溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

A公司專注為各種規模和復雜程度的金融投資機構提供一體化投資管理系統,系統主要由投資組合管理、交易執行管理、實時監控管理、風險管理等功能模塊構成。隨著企業管理產品數量的不斷增多,大量數據分散在各券商系統中且數據存儲格式各異,難以管理和利用。
為幫助投資機構最大限度地提高投資決策和運營效率,A公司需要實時監控自己的用戶在各個交易平臺的基本信息、余額、訂單交易情況,并根據分析結果及時給出投資建議。
A公司的這種情況并不是個例。目前,越來越多的企業在數據傳輸的需求場景中,除了從上游不同業務數據庫中實時、定時分配到下游系統之外,還有許多需求場景需要從外部合作商、供應商中獲取業務數據。
如果想要每天從企業外部系統中獲取數據,通常會采用什么方法呢?
一些用戶給出的答案是:根據需要編寫不同的腳本,手動調用第三方系統提供的API接口,在抓取數據后,自行編寫清洗邏輯,最后實現數據落地。
然而隨著第三方系統的日益增多,如果按原有方式會帶來過多的腳本維護成本和數據傳輸任務管理成本。為解決上述痛點,DataPipeline在新版本的數據同步任務中增加了「自定義數據源」功能,用戶可以通過上傳JAR包的方式自定義獲取數據邏輯。新功能支持任意的MySQL、Oracle、SQLServer、Hive、HBase等常見數據源,冷門數據庫等(如騰訊云TDSQL),常用的API調用,用戶自定義的SDK,或者通過Python抓取數據等。
一、「自定義數據源」提供的價值
1 通過「自定義數據源」,用戶可以:
統一管理數據獲取邏輯,快速合并JAR減少腳本開發量。
當上游發生變化時,不需要對每一個數據傳輸任務進行調整。
2 如何使用「自定義數據源」功能
用戶可通過以下四步使用「自定義數據源」功能:
創建自定義數據源,并上傳JAR包(或調取已上傳過的JAR包)。
選擇數據存放的目的地。
使用清洗工具完成數據解析邏輯。
3 關于「自定義數據源」的核心頁面:
(1)用戶在選擇自定義數據源和目的地后,需要在讀取設置步驟中上傳JAR包
用戶可以上傳新的JAR包,也可以點擊拖放框選擇歷史已經上傳的JAR用作本次任務。
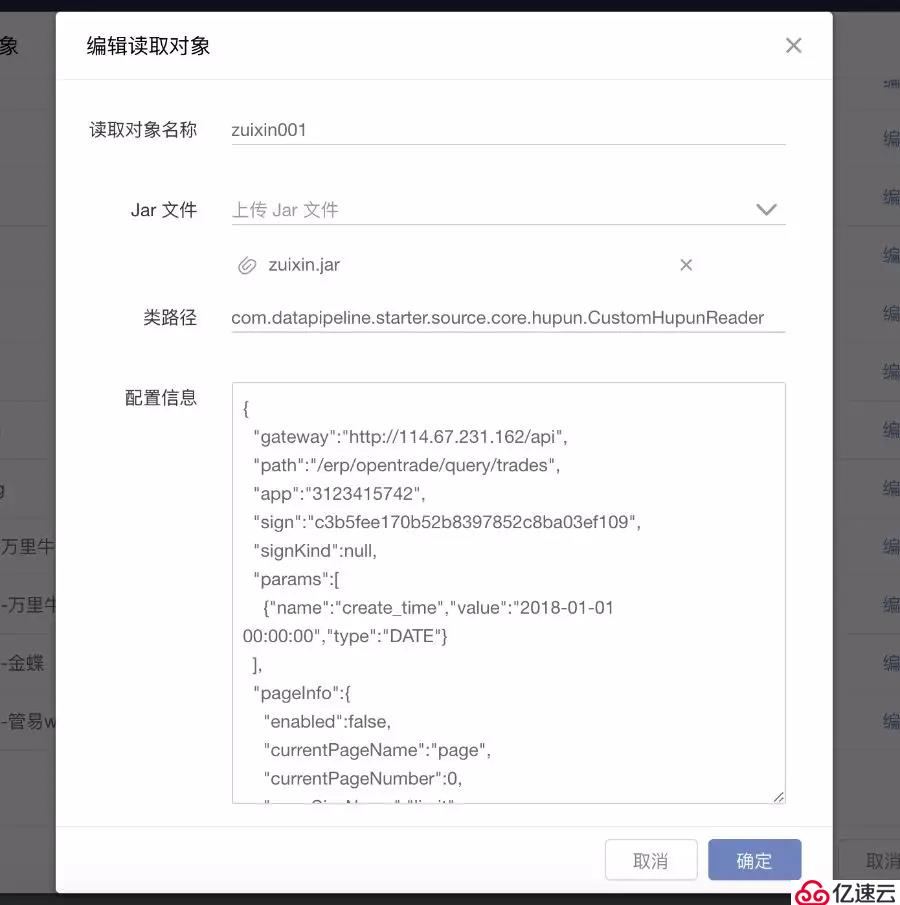
(2) 用戶可以在一個任務中選擇一個或多個讀取對象,每個讀取對象可以映射到目標表的表中

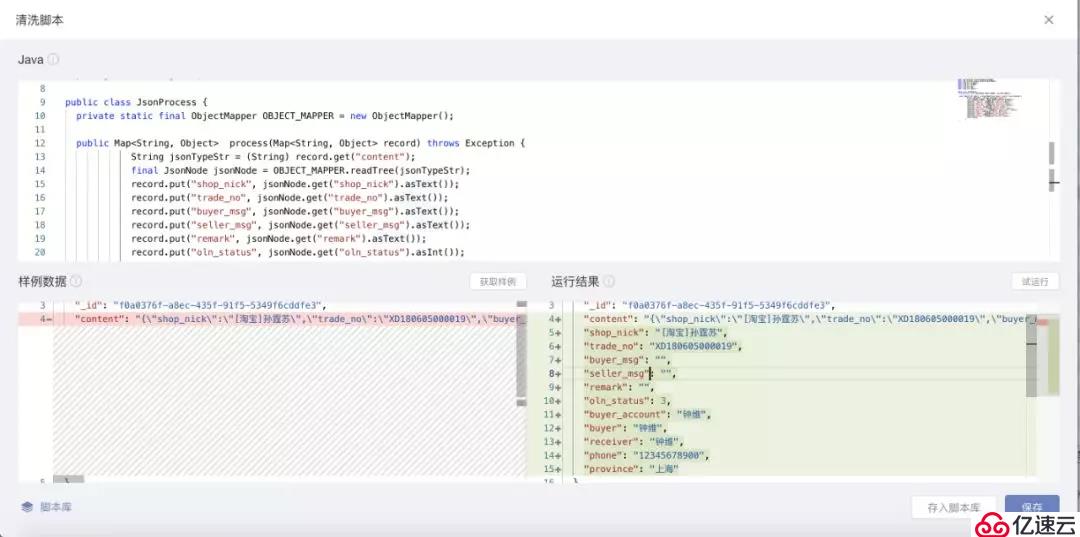
(3)完成讀取設置后,在寫入設置步驟中先確定每個讀取對象的數據解析邏輯
DataPipeline會提供JSON解析樣例,用戶也可以參考樣例,自定義解析邏輯。
「樣例數據」模塊會顯示通過讀取對象配置獲取的數據。
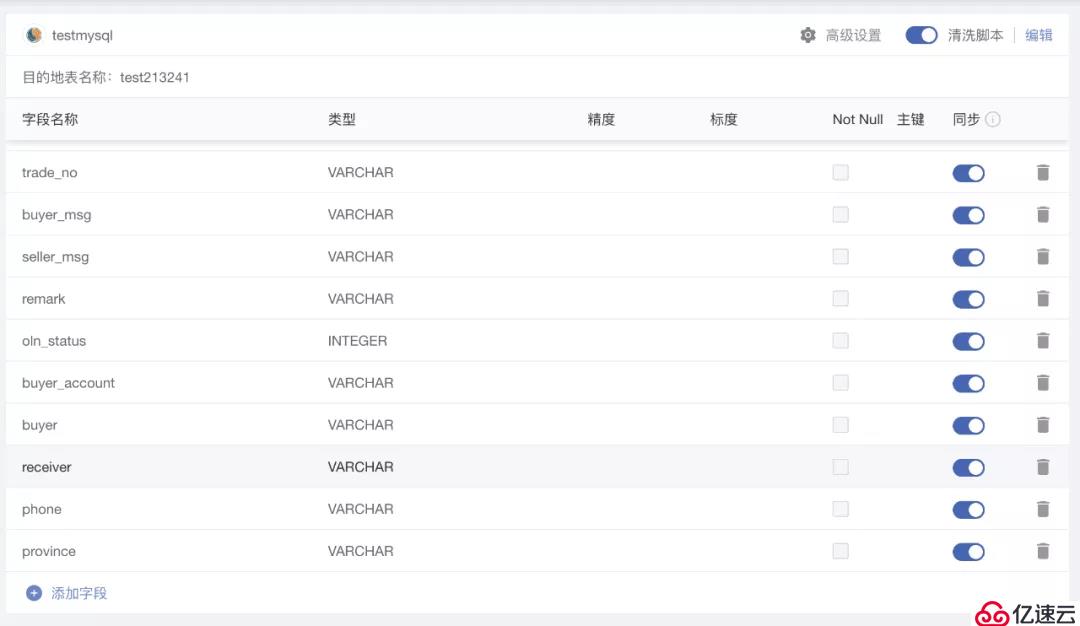
4 完成解析邏輯后,用戶可以手動添加名稱并選擇對應的數據類型 ,來完成目的地表結構
DataPipeline每一次版本的迭代都凝聚了團隊對企業數據使用需求的深入思索,其它新功能還在路上,很快就會跟大家見面了,希望能夠切實幫助大家更敏捷高效地獲取數據。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





