溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
使用Scrapy基于scrapy_redis實現分布式爬蟲部署?很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
準備工作
1.安裝scrapy_redis包,打開cmd工具,執行命令pip install scrapy_redis
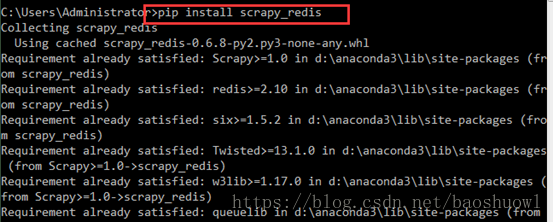
2.準備好一個沒有BUG,沒有報錯的爬蟲項目
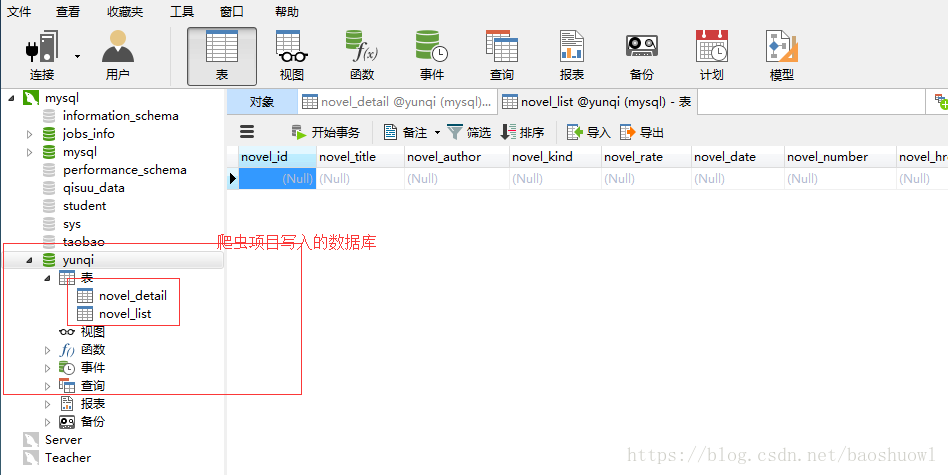
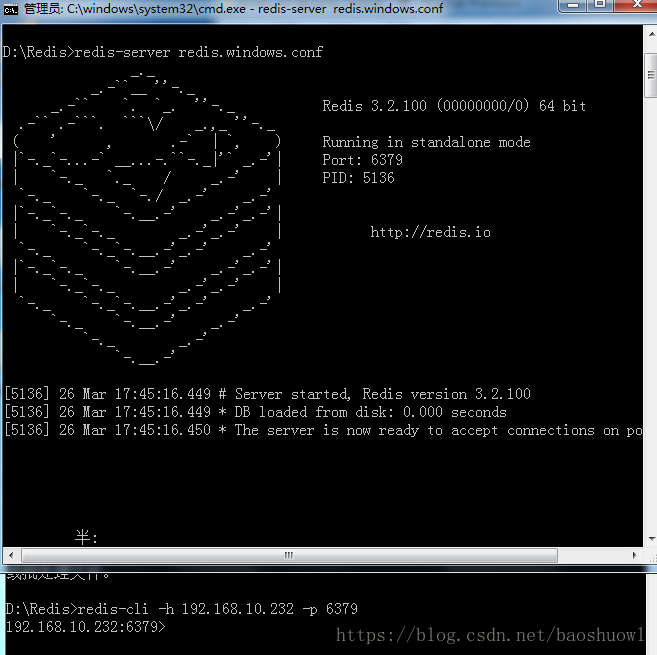
3.準備好redis主服務器還有跟程序相關的mysql數據庫
前提mysql數據庫要打開允許遠程連接,因為mysql安裝后root用戶默認只允許本地連接,詳情請看此文章
部署過程
1.修改爬蟲項目的settings文件
在下載的scrapy_redis包中,有一個scheduler.py文件,里面有一個Scheduler類,是用來調度url,還有一個dupefilter.py文件,里面有個類是RFPDupeFilter,是用來去重,所以要在settings任意位置文件中添加上它們

