溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章運用簡單易懂的例子給大家介紹MySQL的整體架構是什么,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
MySQL 在整體架構上分為 Server 層和存儲引擎層。其中 Server 層,包括連接器、查詢緩存、分析器、優化器、執行器等,存儲過程、觸發器、視圖和內置函數都在這層實現。數據引擎層負責數據的存儲和提取,如 InnoDB、MyISAM、Memory 等引擎。在客戶端連接到 Server 層后,Server 會調用數據引擎提供的接口,進行數據的變更。
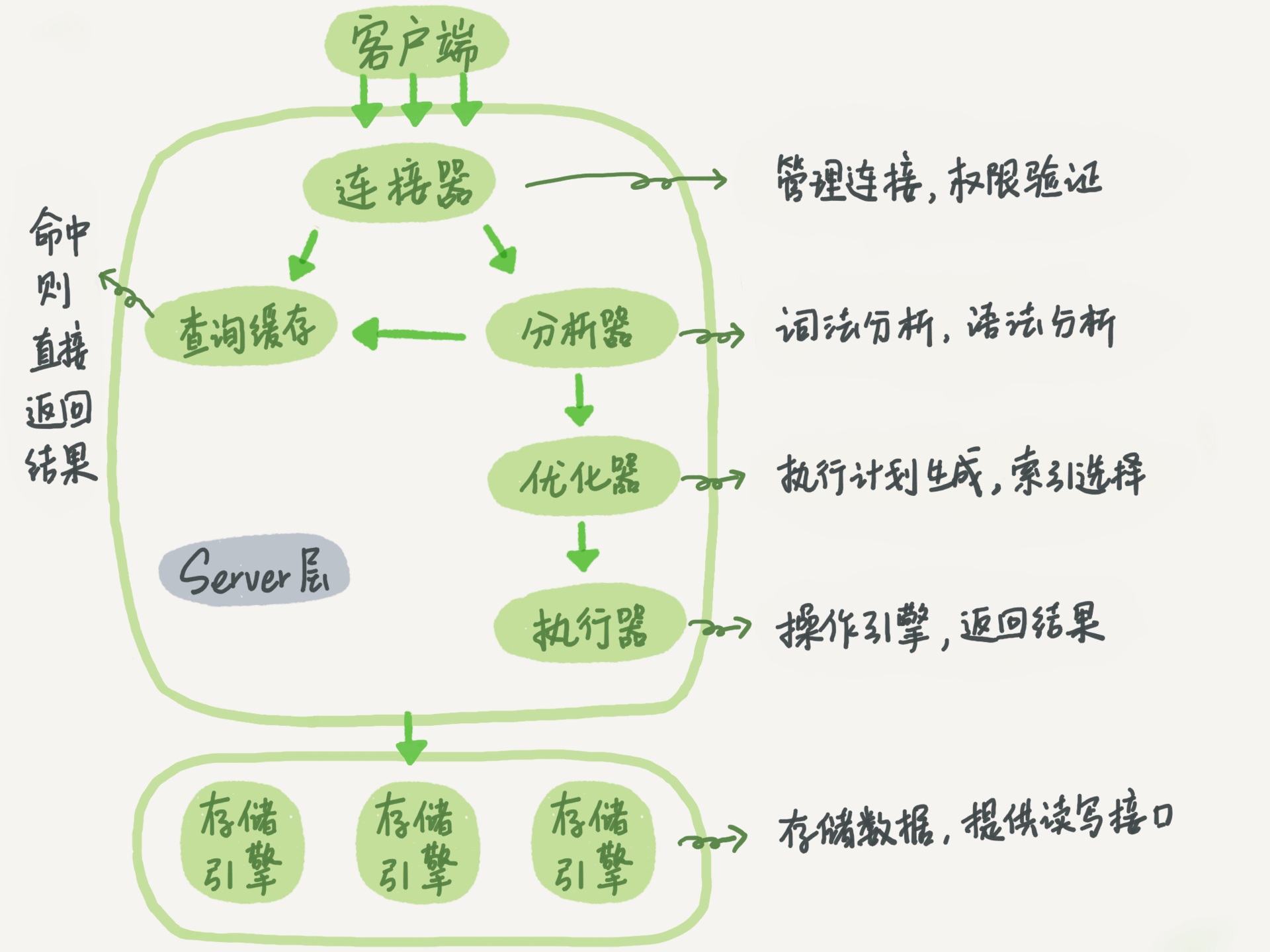
連接器
負責和客戶端建立連接,獲取用戶權限以及維持和管理連接。
通過 show processlist; 來查詢連接的狀態。在用戶建立連接后,即使管理員改變連接用戶的權限,也不會影響到已連接的用戶。默認連接時長為 8 小時,超過時間后將會被斷開。
簡單說下長連接:
優勢:在連接時間內,客戶端一直使用同一連接,避免多次連接的資源消耗。
劣勢:在 MySQL 執行時,使用的內存被連接對象管理,由于長時間沒有被釋放,會導致系統內存溢出,被系統kill. 所以需要定期斷開長連接,或執行大查詢后,斷開連接。MySQL 5.7 后,可以通過 mysql_rest_connection 初始化連接資源,不需要重連或者做權限驗證。
查詢緩存
當接受到查詢請求時,會現在查詢緩存中查詢(key/value保存),是否執行過。沒有的話,再走正常的執行流程。
但在實際情況下,查詢緩存一般沒有必要設置。因為在查詢涉及到的表被更新時,緩存就會被清空。所以適用于靜態表。在 MySQL8.0 后,查詢緩存被廢除。
分析器
詞法分析:
如識別 select,表名,列名,判斷其是否存在等。
語法分析:
判斷語句是否符合 MySQL 語法。
優化器
確定索引的使用,join 表的連接順序等,選擇最優化的方案。
執行器
在具體執行語句前,會先進行權限的檢查,通過后使用數據引擎提供的接口,進行查詢。如果設置了慢查詢,會在對應日志中看到 rows_examined 來表示掃描的行數。在一些場景下(索引),執行器調用一次,但在數據引擎中掃描了多行,所以引擎掃描的行數和 rows_examined 并不完全相同。
不預先檢查權限的原因:如像觸發器等情況,需要在執行器階段才能確定權限,在優化器階段無法驗證。
使用 profiling 查看 SQL 執行過程
打開 profiling 分析語句執行過程:
mysql> select @@profiling; +-------------+ | @@profiling | +-------------+ | 0 | +-------------+ 1 row in set, 1 warning (0.00 sec)
