溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了高性能Mysql主從架構的復制原理及配置示例,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
1 復制概述
Mysql內建的復制功能是構建大型,高性能應用程序的基礎。將Mysql的數據分布到多個系統上去,這種分布的機制,是通過將Mysql的某一臺主機的數據復制到其它主機(slaves)上,并重新執行一遍來實現的。復制過程中一個服務器充當主服務器,而一個或多個其它服務器充當從服務器。主服務器將更新寫入二進制日志文件,并維護文件的一個索引以跟蹤日志循環。這些日志可以記錄發送到從服務器的更新。當一個從服務器連接主服務器時,它通知主服務器從服務器在日志中讀取的最后一次成功更新的位置。從服務器接收從那時起發生的任何更新,然后封鎖并等待主服務器通知新的更新。
請注意當你進行復制時,所有對復制中的表的更新必須在主服務器上進行。否則,你必須要小心,以避免用戶對主服務器上的表進行的更新與對從服務器上的表所進行的更新之間的沖突。
1.1 mysql支持的復制類型:
(1):基于語句的復制: 在主服務器上執行的SQL語句,在從服務器上執行同樣的語句。MySQL默認采用基于語句的復制,效率比較高。
一旦發現沒法精確復制時, 會自動選著基于行的復制。
(2):基于行的復制:把改變的內容復制過去,而不是把命令在從服務器上執行一遍. 從mysql5.0開始支持
(3):混合類型的復制: 默認采用基于語句的復制,一旦發現基于語句的無法精確的復制時,就會采用基于行的復制。
1.2 . 復制解決的問題
MySQL復制技術有以下一些特點:
(1) 數據分布 (Data distribution )
(2) 負載平衡(load balancing)
(3) 備份(Backups)
(4) 高可用性和容錯行 High availability and failover
1.3 復制如何工作
整體上來說,復制有3個步驟:
(1) master將改變記錄到二進制日志(binary log)中(這些記錄叫做二進制日志事件,binary log events);
(2) slave將master的binary log events拷貝到它的中繼日志(relay log);
(3) slave重做中繼日志中的事件,將改變反映它自己的數據。
下圖描述了復制的過程:
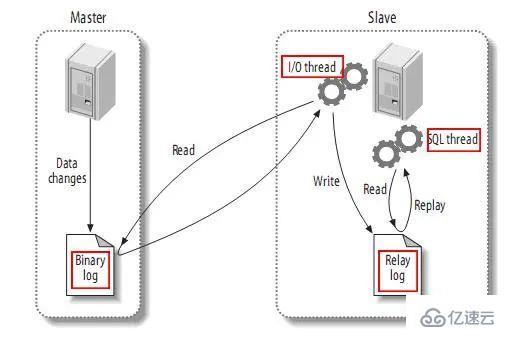
該過程的第一部分就是master記錄二進制日志。在每個事務更新數據完成之前,master在二日志記錄這些改變。MySQL將事務串行的寫入二進制日志,即使事務中的語句都是交叉執行的。在事件寫入二進制日志完成后,master通知存儲引擎提交事務。
下一步就是slave將master的binary log拷貝到它自己的中繼日志。首先,slave開始一個工作線程——I/O線程。I/O線程在master上打開一個普通的連接,然后開始binlog dump process。Binlog dump process從master的二進制日志中讀取事件,如果已經跟上master,它會睡眠并等待master產生新的事件。I/O線程將這些事件寫入中繼日志。
SQL slave thread(SQL從線程)處理該過程的最后一步。SQL線程從中繼日志讀取事件,并重放其中的事件而更新slave的數據,使其與master中的數據一致。只要該線程與I/O線程保持一致,中繼日志通常會位于OS的緩存中,所以中繼日志的開銷很小。
此外,在master中也有一個工作線程:和其它MySQL的連接一樣,slave在master中打開一個連接也會使得master開始一個線程。復制過程有一個很重要的限制——復制在slave上是串行化的,也就是說master上的并行更新操作不能在slave上并行操作。
2 .主從復制配置
有兩臺MySQL數據庫服務器Master和slave,Master為主服務器,slave為從服務器,初始狀態時,Master和slave中的數據信息相同,當Master中的數據發生變化時,slave也跟著發生相應的變化,使得master和slave的數據信息同步,達到備份的目的。
要點:
負責在主、從服務器傳輸各種修改動作的媒介是主服務器的二進制變更日志,這個日志記載著需要傳輸給從服務器的各種修改動作。因此,主服務器必須激活二進制日志功能。從服務器必須具備足以讓它連接主服務器并請求主服務器把二進制變更日志傳輸給它的權限。
