溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
上一篇內容,已經學會了使用簡單的語句對網頁進行抓取。接下來,詳細看下urlopen的兩個重要參數url和data,學習如何發送數據data
一、urlopen的url參數 Agent

url不僅可以是一個字符串,例如:http://www.baidu.com。url也可以是一個Request對象,這就需要我們先定義一個Request對象,然后將這個Request對象作為urlopen的參數使用,方法如下:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
req = request.Request("http://fanyi.baidu.com/")
response = request.urlopen(req)
html = response.read()
html = html.decode("utf-8")
print(html)
同樣,運行這段代碼同樣可以得到網頁信息。可以看一下這段代碼和上個筆記中代碼的不同,對比一下就明白了。
urlopen()返回的對象,可以使用read()進行讀取,同樣也可以使用geturl()方法、info()方法、getcode()方法。

geturl()返回的是一個url的字符串;
info()返回的是一些meta標記的元信息,包括一些服務器的信息;
getcode()返回的是HTTP的狀態碼,如果返回200表示請求成功。
關于META標簽和HTTP狀態碼的內容可以自行百度百科,里面有很詳細的介紹。
了解到這些,我們就可以進行新一輪的測試,新建文件名urllib_test04.py,編寫如下代碼:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
req = request.Request("http://fanyi.baidu.com/")
response = request.urlopen(req)
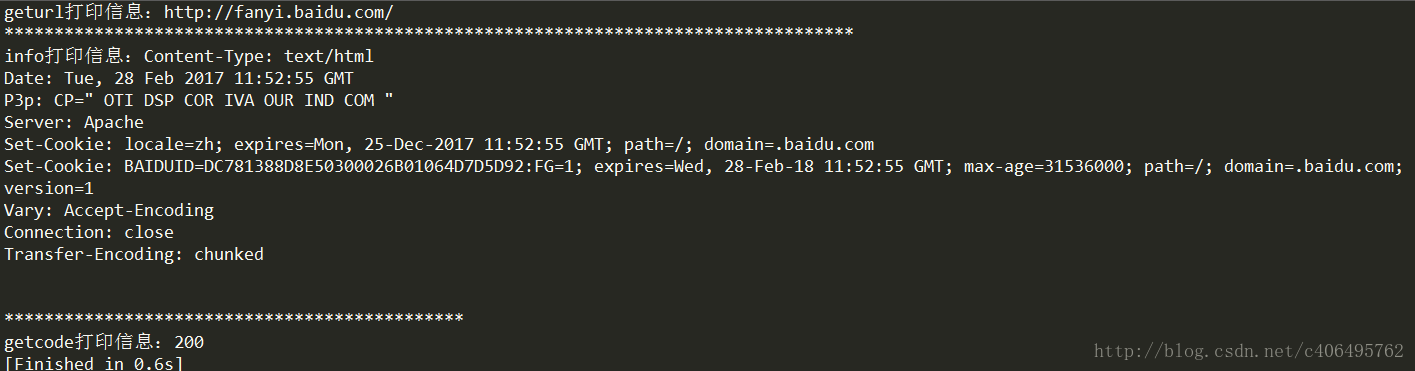
print("geturl打印信息:%s"%(response.geturl()))
print('**********************************************')
print("info打印信息:%s"%(response.info()))
