溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
文 | 呂鵬 DataPipeline架構師

進入大數據時代,實時作業有著越來越重要的地位。本文將從以下幾個部分進行講解DataPipeline在大數據平臺的實時數據流實踐。
一、企業級數據面臨的主要問題和挑戰
1.數據量不斷攀升
隨著互聯網+的蓬勃發展和用戶規模的急劇擴張,企業數據量也在飛速增長,數據的量以GB為單位,逐漸的開始以TB/GB/PB/EB,甚至ZB/YB等。同時大數據也在不斷深入到金融、零售、制造等行業,發揮著越來越大的作用。
2. 數據質量的要求不斷地提升
當前比較流行的AI、數據建模,對數據質量要求高。尤其在金融領域,對于數據質量的要求是非常高的。
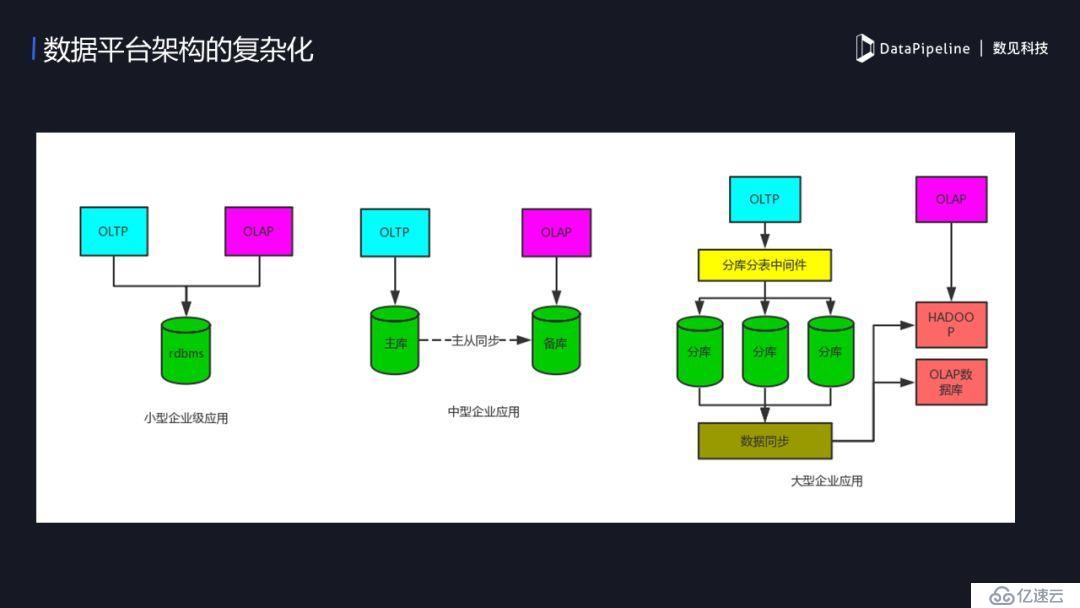
3. 數據平臺架構的復雜化
企業級應用架構的變化隨著企業規模而變。規模小的企業,用戶少、數據量也小,可能只需一個MySQL就搞能搞;中型企業,隨著業務量的上升,這時候可能需要讓主庫做OLTP,備庫做OLAP;當企業進入規模化,數據量非常大,原有的OLTP可能已經不能滿足了,這時候我們會做一些策略,來保證OLTP和OLAP隔離,業務系統和BI系統分開互不影響,但做了隔離后同時帶來了一個新的困難,數據流的實時同步的需求,這時企業就需要一個可擴展、可靠的流式傳輸工具。
二、大數據平臺上的實踐案例
下圖是一個典型的BI平臺設計場景,以MySQL為例,DataPipeline是如何實現MySQL的SourceConnector。MySQL作為Source端時:
全量+ 增量;
全量:通過select 方式,將數據加載到kafka中;
增量:實時讀取 binlog的方式;
使用binlog時需要注意開啟row 模式并且image設置為 full。
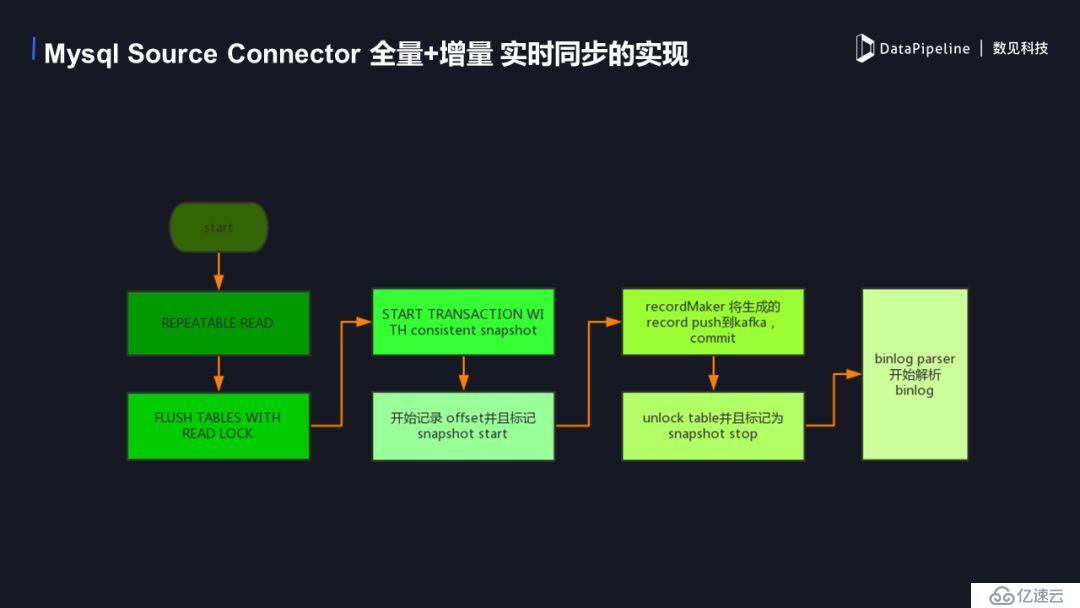
1. MySQL SourceConnector 全量+增量實時同步的實現