環境:
Master和slave的MySQL數據庫版本同為5.0.18
IP地址:10.100.0.100
2.1、創建復制帳號
1、在Master的數據庫中建立一個備份帳戶:每個slave使用標準的MySQL用戶名和密碼連接master。進行復制操作的用戶會授予REPLICATION SLAVE權限。用戶名的密碼都會存儲在文本文件master.info中
命令如下:
mysql > GRANT REPLICATION SLAVE,RELOAD,SUPER ON *.* TO backup@’10.100.0.200’ IDENTIFIED BY ‘1234’;
建立一個帳戶backup,并且只能允許從10.100.0.200這個地址上來登陸,密碼是1234。
(如果因為mysql版本新舊密碼算法不同,可以設置:set password for 'backup'@'10.100.0.200'=old_password('1234'))
2.2、拷貝數據
(假如是你完全新安裝mysql主從服務器,這個一步就不需要。因為新安裝的master和slave有相同的數據)
關停Master服務器,將Master中的數據拷貝到B服務器中,使得Master和slave中的數據同步,并且確保在全部設置操作結束前,禁止在Master和slave服務器中進行寫操作,使得兩數據庫中的數據一定要相同!
2.3、配置master
接下來對master進行配置,包括打開二進制日志,指定唯一的servr ID。例如,在配置文件加入如下值:
server-id=1log-bin=mysql-binserver-id:為主服務器A的ID值log-bin:二進制變更日值
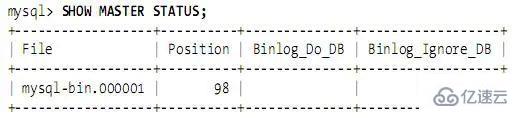
重啟master,運行SHOW MASTER STATUS,輸出如下:
2.4、配置slave
Slave的配置與master類似,你同樣需要重啟slave的MySQL。如下:
log_bin = mysql-binserver_id = 2relay_log = mysql-relay-binlog_slave_updates = 1read_only = 1
server_id:是必須的,而且唯一。
log_bin:slave沒有必要開啟二進制日志bin_log,但是在一些情況下,必須設置,例如,如果slave為其它slave的master,必須設置bin_log。在這里,我們開啟了二進制日志,而且顯示的命名(默認名稱為hostname,但是,如果hostname改變則會出現問題)。
relay_log:配置中繼日志,log_slave_updates表示slave將復制事件寫進自己的二進制日志(后面會看到它的用處)。
有些人開啟了slave的二進制日志,卻沒有設置log_slave_updates,然后查看slave的數據是否改變,這是一種錯誤的配置。
read_only:盡量使用read_only,它防止改變數據(除了特殊的線程)。但是,read_only并是很實用,特別是那些需要在slave上創建表的應用。
2.5、啟動slave
接下來就是讓slave連接master,并開始重做master二進制日志中的事件。你不應該用配置文件進行該操作,而應該使用CHANGE MASTER TO語句,該語句可以完全取代對配置文件的修改,而且它可以為slave指定不同的master,而不需要停止服務器。如下:
mysql> CHANGE MASTER TO MASTER_HOST='server1', -> MASTER_USER='repl', -> MASTER_PASSWORD='p4ssword', -> MASTER_LOG_FILE='mysql-bin.000001', -> MASTER_LOG_POS=0;
MASTER_LOG_POS的值為0,因為它是日志的開始位置。
你可以用SHOW SLAVE STATUS語句查看slave的設置是否正確:
