溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了Python3爬蟲發送請求的方法,內容清晰明了,對此有興趣的小伙伴可以學習一下,相信大家閱讀完之后會有幫助。
1. urlopen()
urllib.request模塊提供了最基本的構造HTTP請求的方法,利用它可以模擬瀏覽器的一個請求發起過程,同時它還帶有處理授權驗證(authenticaton)、重定向(redirection)、瀏覽器Cookies以及其他內容。
下面我們來看一下它的強大之處。這里以Python官網為例,我們來把這個網頁抓下來:
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.read().decode('utf-8'))運行結果如圖3-1所示。
這里我們只用了兩行代碼,便完成了Python官網的抓取,輸出了網頁的源代碼。得到源代碼之后呢?我們想要的鏈接、圖片地址、文本信息不就都可以提取出來了嗎?
接下來,看看它返回的到底是什么。利用type()方法輸出響應的類型:
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(type(response))輸出結果如下:
<class 'http.client.HTTPResponse'>
可以發現,它是一個HTTPResposne類型的對象。它主要包含read()、readinto()、getheader(name)、getheaders()、fileno()等方法,以及msg、version、status、reason、debuglevel、closed等屬性。
得到這個對象之后,我們把它賦值為response變量,然后就可以調用這些方法和屬性,得到返回結果的一系列信息了。
例如,調用read()方法可以得到返回的網頁內容,調用status屬性可以得到返回結果的狀態碼,如200代表請求成功,404代表網頁未找到等。
下面再通過一個實例來看看:
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))運行結果如下:
200
[('Server', 'nginx'), ('Content-Type', 'text/html; charset=utf-8'), ('X-Frame-Options', 'SAMEORIGIN'),
('X-Clacks-Overhead', 'GNU Terry Pratchett'), ('Content-Length', '47397'), ('Accept-Ranges', 'bytes'),
('Date', 'Mon, 01 Aug 2016 09:57:31 GMT'), ('Via', '1.1 varnish'), ('Age', '2473'), ('Connection', 'close'),
('X-Served-By', 'cache-lcy1125-LCY'), ('X-Cache', 'HIT'), ('X-Cache-Hits', '23'), ('Vary', 'Cookie'),
('Strict-Transport-Security', 'max-age=63072000; includeSubDomains')]
nginx可見,前兩個輸出分別輸出了響應的狀態碼和響應的頭信息,最后一個輸出通過調用getheader()方法并傳遞一個參數Server獲取了響應頭中的Server值,結果是nginx,意思是服務器是用Nginx搭建的。
利用最基本的urlopen()方法,可以完成最基本的簡單網頁的GET請求抓取。
如果想給鏈接傳遞一些參數,該怎么實現呢?首先看一下urlopen()函數的API:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
可以發現,除了第一個參數可以傳遞URL之外,我們還可以傳遞其他內容,比如data(附加數據)、timeout(超時時間)等。
下面我們詳細說明下這幾個參數的用法。
data參數
data參數是可選的。如果要添加該參數,并且如果它是字節流編碼格式的內容,即bytes類型,則需要通過bytes()方法轉化。另外,如果傳遞了這個參數,則它的請求方式就不再是GET方式,而是POST方式。
下面用實例來看一下:
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read())這里我們傳遞了一個參數word,值是hello。它需要被轉碼成bytes(字節流)類型。其中轉字節流采用了bytes()方法,該方法的第一個參數需要是str(字符串)類型,需要用urllib.parse模塊里的urlencode()方法來將參數字典轉化為字符串;第二個參數指定編碼格式,這里指定為utf8。
這里請求的站點是httpbin.org,它可以提供HTTP請求測試。本次我們請求的URL為http://httpbin.org/post,這個鏈接可以用來測試POST請求,它可以輸出請求的一些信息,其中包含我們傳遞的data參數。
運行結果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"word": "hello"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "10",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.5"
},
"json": null,
"origin": "123.124.23.253",
"url": "http://httpbin.org/post"
}我們傳遞的參數出現在了form字段中,這表明是模擬了表單提交的方式,以POST方式傳輸數據。
timeout參數
timeout參數用于設置超時時間,單位為秒,意思就是如果請求超出了設置的這個時間,還沒有得到響應,就會拋出異常。如果不指定該參數,就會使用全局默認時間。它支持HTTP、HTTPS、FTP請求。
下面用實例來看一下:
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get', timeout=1)
print(response.read())運行結果如下:
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "/var/py/python/urllibtest.py", line 4, in <module> response = urllib.
