溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

在過去的一年里DataPipeline經歷了幾次產品迭代。就最新的2.6版本而言,你知道都有哪些使用場景嗎?接下來將分為上下篇為大家一 一解讀,希望這些場景中能出現你關心的那一款。
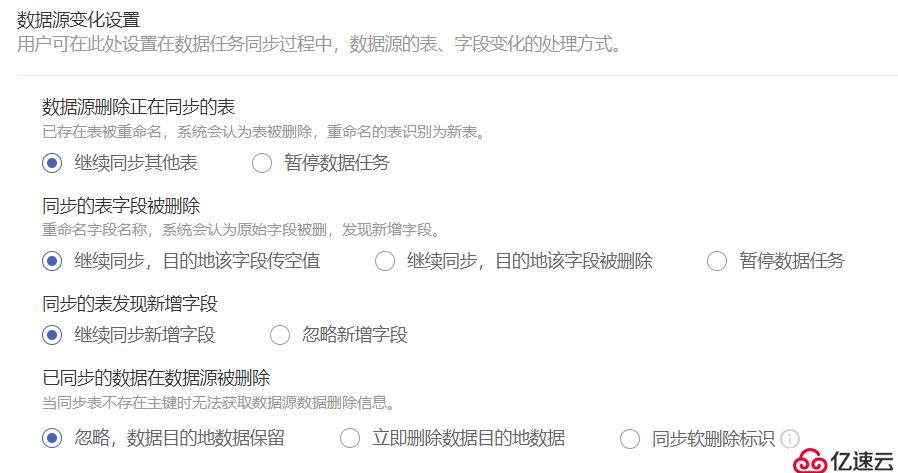
場景一:應對生產數據結構的頻繁變更場景
在同步生產數據時,因為業務關系,源端經常會有刪除表,增減字段情況。希望在該情況下任務可以繼續同步。并且當源端增減字段時,目的地可以根據設置選擇是否同源端一起增減字段。
源/目的地:關系型數據庫
讀取模式:不限制
不限制DataPipeline版本
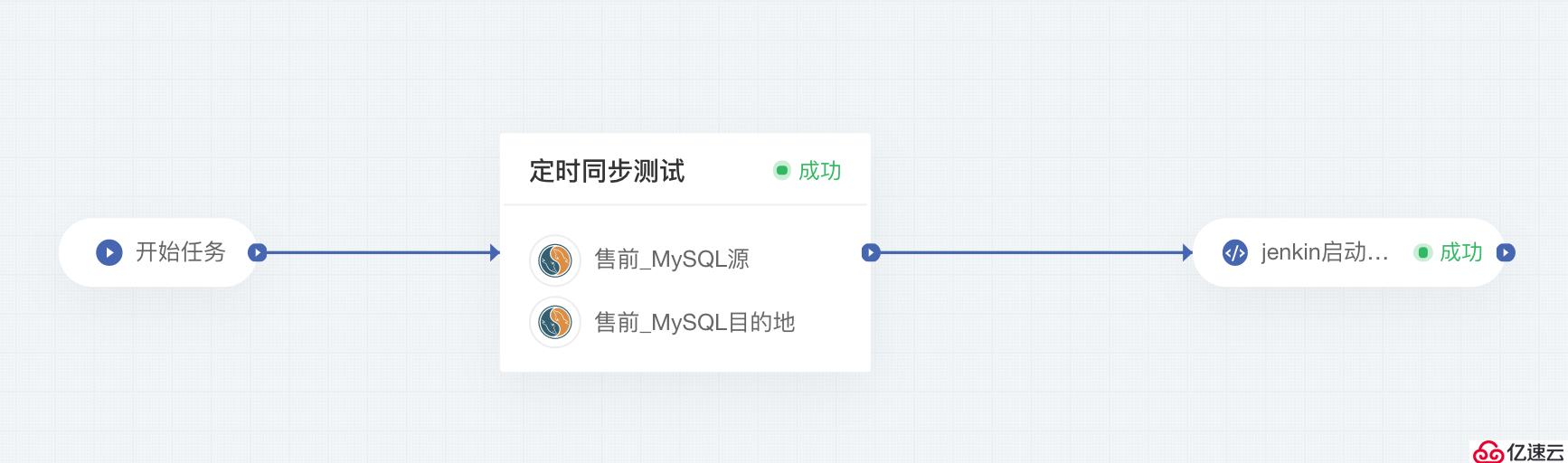
場景二:數據任務結束后調用Jenkins任務
數據任務同步結束,立即啟動已定義的Jenkins任務。保證執行的順序性,以及依賴性。
源/目的地:傳統性數據庫(其它需要腳本)
讀取模式:批量全量或增量識別字段
在DataPipeline任務流中創建任務流
創建定時數據同步任務
詳細操作細節請與DataPipeline人員溝通
場景三:生產數據同步給測試使用
MySQL->MySQL實時同步,在同步時,可能測試組想要對任務中的幾張表目的地進行測試,在測試過程中,目的地會有INSERT/UPDATE/DELETE操作。希望在測試前,能以自動化方式執行腳本暫停某幾張表的同步。測試結束后以自動化方式執行腳本重新同步這幾張表,并且目的地數據需要與線上數據保持一致(即測試所產生的臟數據需要被全部清理掉)。
源/目的地:關系型數據庫目的地
讀取模式:不限制(全量/增量識別字段模式可能需要開啟【每次定時執行批量同步前,允許清除目標表數據】功能)
要求DataPipeline版本>=2.6.0
在對目的地表進行測試前,執行DataPipeline所提供的腳本
目的地結束測試后,再執行腳本添加測試表
啟動腳本,對測試的幾張表進行重新同步,保證測試后的數據可以和線上數據繼續保持一致
場景四:Hive->GP列存儲同步速率提高方案