mysql> SHOW SLAVE STATUS\G*************************** 1. row *************************** Slave_IO_State: Master_Host: server1 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 4 Relay_Log_File: mysql-relay-bin.000001 Relay_Log_Pos: 4 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: No Slave_SQL_Running: No ...omitted... Seconds_Behind_Master: NULLSlave_IO_State, Slave_IO_Running, 和Slave_SQL_Running是No
表明slave還沒有開始復制過程。日志的位置為4而不是0,這是因為0只是日志文件的開始位置,并不是日志位置。實際上,MySQL知道的第一個事件的位置是4。
為了開始復制,你可以運行:
mysql> START SLAVE;運行SHOW SLAVE STATUS查看輸出結果:mysql> SHOW SLAVE STATUS\G*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: server1 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 164 Relay_Log_File: mysql-relay-bin.000001 Relay_Log_Pos: 164 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes ...omitted... Seconds_Behind_Master: 0
在這里主要是看:
Slave_IO_Running=Yes Slave_SQL_Running=Yes
slave的I/O和SQL線程都已經開始運行,而且Seconds_Behind_Master不再是NULL。日志的位置增加了,意味著一些事件被獲取并執行了。如果你在master上進行修改,你可以在slave上看到各種日志文件的位置的變化,同樣,你也可以看到數據庫中數據的變化。
你可查看master和slave上線程的狀態。在master上,你可以看到slave的I/O線程創建的連接:
在master上輸入show processlist\G;
mysql> show processlist \G *************************** 1. row *************************** Id: 1 User: root Host: localhost:2096 db: test Command: Query Time: 0 State: NULL Info: show processlist *************************** 2. row *************************** Id: 2 User: repl Host: localhost:2144 db: NULL Command: Binlog Dump Time: 1838 State: Has sent all binlog to slave; waiting for binlog to be updated Info: NULL 2 rows in set (0.00 sec) |
行2為處理slave的I/O線程的連接。
在slave服務器上運行該語句:
mysql> show processlist \G *************************** 1. row *************************** Id: 1 User: system user Host: db: NULL Command: Connect Time: 2291 State: Waiting for master to send event Info: NULL *************************** 2. row *************************** Id: 2 User: system user Host: db: NULL Command: Connect Time: 1852 State: Has read all relay log; waiting for the slave I/O thread to update it Info: NULL *************************** 3. row *************************** Id: 5 User: root Host: localhost:2152 db: test Command: Query Time: 0 State: NULL Info: show processlist 3 rows in set (0.00 sec) |