print('**********************************************')
print("getcode打印信息:%s"%(response.getcode()))
可以得到如下運行結果:
二、urlopen的data參數
我們可以使用data參數,向服務器發送數據。根據HTTP規范,GET用于信息獲取,POST是向服務器提交數據的一種請求,再換句話說:
從客戶端向服務器提交數據使用POST;
從服務器獲得數據到客戶端使用GET(GET也可以提交,暫不考慮)。
如果沒有設置urlopen()函數的data參數,HTTP請求采用GET方式,也就是我們從服務器獲取信息,如果我們設置data參數,HTTP請求采用POST方式,也就是我們向服務器傳遞數據。
data參數有自己的格式,它是一個基于application/x-www.form-urlencoded的格式,具體格式我們不用了解, 因為我們可以使用urllib.parse.urlencode()函數將字符串自動轉換成上面所說的格式。
三、發送data實例
向有道翻譯發送data,得到翻譯結果。
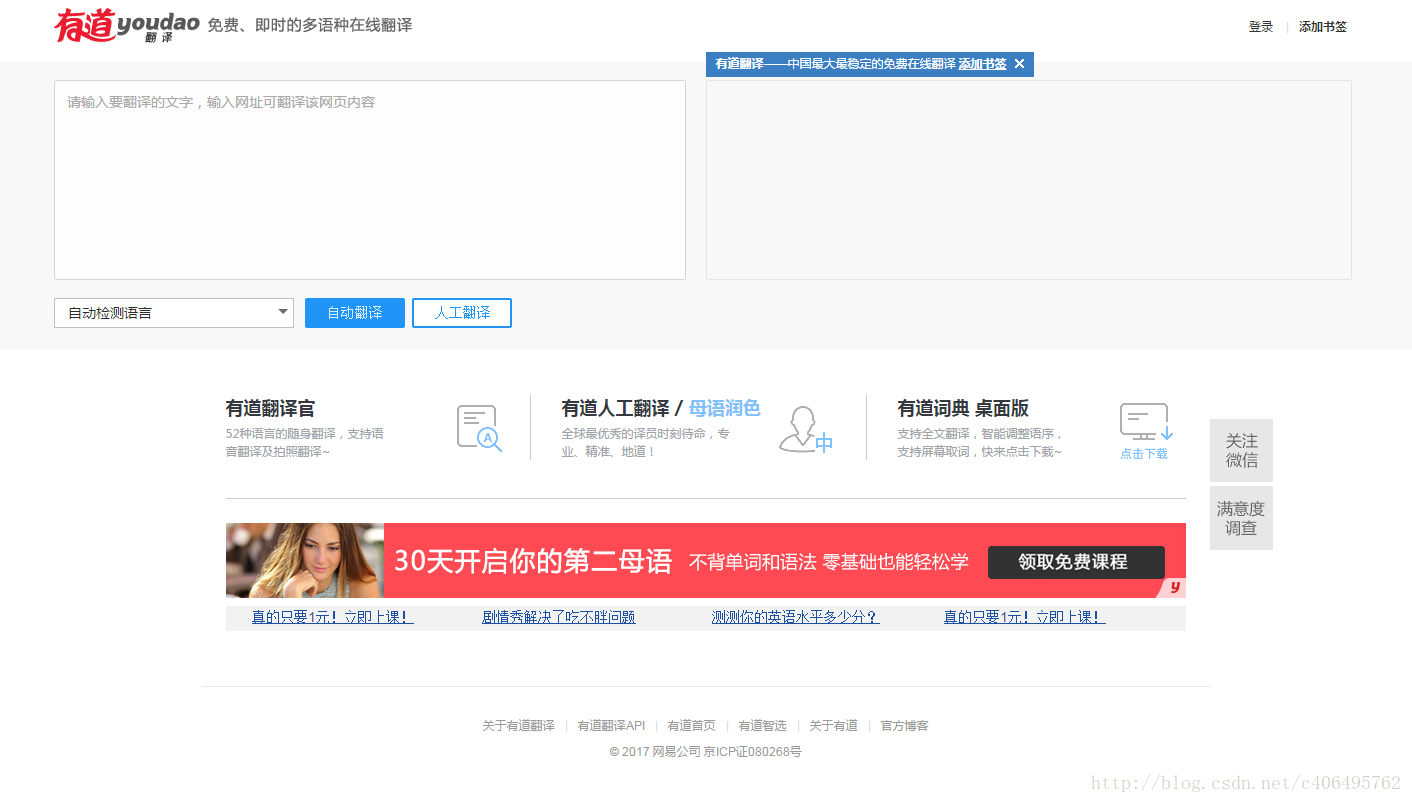
1.打開有道翻譯界面,如下圖所示:
2.鼠標右鍵檢查,也就是審查元素,如下圖所示:
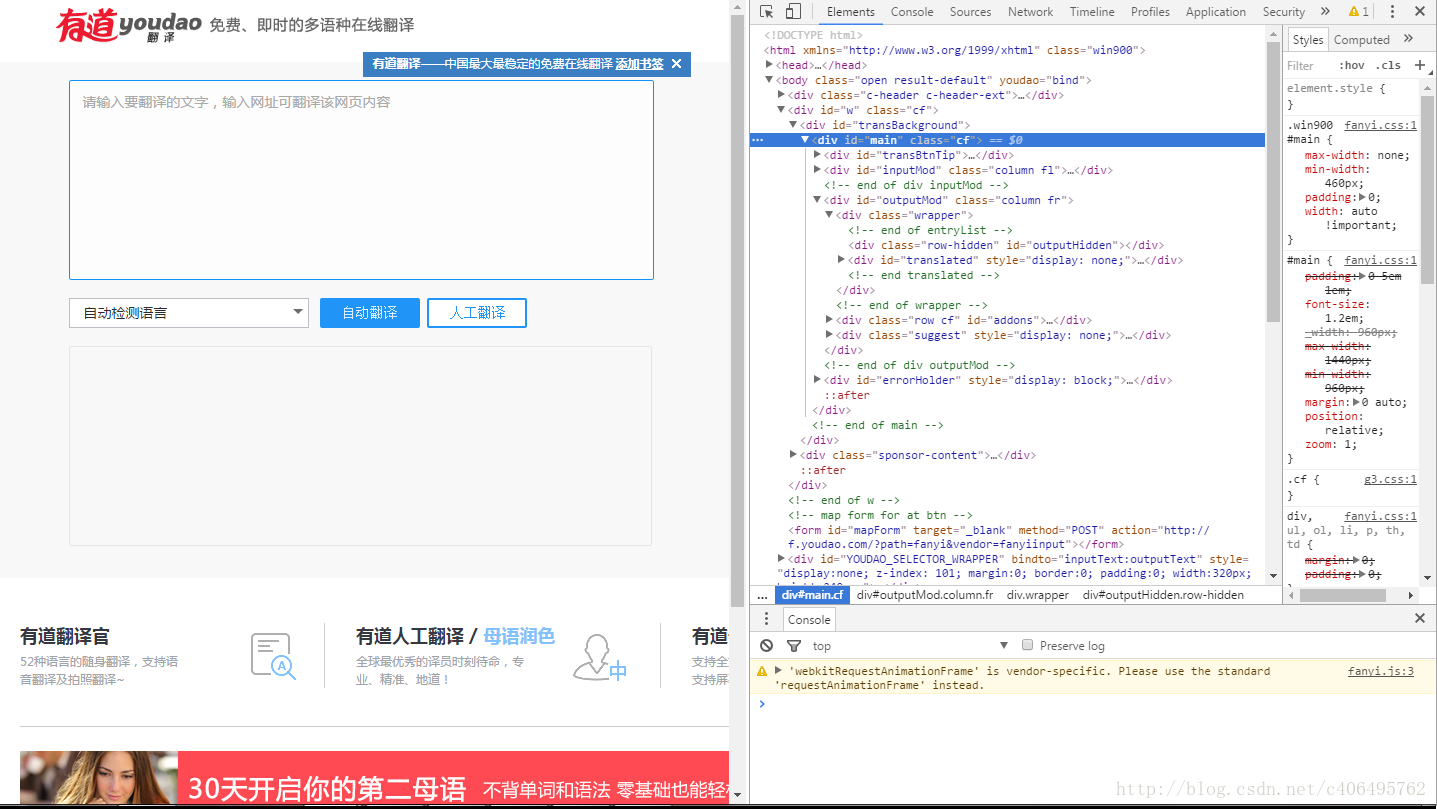
3.選擇右側出現的Network,如下圖所示:

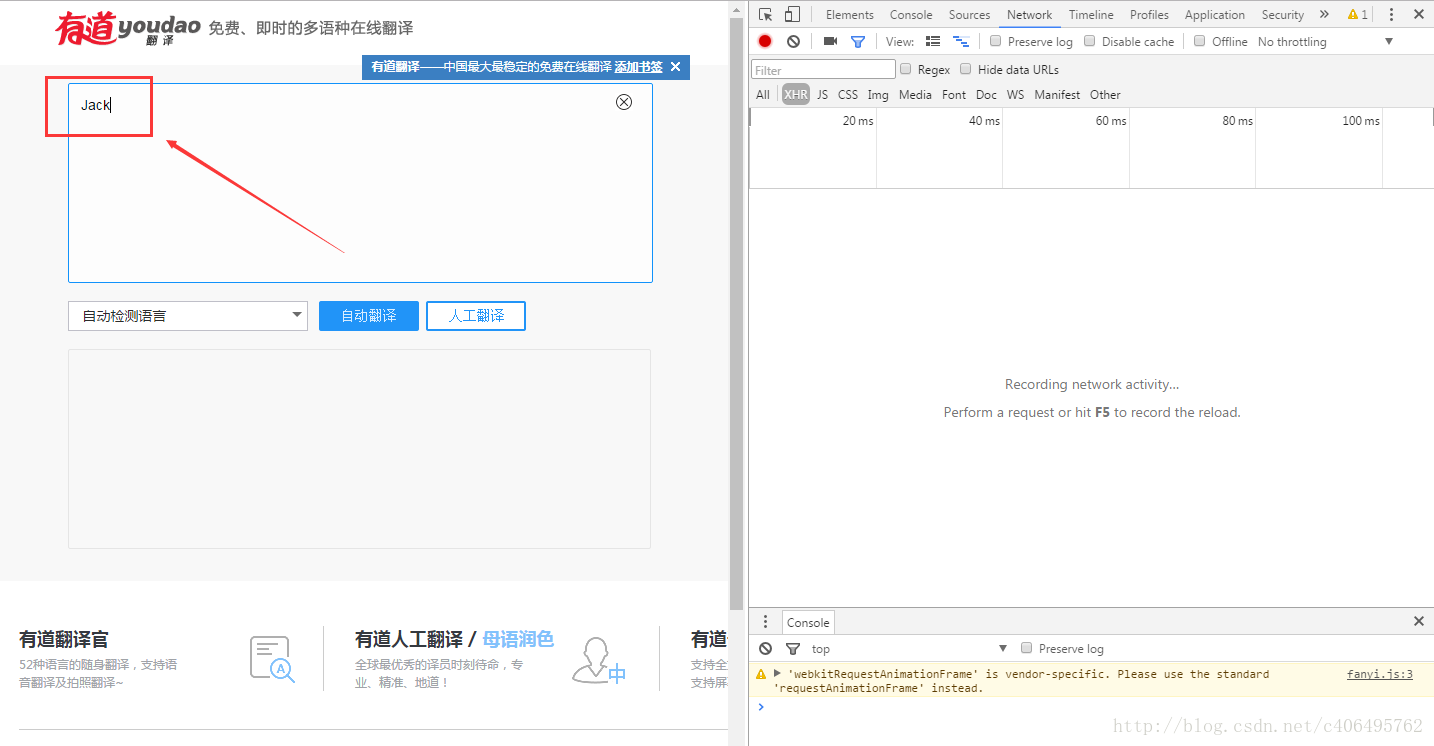
4.在左側輸入翻譯內容,輸入Jack,如下圖所示:
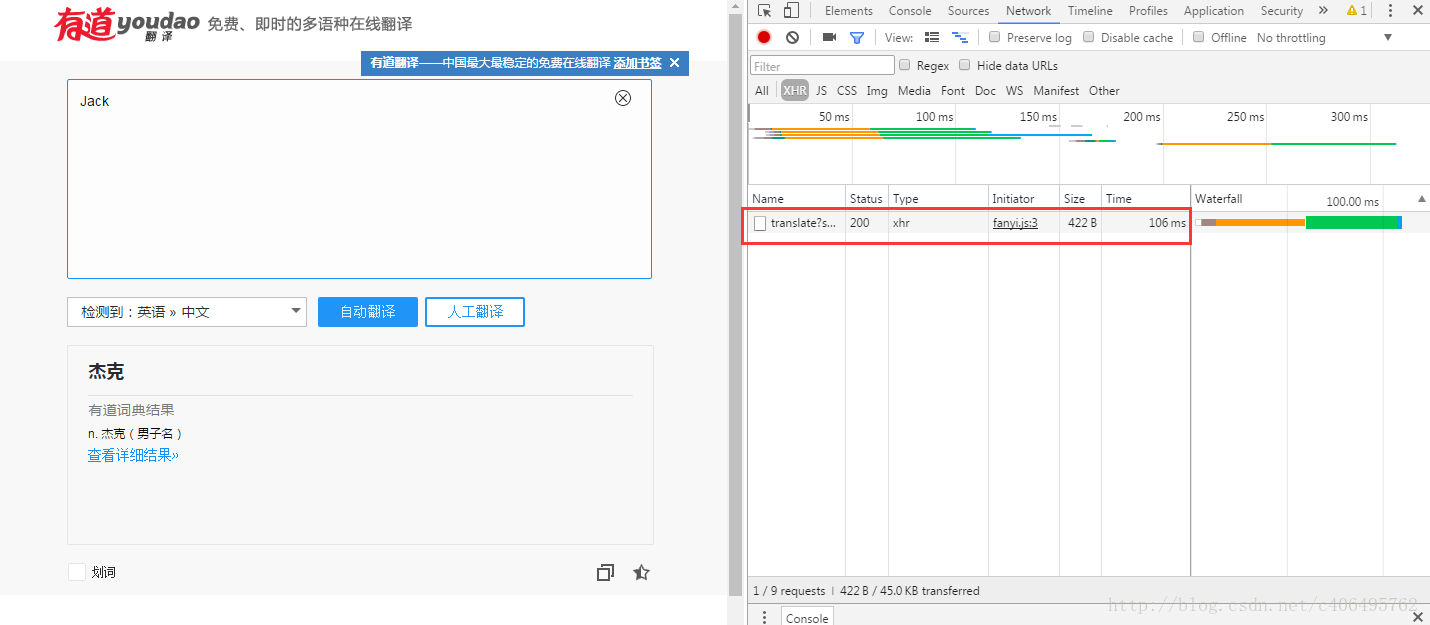
5.點擊自動翻譯按鈕,我們就可以看到右側出現的內容,如下圖所示:
6.點擊上圖紅框中的內容,查看它的信息,如下圖所示:
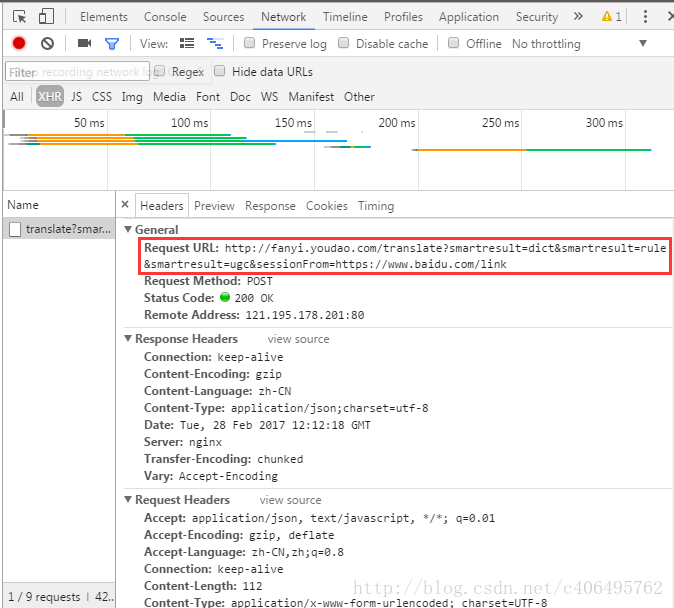
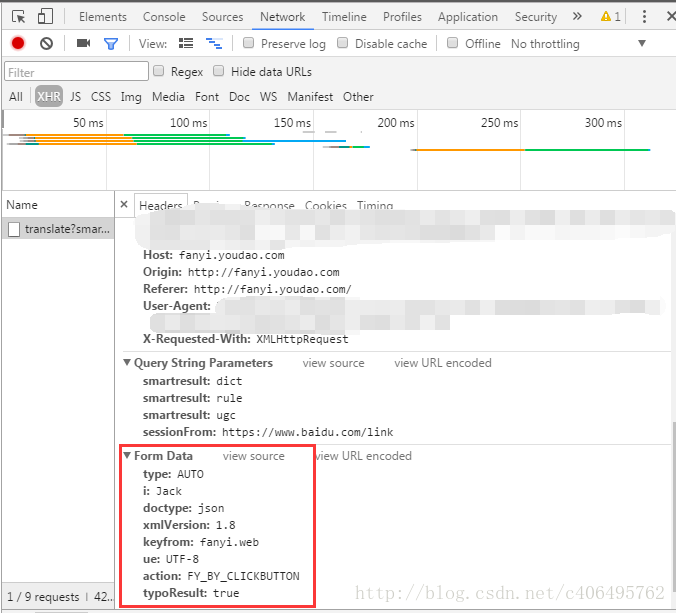
7.記住這些信息,這是我們一會兒寫程序需要用到的。
新建文件translate_test.py,編寫如下代碼:
# -*- coding: UTF-8 -*-
from urllib import request
from urllib import parse
import json
