwww-perl(LWP) 的 Cookies 文件格式。
要保存成 LWP 格式的 Cookies 文件,可以在聲明時就改為:
cookie = http.cookiejar.LWPCookieJar(filename)生成的內容如下:
#LWP-Cookies-2.0
Set-Cookie3: BAIDUID="A19638BE46B11E183219DD2CFBC4557E:FG=1"; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2087-07-05 07:14:46Z"; version=0
Set-Cookie3: BIDUPSID=A19638BE46B11E183219DD2CFBC4557E; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2087-07-05 07:14:46Z"; version=0
Set-Cookie3: H_PS_PSSID=26524_1444_21120_29135_29237_28519_29098_29369_28832_29220; path="/"; domain=".baidu.com"; path_spec; domain_dot; discard; version=0
Set-Cookie3: PSTM=1560744039; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2087-07-05 07:14:46Z"; version=0
Set-Cookie3: delPer=0; path="/"; domain=".baidu.com"; path_spec; domain_dot; discard; version=0
Set-Cookie3: BDSVRTM=0; path="/"; domain="www.baidu.com"; path_spec; discard; version=0
Set-Cookie3: BD_HOME=0; path="/"; domain="www.baidu.com"; path_spec; discard; version=0
由此看來生成的格式還是有比較大的差異的。
那么生成了 Cookies 文件,怎樣從文件讀取并利用呢?
下面我們以 LWPCookieJar 格式為例來感受一下:
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookies.txt', ignore_discard=True, ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
Python資源分享qun 784758214 ,內有安裝包,PDF,學習視頻,這里是Python學習者的聚集地,零基礎,進階,都歡迎可以看到我們這里調用了 load() 方法來讀取本地的 Coookis 文件,獲取到了 Cookies 的內容。不過前提是我們首先利用生成了 LWPCookieJar 格式的 Cookies,獲取到 Cookies 之后,后面同樣的方法構建 Handler 和 Opener 即可。
運行結果正常輸出百度網頁的源代碼。
好,通過如上用法,我們可以實現絕大多數請求功能的設置了。
以上便是 Urllib 庫中 request 模塊的基本用法
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