行1為I/O線程狀態,行2為SQL線程狀態。
2.5、添加新slave服務器
假如master已經運行很久了,想對新安裝的slave進行數據同步,甚至它沒有master的數據。
此時,有幾種方法可以使slave從另一個服務開始,例如,從master拷貝數據,從另一個slave克隆,從最近的備份開始一個slave。Slave與master同步時,需要三樣東西:
(1)master的某個時刻的數據快照;
(2)master當前的日志文件、以及生成快照時的字節偏移。這兩個值可以叫做日志文件坐標(log file coordinate),因為它們確定了一個二進制日志的位置,你可以用SHOW MASTER STATUS命令找到日志文件的坐標;
(3)master的二進制日志文件。
可以通過以下幾中方法來克隆一個slave:
(1) 冷拷貝(cold copy)
停止master,將master的文件拷貝到slave;然后重啟master。缺點很明顯。
(2) 熱拷貝(warm copy)
如果你僅使用MyISAM表,你可以使用mysqlhotcopy拷貝,即使服務器正在運行。
(3) 使用mysqldump
使用mysqldump來得到一個數據快照可分為以下幾步:
<1>鎖表:如果你還沒有鎖表,你應該對表加鎖,防止其它連接修改數據庫,否則,你得到的數據可以是不一致的。如下:
mysql> FLUSH TABLES WITH READ LOCK;
<2>在另一個連接用mysqldump創建一個你想進行復制的數據庫的轉儲:
shell> mysqldump --all-databases --lock-all-tables >dbdump.db
<3>對表釋放鎖。
mysql> UNLOCK TABLES;
3、深入了解復制
已經討論了關于復制的一些基本東西,下面深入討論一下復制。
3.1、基于語句的復制(Statement-Based Replication)
MySQL 5.0及之前的版本僅支持基于語句的復制(也叫做邏輯復制,logical replication),這在數據庫并不常見。master記錄下改變數據的查詢,然后,slave從中繼日志中讀取事件,并執行它,這些SQL語句與master執行的語句一樣。
這種方式的優點就是實現簡單。此外,基于語句的復制的二進制日志可以很好的進行壓縮,而且日志的數據量也較小,占用帶寬少——例如,一個更新GB的數據的查詢僅需要幾十個字節的二進制日志。而mysqlbinlog對于基于語句的日志處理十分方便。
但是,基于語句的復制并不是像它看起來那么簡單,因為一些查詢語句依賴于master的特定條件,例如,master與slave可能有不同的時間。所以,MySQL的二進制日志的格式不僅僅是查詢語句,還包括一些元數據信息,例如,當前的時間戳。即使如此,還是有一些語句,比如,CURRENT USER函數,不能正確的進行復制。此外,存儲過程和觸發器也是一個問題。
另外一個問題就是基于語句的復制必須是串行化的。這要求大量特殊的代碼,配置,例如InnoDB的next-key鎖等。并不是所有的存儲引擎都支持基于語句的復制。
3.2、基于記錄的復制(Row-Based Replication)
MySQL增加基于記錄的復制,在二進制日志中記錄下實際數據的改變,這與其它一些DBMS的實現方式類似。這種方式有優點,也有缺點。優點就是可以對任何語句都能正確工作,一些語句的效率更高。主要的缺點就是二進制日志可能會很大,而且不直觀,所以,你不能使用mysqlbinlog來查看二進制日志。
對于一些語句,基于記錄的復制能夠更有效的工作,如:
mysql> INSERT INTO summary_table(col1, col2, sum_col3) -> SELECT col1, col2, sum(col3) -> FROM enormous_table -> GROUP BY col1, col2;
假設,只有三種唯一的col1和col2的組合,但是,該查詢會掃描原表的許多行,卻僅返回三條記錄。此時,基于記錄的復制效率更高。
另一方面,下面的語句,基于語句的復制更有效:
mysql> UPDATE enormous_table SET col1 = 0;