if __name__ == "__main__":
#對應上圖的Request URL
Request_URL = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=https://www.baidu.com/link'
#創建Form_Data字典,存儲上圖的Form Data
Form_Data = {}
Form_Data['type'] = 'AUTO'
Form_Data['i'] = 'Jack'
Form_Data['doctype'] = 'json'
Form_Data['xmlVersion'] = '1.8'
Form_Data['keyfrom'] = 'fanyi.web'
Form_Data['ue'] = 'ue:UTF-8'
Form_Data['action'] = 'FY_BY_CLICKBUTTON'
#使用urlencode方法轉換標準格式
data = parse.urlencode(Form_Data).encode('utf-8')
#傳遞Request對象和轉換完格式的數據
response = request.urlopen(Request_URL,data)
#讀取信息并解碼
html = response.read().decode('utf-8')
#使用JSON
translate_results = json.loads(html)
#找到翻譯結果
translate_results = translate_results['translateResult'][0][0]['tgt']
#打印翻譯信息
print("翻譯的結果是:%s" % translate_results)
這樣我們就可以查看翻譯的結果了,如下圖所示:

JSON是一種輕量級的數據交換格式,我們需要從爬取到的內容中找到JSON格式的數據,這里面保存著我們想要的翻譯結果,再將得到的JSON格式的翻譯結果進行解析,得到我們最終想要的樣子:杰克。
以上所述是小編給大家介紹的Python3網絡爬蟲(二):利用urllib.urlopen向有道翻譯發送數據獲得翻譯結果詳解整合,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對億速云網站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