request.urlopen('http://httpbin.org/get', timeout=1)
...
urllib.error.URLError: <urlopen error timed out>這里我們設置超時時間是1秒。程序1秒過后,服務器依然沒有響應,于是拋出了URLError異常。該異常屬于urllib.error模塊,錯誤原因是超時。
因此,可以通過設置這個超時時間來控制一個網頁如果長時間未響應,就跳過它的抓取。這可以利用try except語句來實現,相關代碼如下:
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get', timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('TIME OUT')這里我們請求了http://httpbin.org/get測試鏈接,設置超時時間是0.1秒,然后捕獲了URLError異常,接著判斷異常是socket.timeout類型(意思就是超時異常),從而得出它確實是因為超時而報錯,打印輸出了TIME OUT。
運行結果如下:
TIME OUT
按照常理來說,0.1秒內基本不可能得到服務器響應,因此輸出了TIME OUT的提示。
通過設置timeout這個參數來實現超時處理,有時還是很有用的。
其他參數
除了data參數和timeout參數外,還有context參數,它必須是ssl.SSLContext類型,用來指定SSL設置。
此外,cafile和capath這兩個參數分別指定CA證書和它的路徑,這個在請求HTTPS鏈接時會有用。
cadefault參數現在已經棄用了,其默認值為False。
前面講解了urlopen()方法的用法,通過這個最基本的方法,我們可以完成簡單的請求和網頁抓取。若需更加詳細的信息,可以參見官方文檔:https://docs.python.org/3/library/urllib.request.html。
2. Request
我們知道利用urlopen()方法可以實現最基本請求的發起,但這幾個簡單的參數并不足以構建一個完整的請求。如果請求中需要加入Headers等信息,就可以利用更強大的Request類來構建。
首先,我們用實例來感受一下Request的用法:
import urllib.request
request = urllib.request.Request('https://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))可以發現,我們依然是用urlopen()方法來發送這個請求,只不過這次該方法的參數不再是URL,而是一個Request類型的對象。通過構造這個數據結構,一方面我們可以將請求獨立成一個對象,另一方面可更加豐富和靈活地配置參數。
下面我們看一下Request可以通過怎樣的參數來構造,它的構造方法如下:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)第一個參數url用于請求URL,這是必傳參數,其他都是可選參數。
第二個參數data如果要傳,必須傳bytes(字節流)類型的。如果它是字典,可以先用urllib.parse模塊里的urlencode()編碼。
第三個參數headers是一個字典,它就是請求頭,我們可以在構造請求時通過headers參數直接構造,也可以通過調用請求實例的add_header()方法添加。
添加請求頭最常用的用法就是通過修改User-Agent來偽裝瀏覽器,默認的User-Agent是Python-urllib,我們可以通過修改它來偽裝瀏覽器。比如要偽裝火狐瀏覽器,你可以把它設置為:
Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11
第四個參數origin_req_host指的是請求方的host名稱或者IP地址。
第五個參數unverifiable表示這個請求是否是無法驗證的,默認是False,意思就是說用戶沒有足夠權限來選擇接收這個請求的結果。例如,我們請求一個HTML文檔中的圖片,但是我們沒有自動抓取圖像的權限,這時unverifiable的值就是True`。
第六個參數method是一個字符串,用來指示請求使用的方法,比如GET、POST和PUT等。
下面我們傳入多個參數構建請求來看一下:
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Host': 'httpbin.org'
}
dict = {
'name': 'Germey'
}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))這里我們通過4個參數構造了一個請求,其中url即請求URL,headers中指定了User-Agent和Host,參數data用urlencode()和bytes()方法轉成字節流。另外,指定了請求方式為POST。
運行結果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "Germey"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"
},
"json": null,
"origin": "219.224.169.11",
"url": "http://httpbin.org/post"
}觀察結果可以發現,我們成功設置了data、headers和method。
另外,headers也可以用add_header()方法來添加:
req = request.Request(url=url, data=data, method='POST')
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')如此一來,我們就可以更加方便地構造請求,實現請求的發送啦。
3. 高級用法
在上面的過程中,我們雖然可以構造請求,但是對于一些更高級的操作(比如Cookies處理、代理設置等),我們該怎么辦呢?
