溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“如何安裝Hadoop單機版和全分布式”,在日常操作中,相信很多人在如何安裝Hadoop單機版和全分布式問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”如何安裝Hadoop單機版和全分布式”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
Hadoop,分布式的大數據存儲和計算, 免費開源!有Linux基礎的同學安裝起來比較順風順水,寫幾個配置文件就可以啟動了,本人菜鳥,所以寫的比較詳細。為了方便,本人使用三臺的虛擬機系統是Ubuntu-12。設置虛擬機的網絡連接使用橋接方式,這樣在一個局域網方便調試。單機和集群安裝相差不多,先說單機然后補充集群的幾點配置。
第一步,先安裝工具軟件
編輯器:vim
代碼如下:
sudo apt-get install vim
ssh服務器: openssh,先安裝ssh是為了使用遠程終端工具(putty或xshell等),這樣管理虛擬機就方便多了。
代碼如下:
sudo apt-get install openssh-server
第二步,一些基本設置
最好給虛擬機設置固定IP
代碼如下:
sudo vim /etc/network/interfaces
加入以下內容:
iface eth0 inet static
address 192.168.0.211
gateway 192.168.0.222
netmask 255.255.255.0
修改機器名,我這里指定的名字是:hadoopmaster ,以后用它做namenode
代碼如下:
sudo vim /etc/hostname
修改hosts,方便應對IP變更,也方便記憶和識別
代碼如下:
sudo vim /etc/hosts
加入內容:
192.168.0.211 hadoopmaster
第三步,添加一個專門為hadoop使用的用戶
代碼如下:
sudo addgroup hadoop
sudo adduser -ingroup hadoop hadoop
設置hadoop用戶的sudo權限
代碼如下:
sudo vim /etc/sudoers
在 root ALL=(ALL:ALL)
下面加一行 hadoop ALL=(ALL:ALL)
切換到hadoop用戶 su hadoop
第四步,解壓安裝JDK,HADOOP,PIG(順便把PIG也安裝了)
代碼如下:
sudo tar zxvf ./jdk-7-linux-i586.tar.gz -C /usr/local/jvm/
sudo tar zxvf ./hadoop-1.0.4.tar.gz -C /usr/local/hadoop
sudo tar zxvf ./pig-0.11.1.tar.gz -C /usr/local/pig
修改解壓后的目錄名并且最終路徑為:
代碼如下:
jvm: /usr/local/jvm/jdk7
hadoop: /usr/local/hadoop/hadoop (注意:hadoop所有節點的安裝路徑必須相同)
pig: /usr/local/pig
設置目錄所屬用戶
代碼如下:
sudo chown -R hadoop:hadoop jdk7
sudo chown -R hadoop:hadoop hadoop
sudo chown -R hadoop:hadoop pig
設置環境變量, 編輯~/.bashrc 或 ~/.profile 文件加入
代碼如下:
export JAVA_HOME=/usr/local/jvm/jdk7
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_INSTALL=/usr/local/hadoop/hadoop
export PATH=${HADOOP_INSTALL}/bin:$PATH
source ~/.profile 生效
第五步,.ssh無密碼登錄本機,也就是說ssh到本機不需要密碼
代碼如下:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
如果不起作用請修改權限:
代碼如下:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
authorized_keys相當于白名單,id_rsa.pub是公鑰,凡是在authorized_keys有請求者機器的公鑰時ssh服務器直接放行,無需密碼!
第六步,Hadoop必要設置
所有設置文件在hadoop/conf目錄下
1、hadoop-env.sh 找到 #export JAVA_HOME 去掉注釋#,并設置實際jdk路徑
2、core-site.xml
代碼如下:
<property>
<name>fs.default.name</name>
<value>hdfs://hadoopmaster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
3、mapred-site.xml
代碼如下:
<property>
<name>mapred.job.tracker</name>
<value>hadoopmaster:9001</value>
</property>
4、hdfs-site.xml
代碼如下:
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/data1,/usr/local/hadoop/data2</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
5、文件masters 和 文件slaves, 單機寫 localhost 即可
第七步,啟動Hadoop
格式化Hadoop的HDFS文件系統
代碼如下:
hadoop namenode -format
執行Hadoop啟動腳本,如果是集群的話在master上執行,其他slave節點Hadoop會通過ssh執行:
代碼如下:
start-all.sh
執行命令 jps 如果顯示有: Namenode,SecondaryNameNode,TaskTracker,DataNode,JobTracker等五個進程表示啟動成功了!
第八步,集群的配置
所有其他單機的安裝跟上面相同,下面只增加集群的額外配置!
最好先配置好一臺單機,其他的可以通過scp直接復制,路徑也最好相同包括java!
本例的主機列表(設置hosts):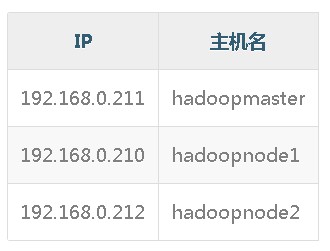
設置ssh,讓master能夠不要密碼登錄到其他slaves上,主要用來啟動slaves
代碼如下:
復制hadoopmaster下id_rsa.pub到子結點:
scp ./ssh/id_rsa.pub hadoopnode1:/home/hadoop/.ssh/id_master
scp ./ssh/id_rsa.pub hadoopnode2:/home/hadoop/.ssh/id_master
分別在子結點~/.ssh/目錄下執行:
cat ./id_master >> authorized_keys
masters文件,添加作為secondarynamenode或namenode的主機名,一行一個。
集群寫master名如:hadoopmaster
slaves文件,添加作為slave的主機名,一行一個。
集群寫子結點名:如 hadoopnode1、hadoopnode2
Hadoop管理
hadoop啟動后會啟動一個任務管理服務和一個文件系統管理服務,是兩個基于JETTY的WEB服務,所以可在線通過WEB的方式查看運行情況。
任務管理服務運行在50030端口,如 http://127.0.0.1:50030文件系統管理服務運行在50070端口。
參數說明:
1、dfs.name.dir:是NameNode持久存儲名字空間及事務日志的本地文件系統路徑。 當這個值是一個逗號分割的目錄列表時,nametable數據將會被復制到所有目錄中做冗余備份。
2、dfs.data.dir:是DataNode存放塊數據的本地文件系統路徑,逗號分割的列表。 當這個值是逗號分割的目錄列表時,數據將被存儲在所有目錄下,通常分布在不同設備上。
3、dfs.replication:是數據需要備份的數量,默認是3,如果此數大于集群的機器數會出錯。
到此,關于“如何安裝Hadoop單機版和全分布式”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