Hive->GP,如果GP目的地表為手動創建的列存儲表,那么在DataPipeline上同步時速率會非常慢。這是因為GP列存儲本身存在的限制。而目的地若為DataPipeline創建的行表,再通過腳本將行表轉換為列表,則效率提高幾十倍。
源/目的地:Hive源/GP目的地
讀取模式:增量/全量
目的地表為DataPipeline自動創建的行表
編寫腳本將行表轉換為列表
數據任務同步完成后,通過DataPipeline任務流調用行轉列腳本
場景五:對數據進行加密脫敏處理場景
因為涉及用戶隱私或其它安全原因,需要對數據部分字段進行脫敏或加密處理。通過DataPipeline的高級清洗功能可以完全滿足此類場景。
源/目的地:不限制
讀取模式:不限制
不限制DataPipeline版本
正常配置任務即可,只需開啟高級清洗功能
將已寫好的加密代碼或脫敏代碼打成jar包,上傳到服務器執行目錄下,直接調用即可
注意事項:所寫的jar包需要分別上傳webservice、sink、manager所在容器的服務器的/root/datapipeline/code_engine_lib(一般默認)目錄。
場景六:通過錯誤隊列,明確上下游數據問題責任及原因
作為數據部門,需要接收上游數據,并根據下游部門需求將數據傳輸給對應部門。因此當存在臟數據或者數據問題時,有時很難定位問題原因,劃分責任。
并且大多時候都是將臟數據直接丟棄,上游無法追蹤臟數據產生的原因。通過DP的高級清洗功能可自定義將不符合的數據放入錯誤隊列中。
源/目的地:不限制
讀取模式:不限制
不限制DataPipeline版本
正常配置任務即可,只需開啟高級清洗功能
高級清洗代碼可聯系DataPipeline提供模板
場景七:更便捷地支持目的地手動增加字段
由Oracle->SQLServer,想在目的地手動添加一列TIMESTAMP類型,自動賦予默認值,記錄數據INSERT時間。
源/目的地:關系型數據庫目的地
讀取模式:不限制
要求DataPipeline版本>=2.6.0
在DataPipeline映射頁面配置時,添加一列,字段名稱和目的地手動添加名稱一致(標度類型任意給,無需一致)

本篇將集中介紹以上7種場景,如果你在工作中遇到了同樣的問題,歡迎與我們交流。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





