溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關使用Python如何實現抓包并解析json爬蟲,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
Python抓包并解析json爬蟲
在使用Python爬蟲的時候,通過抓包url,打開url可能會遇見以下類似網址,打開后會出現類似這樣的界面,無法繼續進行爬蟲:
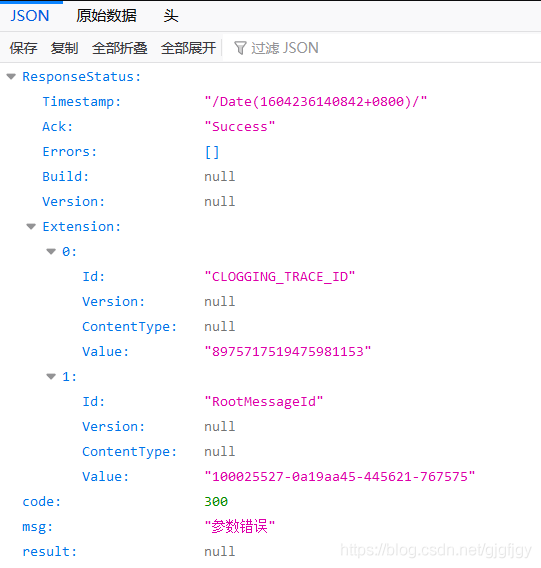
例如:
需要爬取網頁中第二頁的數據時,點擊F12➡網絡(Network)➡XHR,最好點擊清除鍵,如下圖:
通過點擊“第二頁”,會出現一個POST請求(有時會是GET請求),點擊POST請求的url,(這里網址以POST請求為例),
如圖:
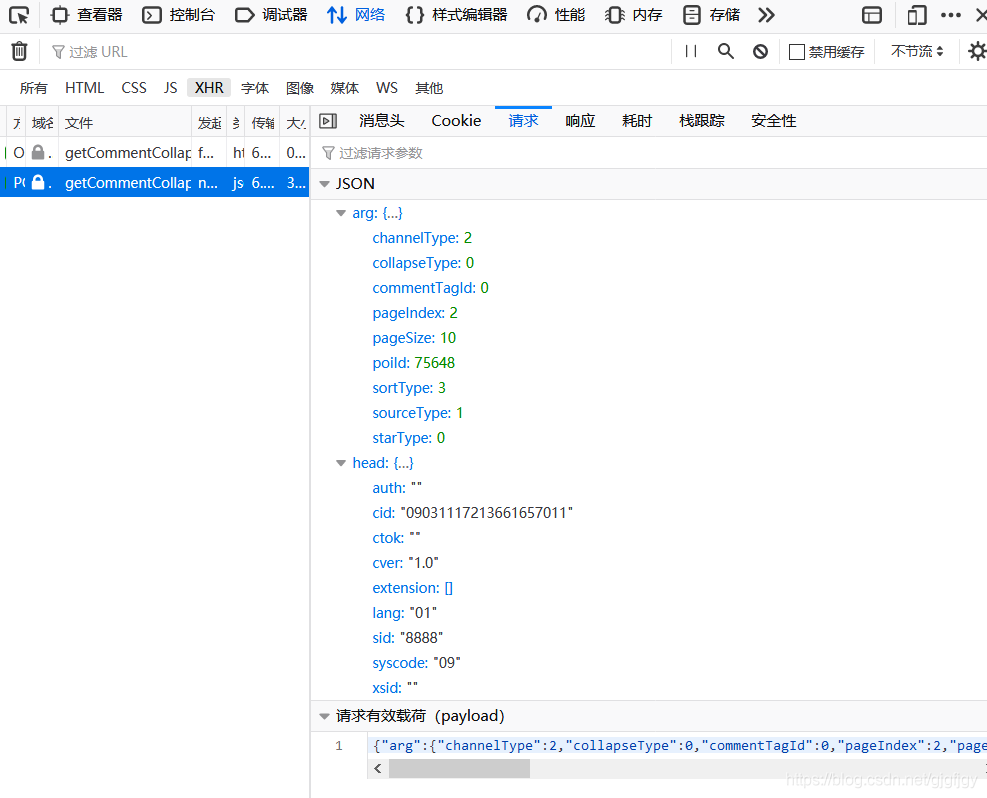
然后復制參數代碼
代碼展示:
import requests
import json
url = 'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031130211378497389'
header={
'authority': 'm.ctrip.com',
'method': 'POST',
'path': '/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031130211378497389',
'scheme': 'https',
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'content-length': '278',
'content-type': 'application/json',
'cookie': '__utma=1.1986366783.1601607319.1601607319.1601607319.1; __utmz=1.1601607319.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); _RSG=blqD1d4mGX0BA_amPD3t29; _RDG=286710759c35f221c000cbec6169743cac; _RGUID=0850c049-c137-4be5-90b7-0cd67093f28b; MKT_CKID=1601607321903.rzptk.lbzh; _ga=GA1.2.1986366783.1601607319; nfes_isSupportWebP=1; appFloatCnt=8; _gcl_dc=GCL.1601638857.CKzg58XqlewCFQITvAodioIJWw; Session=SmartLinkCode=U155952&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=&SmartLinkLanguage=zh; Union=OUID=index&AllianceID=4897&SID=155952&SourceID=&createtime=1602506741&Expires=1603111540922; MKT_OrderClick=ASID=4897155952&AID=4897&CSID=155952&OUID=index&CT=1602506740926&CURL=https%3A%2F%2Fwww.ctrip.com%2F%3Fsid%3D155952%26allianceid%3D4897%26ouid%3Dindex&VAL={"pc_vid":"1601607319353.3cid9z"}; MKT_Pagesource=PC; _RF1=218.58.59.72; _bfa=1.1601607319353.3cid9z.1.1602506738089.1602680023977.4.25; _bfi=p1%3D290510%26p2%3D290510%26v1%3D25%26v2%3D24; MKT_CKID_LMT=1602680029515; __zpspc=9.5.1602680029.1602680029.1%232%7Cwww.baidu.com%7C%7C%7C%25E6%2590%25BA%25E7%25A8%258B%7C%23; _gid=GA1.2.1363667416.1602680030; _jzqco=%7C%7C%7C%7C1602680029668%7C1.672451398.1601607321899.1602506755440.1602680029526.1602506755440.1602680029526.undefined.0.0.16.16',
'cookieorigin': 'https://you.ctrip.com',
'origin': 'https://you.ctrip.com',
'pragma': 'no-cache',
'referer': 'https://you.ctrip.com/',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
dat = {
"arg": {
'channelType': 2,
'collapseType': 0,
'commentTagId': 0,
'pageIndex': 1,
'pageSize': 10,
'poiId': 75648,
'sortType': 3,
'sourceType': 1,
'starType': 0
},
"head": {
'auth': "",
'cid': "09031117213661657011",
'ctok': "",
'cver': "1.0",
'extension': [],
'lang': "01",
'sid': "8888",
'syscode': "09",
'xsid': ""
}
}
r = requests.post(url, data=json.dumps(dat), headers=header)
s = r.json()
print(s)運行結果:

然后右擊結果,再點擊Show as JSON:

以上就是使用Python如何實現抓包并解析json爬蟲,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