此時使用基于記錄的復制代價會非常高。由于兩種方式不能對所有情況都能很好的處理,所以,MySQL 5.1支持在基于語句的復制和基于記錄的復制之前動態交換。你可以通過設置session變量binlog_format來進行控制。
3.3、復制相關的文件
除了二進制日志和中繼日志文件外,還有其它一些與復制相關的文件。如下:
(1)mysql-bin.index
服務器一旦開啟二進制日志,會產生一個與二日志文件同名,但是以.index結尾的文件。它用于跟蹤磁盤上存在哪些二進制日志文件。MySQL用它來定位二進制日志文件。它的內容如下(我的機器上):
(2)mysql-relay-bin.index
該文件的功能與mysql-bin.index類似,但是它是針對中繼日志,而不是二進制日志。內容如下:
.\mysql-02-relay-bin.000017
.\mysql-02-relay-bin.000018
(3)master.info
保存master的相關信息。不要刪除它,否則,slave重啟后不能連接master。內容如下(我的機器上):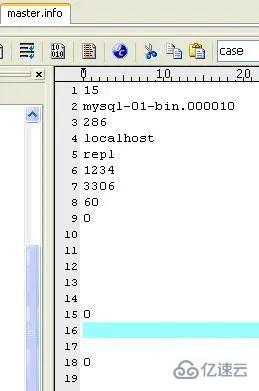
I/O線程更新master.info文件,內容如下(我的機器上):
.\mysql-02-relay-bin.000019 254 mysql-01-bin.000010 286 0 52813 |
(4)relay-log.info
包含slave中當前二進制日志和中繼日志的信息。
3.4、發送復制事件到其它slave
當設置log_slave_updates時,你可以讓slave扮演其它slave的master。此時,slave把SQL線程執行的事件寫進行自己的二進制日志(binary log),然后,它的slave可以獲取這些事件并執行它。如下: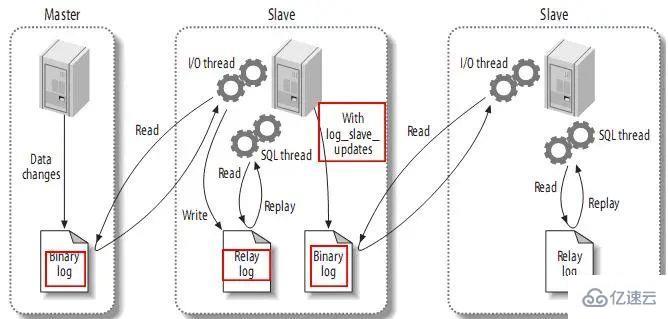
復制過濾可以讓你只復制服務器中的一部分數據,有兩種復制過濾:在master上過濾二進制日志中的事件;在slave上過濾中繼日志中的事件。如下:
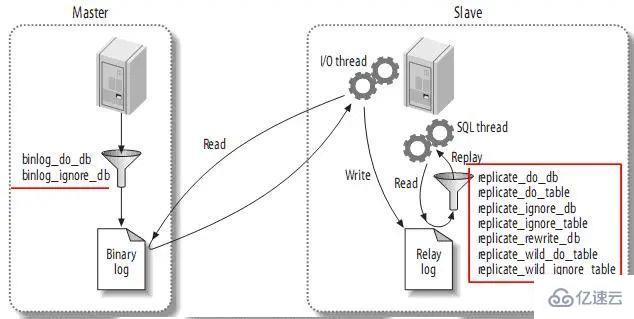
4、復制的常用拓撲結構
復制的體系結構有以下一些基本原則:
(1) 每個slave只能有一個master;
(2) 每個slave只能有一個唯一的服務器ID;
(3) 每個master可以有很多slave;
(4) 如果你設置log_slave_updates,slave可以是其它slave的master,從而擴散master的更新。
MySQL不支持多主服務器復制(Multimaster Replication)——即一個slave可以有多個master。但是,通過一些簡單的組合,我們卻可以建立靈活而強大的復制體系結構。
由一個master和一個slave組成復制系統是最簡單的情況。Slave之間并不相互通信,只能與master進行通信。
在實際應用場景中,MySQL復制90%以上都是一個Master復制到一個或者多個Slave的架構模式,主要用于讀壓力比較大的應用的數據庫端廉價擴展解決方案。因為只要Master和Slave的壓力不是太大(尤其是Slave端壓力)的話,異步復制的延時一般都很少很少。尤其是自從Slave端的復制方式改成兩個線程處理之后,更是減小了Slave端的延時問題。而帶來的效益是,對于數據實時性要求不是特別Critical的應用,只需要通過廉價的pcserver來擴展Slave的數量,將讀壓力分散到多臺Slave的機器上面,即可通過分散單臺數據庫服務器的讀壓力來解決數據庫端的讀性能瓶頸,畢竟在大多數數據庫應用系統中的讀壓力還是要比寫壓力大很多。這在很大程度上解決了目前很多中小型網站的數據庫壓力瓶頸問題,甚至有些大型網站也在使用類似方案解決數據庫瓶頸。
如下: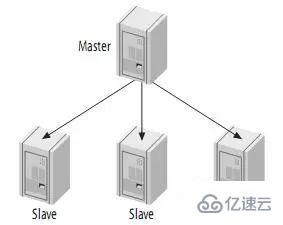
如果寫操作較少,而讀操作很時,可以采取這種結構。你可以將讀操作分布到其它的slave,從而減小master的壓力。但是,當slave增加到一定數量時,slave對master的負載以及網絡帶寬都會成為一個嚴重的問題。
這種結構雖然簡單,但是,它卻非常靈活,足夠滿足大多數應用需求。一些建議:
(1) 不同的slave扮演不同的作用(例如使用不同的索引,或者不同的存儲引擎);
(2) 用一個slave作為備用master,只進行復制;