mysql> set profiling=1; Query OK, 0 rows affected, 1 warning (0.00 sec)
執行查詢語句:
mysql> SELECT * FROM s limit 10; +------+--------+-----+-----+ | s_id | s_name | age | sex | +------+--------+-----+-----+ | 1 | z | 12 | 1 | | 2 | s | 14 | 0 | | 3 | c | 14 | 1 | +------+--------+-----+-----+ 3 rows in set (0.00 sec)
獲取 profiles;
mysql> show profiles; +----------+------------+--------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------+ | 1 | 0.00046600 | SELECT * FROM s limit 10 | +----------+------------+--------------------------+ mysql> show profile; +----------------------+----------+ | Status | Duration | +----------------------+----------+ | starting | 0.000069 | | checking permissions | 0.000008 | 權限檢查 | Opening tables | 0.000018 | 打開表 | init | 0.000019 | 初始化 | System lock | 0.000010 | 鎖系統 | optimizing | 0.000004 | 優化查詢 | statistics | 0.000013 | | preparing | 0.000094 | 準備 | executing | 0.000016 | 執行 | Sending data | 0.000120 | | end | 0.000010 | | query end | 0.000015 | | closing tables | 0.000014 | | freeing items | 0.000032 | | cleaning up | 0.000026 | +----------------------+----------+ 15 rows in set, 1 warning (0.00 sec)
查詢具體的語句:
mysql> show profile for query 1; +----------------------+----------+ | Status | Duration | +----------------------+----------+ | starting | 0.000069 | | checking permissions | 0.000008 | | Opening tables | 0.000018 | | init | 0.000019 | | System lock | 0.000010 | | optimizing | 0.000004 | | statistics | 0.000013 | | preparing | 0.000094 | | executing | 0.000016 | | Sending data | 0.000120 | | end | 0.000010 | | query end | 0.000015 | | closing tables | 0.000014 | | freeing items | 0.000032 | | cleaning up | 0.000026 | +----------------------+----------+ 15 rows in set, 1 warning (0.00 sec)
MySQL 日志模塊
如前面所說,MySQL 整體分為 Server 層和數據引擎層,而每層也對應了自己的日志文件。如果選用的是 InnoDB 引擎,對應的是 redo log 文件。Server 層則對應了 binlog 文件。至于為什么存在了兩種日志系統,咱們往下看。
redo log
redo log 是 InnoDB 特有日志,為什么要引入 redo log 呢,想象這樣一個場景,MySQL 為了保證持久性是需要把數據寫入磁盤文件的。我們知道,在寫入磁盤時,會進行文件的 IO,查找操作,如果每次更新操作都這樣的話,整體的效率就會特別低,根本沒法使用。
既然直接寫入磁盤不行,解決方法就是先寫進內存,在系統空閑時再更新到磁盤就可以了。但光更新內存不行,假如系統出現異常宕機和重啟,內存中沒有被寫入磁盤的數據就會被丟掉,數據的一致性就出現問題了。這時 redo log 就發揮了作用,在更新操作發生時,InnoDb 會先寫入 redo log 日志(記錄了數據發生了怎么樣的改變),然后更新內存,最后在適當的時間再寫入磁盤,一般是找系統空閑的時間做。先寫日志,在寫磁盤的操作,就是常說到的 WAL (Write-Ahead- Logging)技術。
redo log 的出現,除了在效率上有了很大的改善,還保證了 MySQL 具有了 crash-safe 的能力,在發生異常情況下,不會丟失數據。
在具體實現上 redo log 的大小是固定的,可配置一組為 4 個文件,每個文件 1GB,更新時對四個文件進行循環寫入。
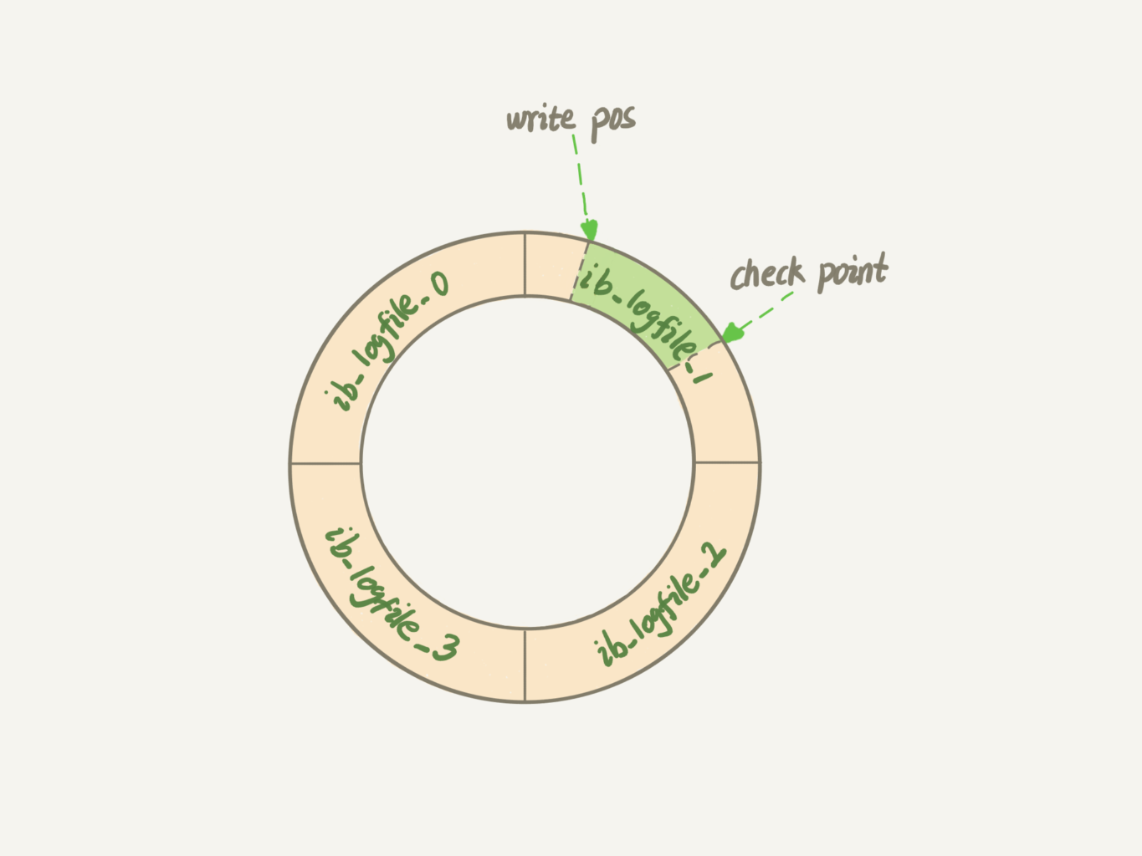