下面是具體的實現流程圖,首先開啟repeatable read事務,保證在執行讀鎖之前的數據可以確實的讀到。然后進行flush table with read lock 操作,添加一個讀鎖,防止這個時候有新的數據進入影響數據的讀取,這時開始一個truncation with snapshot,我們可以記錄當前binlog的offset 并標記一個snapshot start,這時的offset 為增量讀取時開始的offset。當事務開始后可以進行全量數據的讀取。record marker這時會將生成record 寫到 kafka 中,然后commit 這個事務。當全量數據push完畢后我們解除讀鎖并且標記snapshot stop,此時全量數據已經都進入kafka了,之后從之前記錄的offset開始增量數據的同步。
2. DataPipeline做了哪些優化工作
1)以往在數據同步環節都分為全量同步和增量同步,全量同步為一個批處理。在批處理時我們都是進行all or nothing的處理,但當大數據情況下一個批量會占用相當長的時間,時間越長可靠性就越難保障,所以往往會出現斷掉的情況,這時一個重新處理會讓很多人崩潰。DataPipeline 解決了這一痛點,通過管理數據傳輸時的position 來做到斷點續傳,這時當一個大規模的數據任務即使發生了意外,也可以重斷掉的點來繼續之前的任務,大大縮短了同步的時間,提高了同步的效率。
2)在同步多個任務的時候,很難平衡數據傳輸對源端的壓力和目的端的實時性,在大數據量下的傳輸尤其能夠體現,這時DataPipeline 在此做了大量相關測試來優化不同的連接池,開放數據傳輸效率的自定義化,供客戶針對自己的業務系統定制合適的傳輸任務,對于不同種類的數據庫的傳輸進行優化和調整,保證數據傳輸的高效性。
3)自定義異構數據類型的轉化,往往開源類大數據傳輸工具如 sqoop 等,對異構數據類型的支持不夠靈活,種類也不夠齊全。像金融領域中對數據精度要求較高的場景,在傳統數據庫向大數據平臺傳輸時造成的精度丟失是很大的一個問題。DataPipeline 對此做了更多數據類型的支持,比如hive 支持的復雜類型以及 decimal 和 timestamp 等。
3. Sink端之Hive
1)Hive的特性
Hive 內部表和外部表;
依賴HDFS;
支持事務和非事務;
多種壓縮格式;
分區分桶。
2)Hive同步的問題
如何保證實時的寫入?
schema change了怎么辦?