(3) 用一個遠程的slave,用于災難恢復;
大家應該都比較清楚,從一個Master節點可以復制出多個Slave節點,可能有人會想,那一個Slave節點是否可以從多個Master節點上面進行復制呢?至少在目前來看,MySQL是做不到的,以后是否會支持就不清楚了。
MySQL不支持一個Slave節點從多個Master節點來進行復制的架構,主要是為了避免沖突的問題,防止多個數據源之間的數據出現沖突,而造成最后數據的不一致性。不過聽說已經有人開發了相關的patch,讓MySQL支持一個Slave節點從多個Master結點作為數據源來進行復制,這也正是MySQL開源的性質所帶來的好處。
Master-Master復制的兩臺服務器,既是master,又是另一臺服務器的slave。這樣,任何一方所做的變更,都會通過復制應用到另外一方的數據庫中。
可能有些讀者朋友會有一個擔心,這樣搭建復制環境之后,難道不會造成兩臺MySQL之間的循環復制么?實際上MySQL自己早就想到了這一點,所以在MySQL的BinaryLog中記錄了當前MySQL的server-id,而且這個參數也是我們搭建MySQLReplication的時候必須明確指定,而且Master和Slave的server-id參數值比需要不一致才能使MySQLReplication搭建成功。一旦有了server-id的值之后,MySQL就很容易判斷某個變更是從哪一個MySQLServer最初產生的,所以就很容易避免出現循環復制的情況。而且,如果我們不打開記錄Slave的BinaryLog的選項(--log-slave-update)的時候,MySQL根本就不會記錄復制過程中的變更到BinaryLog中,就更不用擔心可能會出現循環復制的情形了。
如圖: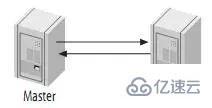
主動的Master-Master復制有一些特殊的用處。例如,地理上分布的兩個部分都需要自己的可寫的數據副本。這種結構最大的問題就是更新沖突。假設一個表只有一行(一列)的數據,其值為1,如果兩個服務器分別同時執行如下語句:
在第一個服務器上執行:
mysql> UPDATE tbl SET col=col + 1;
在第二個服務器上執行:
mysql> UPDATE tbl SET col=col * 2;
那么結果是多少呢?一臺服務器是4,另一個服務器是3,但是,這并不會產生錯誤。
實際上,MySQL并不支持其它一些DBMS支持的多主服務器復制(Multimaster Replication),這是MySQL的復制功能很大的一個限制(多主服務器的難點在于解決更新沖突),但是,如果你實在有這種需求,你可以采用MySQL Cluster,以及將Cluster和Replication結合起來,可以建立強大的高性能的數據庫平臺。但是,可以通過其它一些方式來模擬這種多主服務器的復制。
4.3、主動-被動模式的Master-Master(Master-Master in Active-Passive Mode)
這是master-master結構變化而來的,它避免了M-M的缺點,實際上,這是一種具有容錯和高可用性的系統。它的不同點在于其中一個服務只能進行只讀操作。如圖: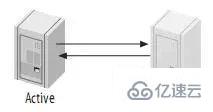
4.4 級聯復制架構 Master –Slaves - Slaves
在有些應用場景中,可能讀寫壓力差別比較大,讀壓力特別的大,一個Master可能需要上10臺甚至更多的Slave才能夠支撐注讀的壓力。這時候,Master就會比較吃力了,因為僅僅連上來的SlaveIO線程就比較多了,這樣寫的壓力稍微大一點的時候,Master端因為復制就會消耗較多的資源,很容易造成復制的延時。
遇到這種情況如何解決呢?這時候我們就可以利用MySQL可以在Slave端記錄復制所產生變更的BinaryLog信息的功能,也就是打開—log-slave-update選項。然后,通過二級(或者是更多級別)復制來減少Master端因為復制所帶來的壓力。也就是說,我們首先通過少數幾臺MySQL從Master來進行復制,這幾臺機器我們姑且稱之為第一級Slave集群,然后其他的Slave再從第一級Slave集群來進行復制。從第一級Slave進行復制的Slave,我稱之為第二級Slave集群。如果有需要,我們可以繼續往下增加更多層次的復制。這樣,我們很容易就控制了每一臺MySQL上面所附屬Slave的數量。這種架構我稱之為Master-Slaves-Slaves架構
