溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Mysql中的臨時表與分區表的區別有哪些,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
臨時表與內存表
內存表,指的是使用Memory引擎的表,建表語法是create table … engine=memory。這種 表的數據都保存在內存里,系統重啟的時候會被清空,但是表結構還在。除了這兩個特性看 上去比較“奇怪”外,從其他的特征上看,它就是一個正常的表
臨時表,可以使用各種引擎類型 。如果是使用InnoDB引擎或者MyISAM引擎的臨時表,寫 數據的時候是寫到磁盤上的。當然,臨時表也可以使用Memory引擎。
臨時表特性

由于臨時表只能被創建它的session訪問,所以在這個session結束的時候,會自動刪除臨時表。 也正是由于這個特性,臨時表就特別適合join優化這種場景。
create temporary table temp_t like t1;
alter table temp_t add index(b);
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
不同session的臨時表是可以重名的,如果有多個session同時執行join優化,不需要擔心表名重復導致建表失敗的問題。不需要擔心數據刪除問題。如果使用普通表,在流程執行過程中客戶端發生了異常斷開,或者數據庫發生異常重啟,還需要專門來清理中間過程中生成的數據表。而臨時表由于會自動回收,所以不需要這個額外的操作。臨時表的應用
分庫分表系統的跨庫查詢
一般分庫分表的場景,就是要把一個邏輯上的大表分散到不同的數據庫實例上。比如。將一個大 表ht,按照字段f,拆分成1024個分表,然后分布到32個數據庫實例上。
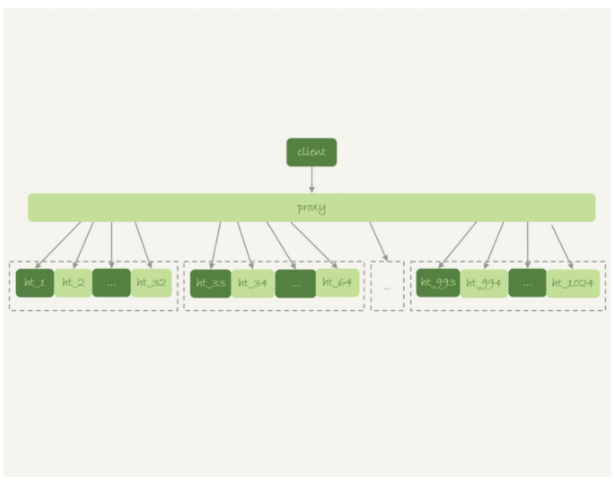
分區key的選擇是以“減少跨庫和跨表查詢”為依據的。如果大部分的語句都會包 含f的等值條件,那么就要用f做分區鍵。這樣,在proxy這一層解析完SQL語句以后,就能確定將這條語句路由到哪個分表做查詢。 比如
select v from ht where f=N;
這時,我們就可以通過分表規則(比如,N%1024)來確認需要的數據被放在了哪個分表上。這種語句只需要訪問一個分表,是分庫分表方案最歡迎的語句形式了。
但是,如果這個表上還有另外一個索引k,并且查詢語句是這樣的:
select v from ht where k >= M order by t_modified desc limit 100;
這時候,由于查詢條件里面沒有用到分區字段f,只能到所有的分區中去查找滿足條件的所有 行,然后統一做order by 的操作。這種情況下,有兩種比較常用的思路:
在proxy層的進程代碼中實現排序,對proxy端的壓力比較大,尤其是很容易出現內存不夠用和CPU瓶頸的問題。
把各個分庫拿到的數據,匯總到一個MySQL實例的一個表中,然后在這個匯總實例上做邏輯操作。
在匯總庫上創建一個臨時表temp_ht,表里包含三個字段v、k、t_modifified;
在各個分庫上執行
select v,k,t_modified from ht_x where k >= M order by t_modified desc limit 100;
把分庫執行的結果插入到temp_ht表中;
執行
select v from temp_ht order by t_modified desc limit 100;
為什么臨時表可以重名
create temporary table temp_t(id int primary key)engine=innodb;
執行這個語句的時候,MySQL要給這個InnoDB表創建一個frm文件保存表結構定義,還要有地方保存表數據。
這個frm文件放在臨時文件目錄下,文件名的后綴是.frm,前綴是“#sql{進程id}_{線程id}_序列 號”。你可以使用select @@tmpdir命令,來顯示實例的臨時文件目錄。

