溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何在pandas中利用DataFrame對象對數據進行抽取,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
pandas的DataFrame對象,本質上是二維矩陣,跟常規二維矩陣的差別在于前者額外指定了每一行和每一列的名稱。這樣內部數據抽取既可以用“行列名稱(對應.loc[]方法)”,也可以用“矩陣下標(對應.iloc[]方法)”兩種方式進行。
下面具體說明:
首先生成一個DataFrame對象:
import pandas as pd score = [[34,67,87],[68,98,58],[75,73,86],[94,59,81]] name = ['小明','小紅','小李'] course = ['語文','數學','英語','政治'] mydata1 = pd.DataFrame(data=score,columns=name,index=course)#指定行名(index)和列名(columns) print(mydata1) mydata2 = pd.DataFrame(score)#不指定行列名,默認使用0,1,2…… print(mydata2)
#指定行列名 小明 小紅 小李 語文 34 67 87 數學 68 98 58 英語 75 73 86 政治 94 59 81 #采用默認行列名 0 1 2 (默認列名) 0 34 67 87 1 68 98 58 2 75 73 86 3 94 59 81
DataFrame對象生成時除了必須指定data參數外,用戶還可以指定兩個參數columns(列名)和index(行名,注意這里的index不僅可以是數字,也可以是用戶指定的任何數據類型,如字母),如果不指定,則行列名默認都采用0、1、2……。
下圖說明了前面的情況:
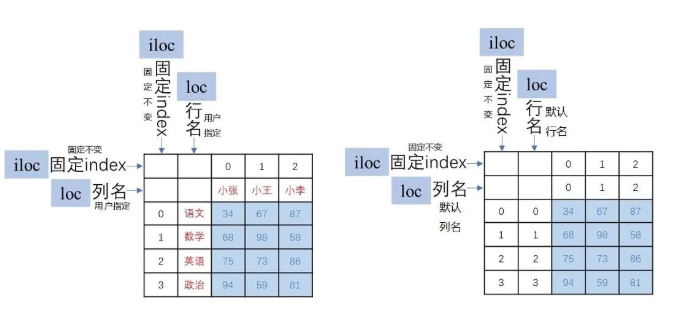
DataFrame對象的.loc[]和.iloc[]方法都可用于抽取數據,區別是:
.loc[]:是location,以columns(列名)和index(行名)作為參數。
.iloc[]:是index location,以二維矩陣的位置指標(即0,1,2……)作為參數。
.loc[行標簽名/[行標簽名list],列標簽名/[列標簽名list]],即有兩個輸入參數,第一個指定行名,第二個指定列名。當只有一個參數時,默認是行名(即抽取整行),所有列都選中。
.loc[行位置/[行位置list],列位置/[列位置list]],也有兩個輸入參數,第一個指定行位置,第二個指定列位置。當只有一個參數時,默認是行位置(即抽取整行),所有列都選中。
#以下用.loc[]抽取1行名為‘語文'的數據(包括所有列) mydata1.loc['語文'] mydata1.loc['語文',] mydata1.loc['語文',:] mydata1.loc[['語文'],] mydata1.loc[['語文'],:] #以下用.iloc[]抽取1行名為‘語文'的數據(包括所有列) mydata1.iloc[0] mydata1.iloc[0,] mydata1.iloc[0,:] mydata1.iloc[[0],] mydata1.iloc[[0],:] #輸出方式1(第1個參數無[],這是一個Series對象): 小明 34 小紅 67 小李 87 Name: 語文, dtype: int64 #輸出方式2(第1個參數有[],這是一個DataFrame對象): 小明 小紅 小李 語文 34 67 87 Name: 語文, dtype: int64
上述.loc[]和.iloc[]都只接收了1個參數“語文”或者“0”,因此默認都表示行信息,而列則全部被選中,即抽取'語文'這整一行數據。','表示將兩個參數隔開(如果有兩個參數的話),':'這里表示選擇中所有列。當只有一個輸入參數時,python默認','和':'既可寫上也可省略。注意:參數['語文']或[0]中只有一個對象時(即只有一行),[]也可以省略,如果有多個對象(即多行)則必須加上[]。此外還需注意,加上[]表示抽取的結果無論是一個數據,一行數據,還是一列數據,他都是DataFrame對象;不加[]時,如果選中的是一行或者一列數據,則是Series對象,如果是一個單獨的數據,則是該數據本身的類型。
#指定多行行名抽取 mydata1.loc[['英語','語文','政治'],:] 小明 小紅 小李 英語 75 73 86 語文 34 67 87 政治 94 59 81 mydata1.iloc[[1,0],:] 小明 小紅 小李 數學 68 98 58 語文 34 67 87
例2和例1唯一的差別是,第一個參數指定了多行一起輸出,此時必須用[]將各行名或者下標括起來,否則出錯。后面的','和':'同例1,可省略。注意:原始數據的行順序是:語文、數學、英語、政治,這里的提取順序是['英語','語文','政治'],而輸出也是'英語','語文','政治',可見輸出順序和參數指定順序是一致的,而非按原始順序輸出。