怎么擴展我想保存的格式?
怎么實現多種分區方式?
同步中斷了怎么辦?
如何保證我的數據不丟?
3)KafkaConnect HDFS 的 Hive 同步實踐
使用外表:Hive外部表,能夠提高寫入效率,直接寫HDFS,減少IO消耗,而內表會比外表多一次IO;
Schema change:目前的做法是目的端根據源端的變化而變化,當有增加列刪除列的情況,目標端會跟隨源端改動;
目前支持的存儲格式:parquet,avro ,csv
插件化的partitioner,提供多種分區方式,如 Wallclock RecordRecordField:wallclock是使用寫入到hive端時的系統時間,Record 使用是讀取時生成record的時間,RecordField是使用用戶自定義的時間戳來定義分區,未來會實現可自定義化的partitioner 來滿足不同的需求;
Recover 機制保障中斷后不會丟失數據;
使用WAL (Write-AheadLogging)機制,保證數據目的端數據一致性。
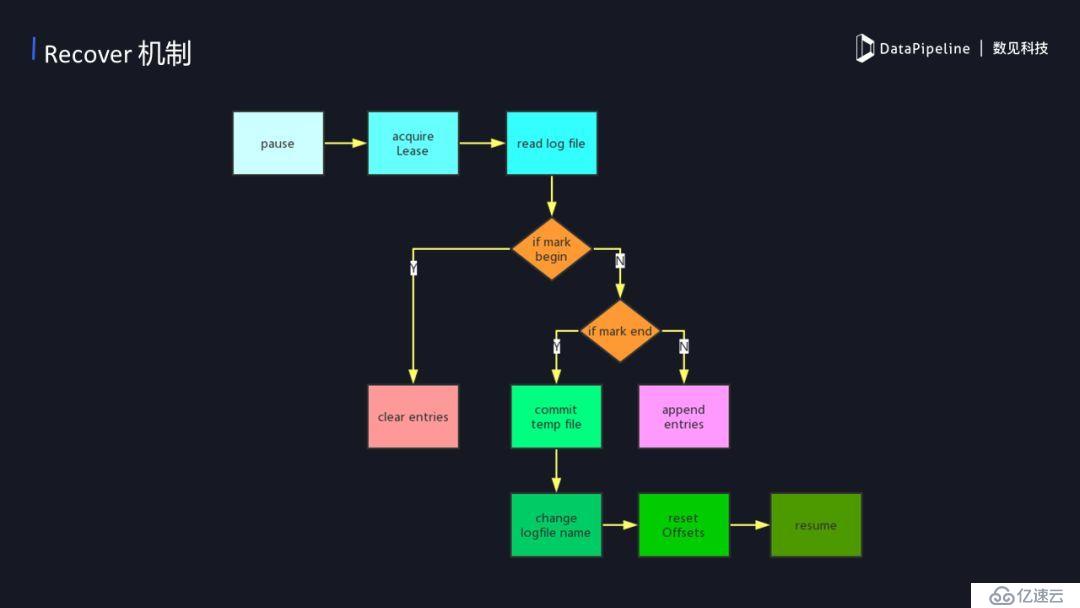
4)Recover的機制
recover 是一種恢復的機制,在數據傳輸的階段往往可能出現各種不同的問題,如網絡問題等等。當出現問題后我們需要恢復數據同步,那么recover是怎么保證數據正常傳輸不丟失呢?當recover開始的時候,獲取目標文件在hdfs 上的租約,如果這時候需要讀寫的HDFS當前文件是被占用的,那我們需要等待它直到可以獲取到租約。當我們獲取到租約后就可以開始讀之前寫入時候的log,如果第一次會創建一個新的log,并標記一個begin,然后記錄了當時的kafka offset。這時候需要清理之前遺留下來的臨時數據,清理掉之后再重新開始同步直到同步結束會標記一個end。如果沒有結束的話就相當于正在進行中,正在進行中每次都會提交當前同步的offset,來保證出現意外后會回滾到之前offset。
5)WAL (Write-Ahead Logging)機制
Write-Ahead Logging機制其實就是核心思想在數據寫入到數據庫之前,它先寫臨時文件,當一個批次結束后,在將這個臨時文件改名為正式文件,確保每次提交后的正式文件一致性,如果中途出現寫入錯誤將臨時文件刪除重新寫入,相當于一個回滾。hive 的同步主要利用這種實現方式來保證一致性。首先它同步數據寫入到HDFS臨時文件上,確保一個批次的數據正常后再重命名到正式文件當中。正式的文件名會包含kafka offset,例如一個avro 文件的文件名為 xxxx+001+0020.avro ,這表示當前文件中有offset 1 到 20 的20條數據。
4. Sink端之GreenPlum
GreenPlum,是一個MPP架構的數據倉庫,底層由多個postgres數據庫作為計算節點,擅長OLAP,作為BI數據倉庫有著良好的性能。
1)DataPipeline對GreenPlum 同步實踐以及優化策略
greenplum 支持多種數據加載方式,目前我們使用copy的加載方式。
批量處理提高sink端寫入效率,不進行insert 和 update 的操作,一律使用 delete + copy 的方式批量加載;
多線程加預加載機制:
? 每個需要同步的表單獨記錄一個offset,當整個任務失敗時可以分開進行恢復;
? 使用一個線程池管理加載數據的線程,每個同步的表單獨一個線程來進行加載數據,多表同時同步;