這種多層級聯復制的架構,很容易就解決了Master端因為附屬Slave太多而成為瓶頸的風險。下圖展示了多層級聯復制的Replication架構。

當然,如果條件允許,我更傾向于建議大家通過拆分成多個Replication集群來解決
上述瓶頸問題。畢竟Slave并沒有減少寫的量,所有Slave實際上仍然還是應用了所有的數據變更操作,沒有減少任何寫IO。相反,Slave越多,整個集群的寫IO總量也就會越多,我們沒有非常明顯的感覺,僅僅只是因為分散到了多臺機器上面,所以不是很容易表現出來。
此外,增加復制的級聯層次,同一個變更傳到最底層的Slave所需要經過的MySQL也會更多,同樣可能造成延時較長的風險。
而如果我們通過分拆集群的方式來解決的話,可能就會要好很多了,當然,分拆集群也需要更復雜的技術和更復雜的應用系統架構。
4.5、帶從服務器的Master-Master結構(Master-Master with Slaves)
這種結構的優點就是提供了冗余。在地理上分布的復制結構,它不存在單一節點故障問題,而且還可以將讀密集型的請求放到slave上。
級聯復制在一定程度上面確實解決了Master因為所附屬的Slave過多而成為瓶頸的問題,但是他并不能解決人工維護和出現異常需要切換后可能存在重新搭建Replication的問題。這樣就很自然的引申出了DualMaster與級聯復制結合的Replication架構,我稱之為Master-Master-Slaves架構
和Master-Slaves-Slaves架構相比,區別僅僅只是將第一級Slave集群換成了一臺單獨的Master,作為備用Master,然后再從這個備用的Master進行復制到一個Slave集群。
這種DualMaster與級聯復制結合的架構,最大的好處就是既可以避免主Master的寫入操作不會受到Slave集群的復制所帶來的影響,同時主Master需要切換的時候也基本上不會出現重搭Replication的情況。但是,這個架構也有一個弊端,那就是備用的Master有可能成為瓶頸,因為如果后面的Slave集群比較大的話,備用Master可能會因為過多的SlaveIO線程請求而成為瓶頸。當然,該備用Master不提供任何的讀服務的時候,瓶頸出現的可能性并不是特別高,如果出現瓶頸,也可以在備用Master后面再次進行級聯復制,架設多層Slave集群。當然,級聯復制的級別越多,Slave集群可能出現的數據延時也會更為明顯,所以考慮使用多層級聯復制之前,也需要評估數據延時對應用系統的影響。
5、復制的常見問題
錯誤一:change master導致的:
Last_IO_Error: error connecting to master 'repl1@IP:3306' - retry-time: 60 retries
錯誤二:在沒有解鎖的情況下停止slave進程:
mysql> stop slave;
ERROR 1192 (HY000): Can't execute the given command because you have active locked tables or an active transaction
錯誤三:在沒有停止slave進程的情況下change master
mysql> change master to master_host=‘IP', master_user='USER', master_password='PASSWD', master_log_file='mysql-bin.000001',master_log_pos=106;
ERROR 1198 (HY000): This operation cannot be performed with a running slave; run STOP SLAVE first
錯誤四:A B的server-id相同:
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids;
these ids must be different for replication to work (or the --replicate-same-server-id option must be used on
slave but this does not always make sense; please check the manual before using it).