mydata1.loc['語文':'英語',:] #連續抽取從語文到英語的所有行 小明 小紅 小李 語文 34 67 87 數學 68 98 58 英語 75 73 86 mydata1.loc[:'英語',:] #連續抽取從第1行到英語的所有行 小明 小紅 小李 語文 34 67 87 數學 68 98 58 英語 75 73 86 mydata1.iloc[0:3,:] #連續抽取1~3行 小明 小紅 小李 語文 34 67 87 數學 68 98 58 英語 75 73 86 mydata1.iloc[1:,:] #連續抽取第2行最后一行 小明 小紅 小李 數學 68 98 58 英語 75 73 86 政治 94 59 81
例3依然是接受1個參數,列參數沒有,后面的','和':'同例1,可省略。連續參數用‘start:end'的方式指定行范圍。注意:這里不能用[]將其括起來,否則出錯。此外用行列名連續取值時,比如['語文':'政治']會把'政治'所在行也取出來,而利用矩陣下標時,0:3只取0,1,2對應的三行,最后一行不會取出;但是如果行列標簽名本身就是整數0,1,2……,而不是文字或者其他類型,那么在使用連續行列標簽名取數據時,最后一行或者列是不會被取出的。
mydata1.loc[:,['小紅']] #所有行,小紅列,只有一列時,內部[]也可以省略 小紅 語文 67 數學 98 英語 73 政治 59 mydata1.loc[:,['小明','小紅']] #所有行,小明和小紅兩列 小明 小紅 語文 34 67 數學 68 98 英語 75 73 政治 94 59 mydata1.iloc[:,[1,2]] #所有行,第2和第3列 小紅 小李 語文 67 87 數學 98 58 英語 73 86 政治 59 81 mydata1.loc[:,'小明':] #連續抽取從小明列開始到最后一列 小明 小紅 小李 語文 34 67 87 數學 68 98 58 英語 75 73 86 政治 94 59 81 mydata1.iloc[:,:3] #連續抽取從1列開始到第3列 小明 小紅 小李 語文 34 67 87 數學 68 98 58 英語 75 73 86 政治 94 59 81
抽取整列的方式跟抽取整行在參數設置上完全一樣。.loc[]和.iloc[]兩個方法默認列為第二個參數,因此抽取整列時,都必須帶上':,'作為區分前面行參數的‘分隔符',否則出錯。
mydata1.loc['語文','小明'] #輸入了兩個參數,輸出語文行小明列,即一個數據 34 <class 'numpy.int64'> #沒帶[]時,單個數字是這種類型 mydata1.loc[['語文'],['小明']] #輸出語文行小明列,即一個數據 小明 語文 34 <class 'pandas.core.frame.DataFrame'> #帶[]時,輸出依然是DataFrame對象 mydata1.iloc[1,2] #第2行第3列數據,單個數據 58 <class 'numpy.int64'> #注意沒帶[]時的輸出類型 mydata1.iloc[[1],[2]] 小李 數學 58 <class 'pandas.core.frame.DataFrame'> #注意帶[]時的輸出類型 mydata1.loc[['語文','數學'],['小明']] #輸出語文數學行,小明列的數據 小明 語文 34 數學 68 mydata1.iloc[1:,[0,2]] #輸出從第2行到最后一行,第1和第3行對應數據 小明 小李 數學 68 58 英語 75 86 政治 94 81
同時抽取分部行和列的情況,就是把上述單獨抽取行和列的方式合并起來用。抽取整個DataFrame對象則是.loc[:,:]或.iloc[:,:],雖然這么做沒啥意義。
(1)DataFrame對象的.loc[,]和.iloc[,]方法用于抽取數據,.loc[,]用行列的標簽名作為參數,.iloc[,]用二維矩陣元素的網格下標作為參數。
(2)兩個方法都接受兩個參數,第一個是“行標簽”或者“矩陣行號”,第二個是“列標簽”或者“矩陣列號”。
(3)兩種方法當只指定一個輸入參數時,都默是跟“行”相關,而“列”則全部被選中。如何行和列都需要指定時,中間用“逗號,”隔開,這非常重要,否則出錯。
(4)當需要選中所有行的某幾列時,行參數可以省略,列參數需要指定,此時列參數前面必須帶上“,:”,形如.loc[:,列參數],.iloc[:,列參數]。
(5).loc[,]和.iloc[,]設置了一個還是兩個輸入參數,關鍵看有沒有“,”將兩個參數分開,且要區分逗號是一個參數的內部逗號,還有用于分隔行列參數的逗號。
(6)對于兩個參數的概念區分,.loc['語文','數學']這表示輸入了兩個參數,行參數是‘語文',列參數是‘數學',對于上面的表格而言這是錯的,因為沒有叫‘數學'的列,應寫為[['語文','數學']],即‘數學'也是行參數的一部分,['語文','數學']整體作為一個行參數,這里的逗號不是用以分隔行和列,僅僅是行list里面的逗號。[['語文','數學']]=[['語文','數學'],]=[['語文','數學'],:],都表示只有一個行參數,列全部選中。
關于如何在pandas中利用DataFrame對象對數據進行抽取就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