? 在加載數據的時間里,提前對kafka進行消費,緩存處理好的一個數據集,當一個線程加載數據結束后馬上開始新的線程加載數據,減少處理加載數據的時間;
delete + copy的方式可以保證數據最終一致性;
source 端有主鍵的表可以通過主鍵來合并一個批次需要同步的數據,如一個需要同步的批量數據中包含一條 insert 的數據,后面跟著 update 該條數據,那就無需同步兩遍,將該數據更新到 update 之后的狀態 copy 到 gp 當中即可。
同步GreenPlum需要注意:因為是通過copy 寫入文件的,需要文件是結構化數據,典型的是使用CSV,CSV 寫入時需注意spiltquote,escapequote,避免出現數據錯位的現象。update主鍵的問題 , 當源端是update一個主鍵時,同時需要記錄update前的主鍵,并在目標端進行刪除。還有 \0 特殊字符的問題,因為核心是用C語言,所以在同步的時候\0需要特殊處理掉。
三、DataPipeline未來的工作
1. 目前我們碰到kafka connect rebalance的一些問題,所以我們對其進行了改造。以往的rebalance機制是假如我們增加或者刪除一個task,會導致整個集群rebalance,這樣造成很多無謂的開銷而且頻繁的rebalance 不利于數據同步的任務的穩定。于是我們將rebalance機制改造成一個黏性的機制:
當我們增加一個新的任務的時候,我們會檢查所有的worker使用率比較低的,當worker的task比較少,我們只把它加進比較少的worker就可以了,也不需要做全量的平衡,當然這時候可能還是有一些不平衡的資源浪費,這是我們可以容忍的,至少比我們做一次全量的rebalance開銷要小;
假如刪除一個task,以往的機制是刪除一個task的時候也會做全量的Rebalance,新的機制不會觸發rebalance。這時候如果時間長也會造成一個資源不平衡,這是我們可以自動化rebalance一下所有的集群;
假如說集群的某個節點宕掉了,該節點的task怎么辦呢?我們不會馬上就把這個節點上的 task分配出去,會先等待10分鐘,因為有的時候它可能只是短暫的連接超時,過一段時間后就會恢復,如果根據這個來做一次rebalance,可能這是不太值的。當等待10分鐘后節點還是沒有恢復,我們再做rebalance,將宕掉的節點任務分配到其他節點上;
2. 源端的數據一致性,目前通過WAL的機制可以保證目的端的一致性;
3. 大數據量下的同步優化以及提高同步的穩定性。
四、總結
1. 大數據時代企業數據集成主要面臨各種復雜的架構,應對這些復雜的系統對ETL的要求也越來越高。我們能做的就是需要權衡利弊選取一個符合業務需求的框架;
2. Kafka Connect 比較適合對數據量大,且有實時性需求的業務;
3. 基于Kafka Connect 優良特性可以依據不同的數據倉庫特性來提高數據時效性和同步效率;
4. DataPipeline針對目前企業在大規模實時數據流的痛點,進行了相關的改造和優化,首先數據端到端一致性的保證是幾乎所有企業在數據同步過程中碰到的,目前已經做到基于kafka connect 的框架中 rebalance 中的優化和改造。
—end—
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