查看server-id
mysql> show variables like 'server_id';
手動修改server-id
mysql> set global server_id=2; #此處的數值和my.cnf里設置的一樣就行
mysql> slave start;
錯誤五:change master之后,查看slave的狀態,發現slave_IO_running 仍為NO
需要注意的是,上述幾個錯誤做完操作之后要重啟mysql進程,slave_IO_running 變為Yes
錯誤六:MySQL主從同步異常Client requested master to start replication from position > file size
字面理解:從庫的讀取binlog的位置大于主庫當前binglog的值
這一般是主庫重啟導致的問題,主庫從參數sync_binlog默認為1000,即主庫的數據是先緩存到1000條后統一fsync到磁盤的binlog文件中。

當主庫重啟的時候,從庫直接讀取主庫接著之前的位點重新拉binlog,但是主庫由于沒有fsync最后的binlog,所以會返回1236 的錯誤。
正常建議配置sync_binlog=1 也就是每個事務都立即寫入到binlog文件中。
1、在從庫檢查slave狀態:
偏移量為4063315
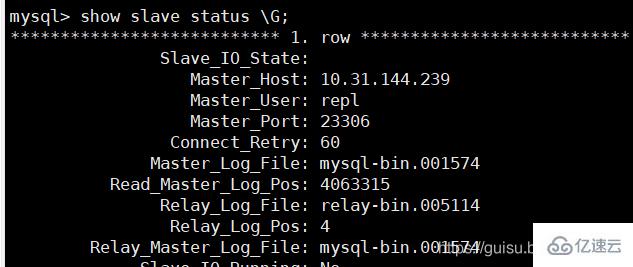
2、在主庫檢查mysql-bin.001574的偏移量位置
mysqlbinlog mysql-bin.001574 > ./mysql-bin.001574.bak
tail -10 ./mysql-bin.001574.bak
mysql-bin.001574文件最后幾行 發現最后偏移量是4059237,從庫偏移量的4063315遠大主庫的偏移量4059237,也就是參數sync_binlog=1000導致的。
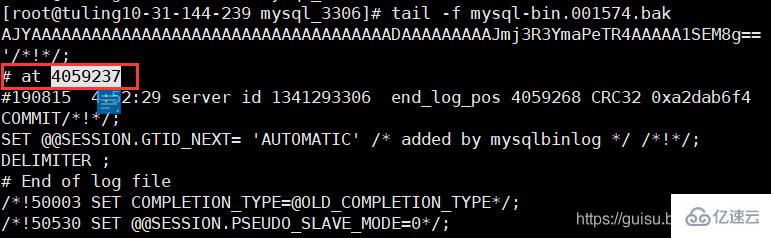
3、重新設置salve
mysql> stop slave;mysql> change master to master_log_file='mysql-bin.001574' ,master_log_pos=4059237;mysql> start slave;
錯誤8:數據同步異常情況
第一種:在master上刪除一條記錄,而slave上找不到。
Last_Error: Could not execute Delete_rows event on table market_edu.tl_player_task; Can't find record in 'tl_player_task', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.002094, end_log_pos 286434186
解決方法:由于master要刪除一條記錄,而slave上找不到故報錯,這種情況主上都將其刪除了,那么從機可以直接跳過。
可用命令:stop slave; set global sql_slave_skip_counter=1; start slave;
第二種:主鍵重復。在slave已經有該記錄,又在master上插入了同一條記錄。
Last_SQL_Error: Could not execute Write_rows event on table hcy.t1;
Duplicate entry '2' for key 'PRIMARY',
Error_code: 1062;
handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysql-bin.000006, end_log_pos 924
解決方法:在slave刪除重復的主鍵
第三種:在master上更新一條記錄,而slave上找不到,丟失了數據。
Last_SQL_Error: Could not execute Update_rows event on table hcy.t1;
Can't find record in 't1',
Error_code: 1032;
handler error HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.000010, end_log_pos 263
解決方法:把丟失的數據在slave上填補,然后跳過報錯即可。
insert into t1 values (2,'BTV');
stop slave ;set global sql_slave_skip_counter=1;start slave;
感謝你能夠認真閱讀完這篇文章,希望小編分享的“高性能Mysql主從架構的復制原理及配置示例”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