接下來,就需要更強大的工具Handler登場了。簡而言之,我們可以把它理解為各種處理器,有專門處理登錄驗證的,有處理Cookies的,有處理代理設置的。利用它們,我們幾乎可以做到HTTP請求中所有的事情。
首先,介紹一下urllib.request模塊里的BaseHandler類,它是所有其他Handler的父類,它提供了最基本的方法,例如default_open()、protocol_request()等。
接下來,就有各種Handler子類繼承這個BaseHandler類,舉例如下。
HTTPDefaultErrorHandler:用于處理HTTP響應錯誤,錯誤都會拋出HTTPError類型的異常。
HTTPRedirectHandler:用于處理重定向。
HTTPCookieProcessor:用于處理Cookies。
ProxyHandler:用于設置代理,默認代理為空。
HTTPPasswordMgr:用于管理密碼,它維護了用戶名和密碼的表。
HTTPBasicAuthHandler:用于管理認證,如果一個鏈接打開時需要認證,那么可以用它來解決認證問題。
另外,還有其他的Handler類,這里就不一一列舉了,詳情可以參考官方文檔:https://docs.python.org/3/library/urllib.request.html#urllib.request.BaseHandler。
關于怎么使用它們,現在先不用著急,后面會有實例演示。
另一個比較重要的類就是OpenerDirector,我們可以稱為Opener。我們之前用過urlopen()這個方法,實際上它就是urllib為我們提供的一個Opener。
那么,為什么要引入Opener呢?因為需要實現更高級的功能。之前使用的Request和urlopen()相當于類庫為你封裝好了極其常用的請求方法,利用它們可以完成基本的請求,但是現在不一樣了,我們需要實現更高級的功能,所以需要深入一層進行配置,使用更底層的實例來完成操作,所以這里就用到了Opener。
Opener可以使用open()方法,返回的類型和urlopen()如出一轍。那么,它和Handler有什么關系呢?簡而言之,就是利用Handler來構建Opener。
下面用幾個實例來看看它們的用法。
驗證
有些網站在打開時就會彈出提示框,直接提示你輸入用戶名和密碼,驗證成功后才能查看頁面,如圖3-2所示。
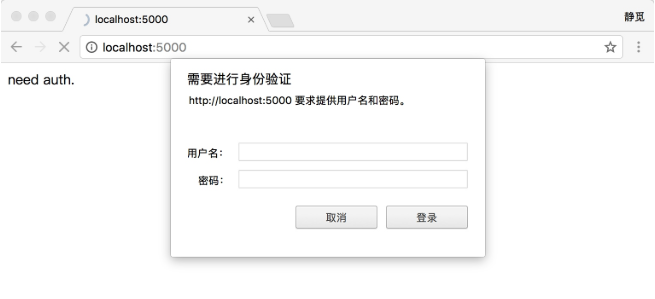
圖3-2 驗證頁面
那么,如果要請求這樣的頁面,該怎么辦呢?借助HTTPBasicAuthHandler就可以完成,相關代碼如下:
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = 'username'
password = 'password'
url = 'http://localhost:5000/'
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url, username, password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode('utf-8')
print(html)
except URLError as e:
print(e.reason)這里首先實例化HTTPBasicAuthHandler對象,其參數是HTTPPasswordMgrWithDefaultRealm對象,它利用add_password()添加進去用戶名和密碼,這樣就建立了一個處理驗證的Handler。
接下來,利用這個Handler并使用build_opener()方法構建一個Opener,這個Opener在發送請求時就相當于已經驗證成功了。
接下來,利用Opener的open()方法打開鏈接,就可以完成驗證了。這里獲取到的結果就是驗證后的頁面源碼內容。
代理
在做爬蟲的時候,免不了要使用代理,如果要添加代理,可以這樣做:
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
'http': 'http://127.0.0.1:9743',
'https': 'https://127.0.0.1:9743'
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)這里我們在本地搭建了一個代理,它運行在9743端口上。
這里使用了ProxyHandler,其參數是一個字典,鍵名是協議類型(比如HTTP或者HTTPS等),鍵值是代理鏈接,可以添加多個代理。
然后,利用這個Handler及build_opener()方法構造一個Opener,之后發送請求即可。
Cookies
Cookies的處理就需要相關的Handler了。
我們先用實例來看看怎樣將網站的Cookies獲取下來,相關代碼如下:
import http.cookiejar, urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+"="+item.value)首先,我們必須聲明一個CookieJar對象。接下來,就需要利用HTTPCookieProcessor來構建一個Handler,最后利用build_opener()方法構建出Opener,執行open()函數即可。
運行結果如下:
BAIDUID=2E65A683F8A8BA3DF521469DF8EFF1E1:FG=1 BIDUPSID=2E65A683F8A8BA3DF521469DF8EFF1E1 H_PS_PSSID=20987_1421_18282_17949_21122_17001_21227_21189_21161_20927 PSTM=1474900615 BDSVRTM=0 BD_HOME=0
可以看到,這里輸出了每條Cookie的名稱和值。
不過既然能輸出,那可不可以輸出成文件格式呢?我們知道Cookies實際上也是以文本形式保存的。
答案當然是肯定的,這里通過下面的實例來看看:
filename = 'cookies.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)這時CookieJar就需要換成MozillaCookieJar,它在生成文件時會用到,是CookieJar的子類,可以用來處理Cookies和文件相關的事件,比如讀取和保存Cookies,可以將Cookies保存成Mozilla型瀏覽器的Cookies格式。
運行之后,可以發現生成了一個cookies.txt文件,其內容如下:
# Netscape HTTP Cookie File # http://curl.haxx.se/rfc/cookie_spec.html # This is a generated file! Do not edit. .baidu.com TRUE / FALSE 3622386254 BAIDUID 05AE39B5F56C1DEC474325CDA5 22D44F:FG=1 .baidu.com TRUE / FALSE 3622386254 BIDUPSID 05AE39B5F56C1DEC474325CDA522D44F .baidu.com TRUE / FALSE H_PS_PSSID 19638_1453_17710_18240_21091_18560 _17001_21191_21161 .baidu.com TRUE / FALSE 3622386254 PSTM 1474902606 www.baidu.com FALSE / FALSE BDSVRTM 0 www.baidu.com FALSE / FALSE BD_HOME 0
另外,LWPCookieJar同樣可以讀取和保存Cookies,但是保存的格式和MozillaCookieJar不一樣,它會保存成libwww-perl(LWP)格式的Cookies文件。
要保存成LWP格式的Cookies文件,可以在聲明時就改為:
cookie = http.cookiejar.LWPCookieJar(filename)
此時生成的內容如下:
#LWP-Cookies-2.0 Set-Cookie3: BAIDUID="0CE9C56F598E69DB375B7C294AE5C591:FG=1"; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2084-10-14 18:25:19Z"; version=0 Set-Cookie3: BIDUPSID=0CE9C56F598E69DB375B7C294AE5C591; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2084-10-14 18:25:19Z"; version=0 Set-Cookie3: H_PS_PSSID=20048_1448_18240_17944_21089_21192_21161_20929; path="/"; domain=".baidu.com"; path_spec; domain_dot; discard; version=0 Set-Cookie3: PSTM=1474902671; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2084-10-14 18:25:19Z"; version=0 Set-Cookie3: BDSVRTM=0; path="/"; domain="www.baidu.com"; path_spec; discard; version=0 Set-Cookie3: BD_HOME=0; path="/"; domain="www.baidu.com"; path_spec; discard; version=0
由此看來,生成的格式還是有比較大差異的。
那么,生成了Cookies文件后,怎樣從文件中讀取并利用呢?
下面我們以LWPCookieJar格式為例來看一下:
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookies.txt', ignore_discard=True, ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))可以看到,這里調用load()方法來讀取本地的Cookies文件,獲取到了Cookies的內容。不過前提是我們首先生成了LWPCookieJar格式的Cookies,并保存成文件,然后讀取Cookies之后使用同樣的方法構建Handler和Opener即可完成操作。
運行結果正常的話,會輸出百度網頁的源代碼。
通過上面的方法,我們可以實現絕大多數請求功能的設置了。
看完上述內容,是不是對Python3爬蟲發送請求的方法有進一步的了解,如果還想學習更多內容,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