這個進程的進程號是1234,session A的線程id是4,session B的線程id是5。所以session A和session B創建的臨時表,在磁盤上的文件不會重名
MySQL維護數據表,除了物理上要有文件外,內存里面也有一套機制區別不同的表,每個表都對應一個table_def_key。 對于臨時表,table_def_key在“庫名+表名”基礎上,又加入了“server_id+thread_id”。
也就是說,session A和sessionB創建的兩個臨時表t1,它們的table_def_key不同,磁盤文件名 也不同,因此可以并存。
分區表的引擎層行為
ATE TABLE `t` (
`ftime` datetime NOT NULL,
`c` int(11) DEFAULT NULL,
KEY (`ftime`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
PARTITION BY RANGE (YEAR(ftime))
Û ॔ګդᎱ
B
(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB,
PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB,
PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB,
PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB);
insert into t values('2017-4-1',1),('2018-4-1',1);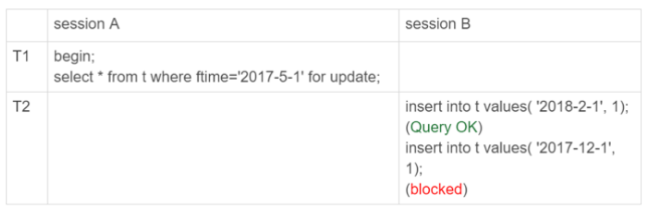
初始化表的時候,只插入了兩行數據,sessionA的select語句對ftime這兩個記錄之間的間隙加了鎖,間隙和加鎖狀態如圖:
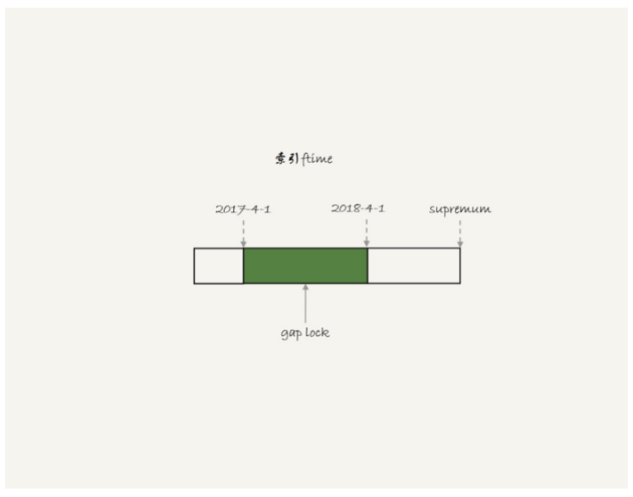
也就是說,2017-4-1和2018-4-1這兩個記錄之間的間隙會被鎖住,那么sessionB的兩條插入語句都應該進入鎖等待狀態。但是從效果上看,第一個insert語句是可以執行成功的,因為對于引擎來說,p2018和p2019是不同的表,2017的下一個記錄不是2018-4-1而是p2018中的supremum,所以在t1時刻索引如圖:
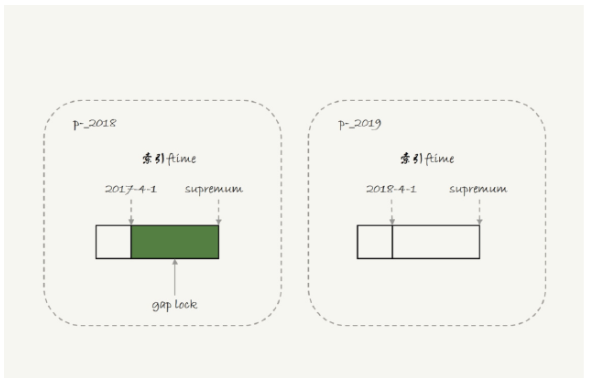
由于分區表的規則,sessionA只操作了p2018,sessionB要插入2018-2-1是可以的但要寫入2017-12-1要等待sessionA的間隙鎖。
對于MYISAM引擎:
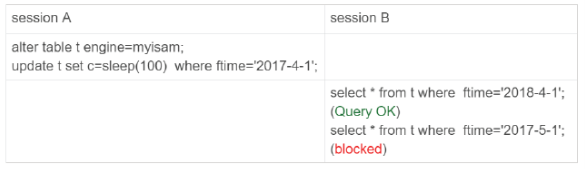
因為在sessionA中,sleep了100秒,由于myisam只支持表鎖,所以這條update會鎖住整個表t的讀,但是結果是,B的第一條語句是可以執行的,第二條語句才進入鎖等待狀態。
這是myisam表鎖只在引擎層實現的,sessionA加的表鎖,是所在p2018上,因此只會堵住分區上執行的查詢,落到其他分區的查詢不受影響。這樣看來,分區表還不錯,為什么不用呢,我們使用分區表的一個原因就是單表過大,那么不使用分區表,就要使用手動分表的方式。
手動分表需要創建t_2017,t_2018,t_2019,也就是找到需要更新的所有分表,依次執行,這和分區表無實質的差別,兩者一個由serverceng決定使用哪個分區,一個由應用層代碼決定使用哪個分表,因此,從引擎層看無實際差別。其實主要區別是在server層:打開表行為。
分區策略
每當第一次訪問一個分區表時,mysql需要把所有分區都訪問一遍:如果分區很多,比如查過了1000個,mysql啟動的時候,open_files_limit默認為1024,那么就會在訪問表的時候,由于打開了所有文件,超過了上限而報錯。
mysiam使用的分區策略成為通用分區策略,每次訪問分區都是有server層控制。有比較嚴重的性能問題。
innodb引擎引入了本地分區策略,是在innodb內部自己管理打開分區的行為。
分區表的server層行為
從server層看,一個分區表就是一個表。

雖然B只操作2017分區,但是由于A持有整個表t的mdl鎖,導致了B的alter語句被堵住。如果是使用普通分表,不會跟另外一個分表上的查詢語句出現MDL沖突。
小結:
分區表應用場景
分區表的優勢是對業務透明,相對于用戶分表來說,使用分區表的業務代碼更簡潔,分區表可以很方便的清理歷史數據。
alter table t drop partition 操作是刪除分區文件,效果跟drop類似,與delete相比,優勢是速度快,對系統影響小。
以上就是Mysql中的臨時表與分區表的區別有哪些,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