write pos 記錄當前寫入的位置,寫完就后移,當第寫入第 4 個文件的末尾時,從第 0 號位置重新寫入。
check point 表示當前可以擦除的位置,當數據更新到磁盤時,check point 就向后移動。
write pos 和 check point 之間的位置,就是可以記錄更新操作的空間。當 write pos 追上 check point ,不在能執行新的操作,先讓 check point 去寫入一些數據。
可以將 innodb_flush_log_at_trx_commit 設置成 1,開啟 redo log 持久化的能力。
binlog
binlog 則是 Server 層的日志,主要用于歸檔,在備份,主備同步,恢復數據時發揮作用,常見的日志格式有 row, mixed, statement 三種。具體的使用方法可以參見 Binlog 恢復日志這篇。
可以通過 sync_binlog=1 開啟 binlog 寫入磁盤。
這里對 binlog 和 redo 進行下區分:
兩階段提交
下面執行器和 InnoDB 執行 Update 時內部流程:
以更新 update T set c=c+1 where ID=2; 語句為例:
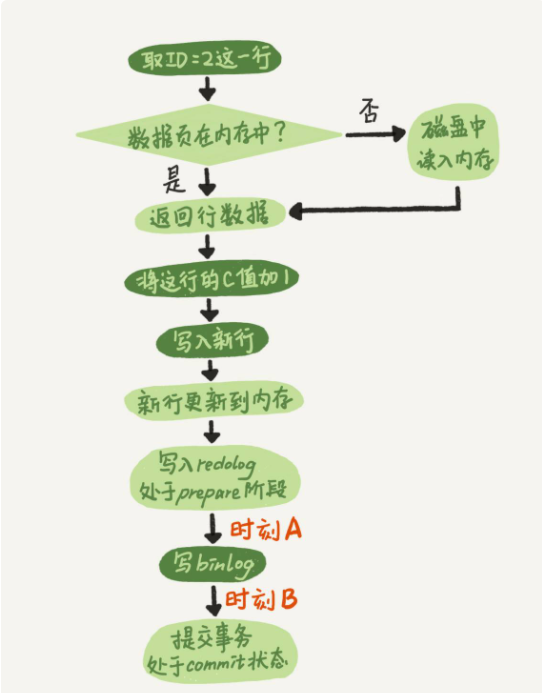
淺色為執行器執行,深色為引擎執行。
在更新內存后,將寫入 redo log 拆分了成兩個步驟:prepare 和 commit,就是常說的兩階段提交。用于保證當有意外情況發生時,數據的一致性。
這里假設下,如果不采用兩階段提交會發生什么?
再分析下兩階段提交的過程:
1.在寫 redo log prepare 階段奔潰,時刻 A 的位置。重啟后,發現 redo log 沒寫入,回滾此次事務。
2.如果在寫 binlog 時奔潰,重啟后,發現 binlog 未被寫入,回滾操作。
3.binlog 寫完,但在提交 redo log 的 commit 狀態時發生 crash
完整,提交事務
不完整,回滾事務。
如何判斷 binlog 是否完整?
如何將 redo log 和 binlog 關聯表示同一個操作?
結構中有一個共同的數據字段,XID. 在崩潰恢復時,會按順序掃描 redo log:
數據寫入后,最終落盤和 redo log 有無關系?
redo log buffer 和 redo log 的關系?
在一個事務的更新過程中,存在多個 SQL 語句,所以是要寫多次日志的。
但在寫的過程中,生產的日志要先保存起來,但在 commit 前,不能直接寫到 redo log 中。
所以通過內存中 redo log buffer 先存 redo log 的日志。在 commit 時,將 buffer 中的內容寫入 redo log.
關于MySQL的整體架構是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