還有在scrapy_redis包中,有一個pipelines文件,里面的RedisPipeline類可以把爬蟲的數據寫入redis,更穩定安全,所以要在settings中啟動pipelines的地方啟動此pipeline

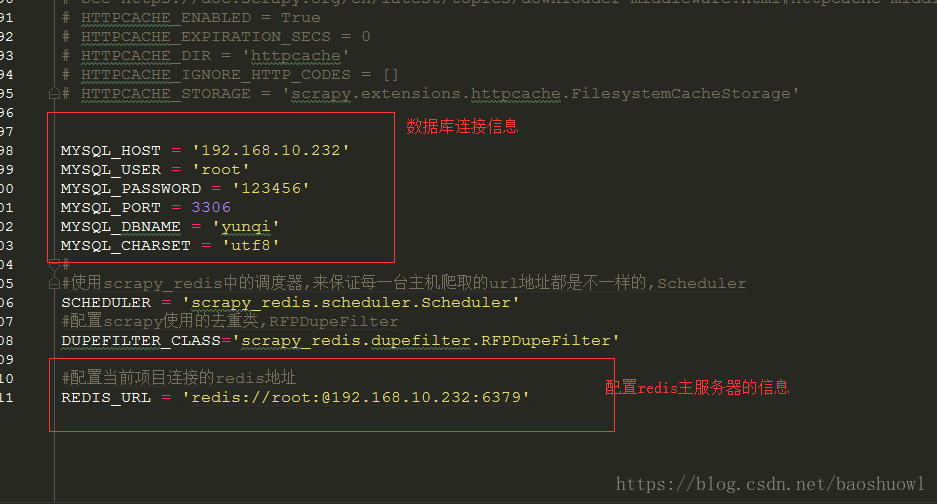
最后修改redis連接配置
2.修改spider爬蟲文件
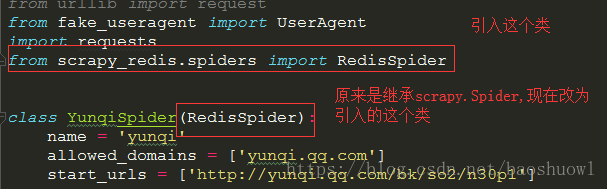
首先我們要引入一個scrapy_redis.spider文件中的一個RedisSpider類,然后把spider爬蟲文件原來繼承的scrapy.Spider類改為引入的RedisSpider這個類
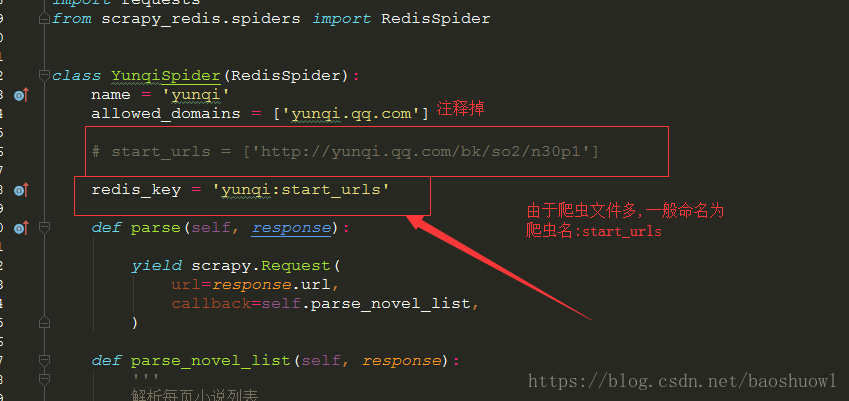
接著把原來的start_urls這句代碼注釋掉,加入redis_key = '自定義key值',一般以爬蟲名:urls命名
測試部署是否成功
直接運行我們的項目,
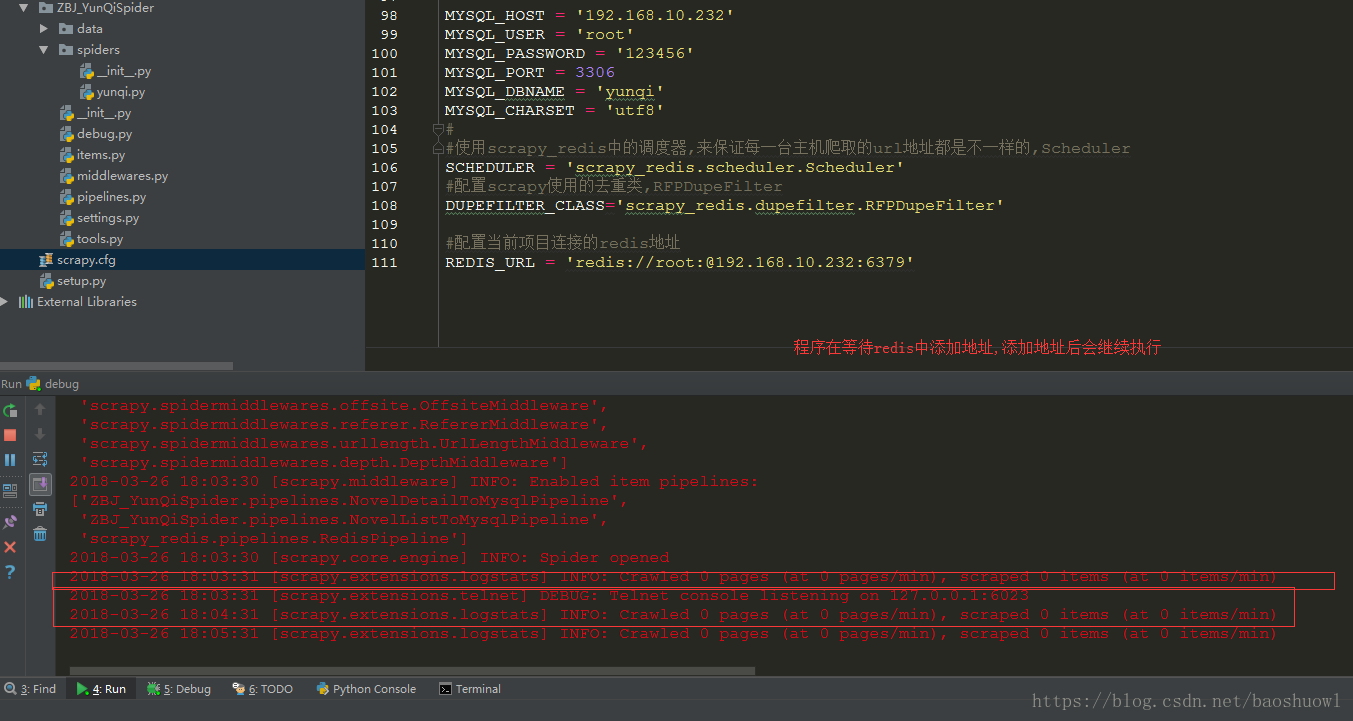
打開redis客戶端在redis添加key為yunqi:start_urls的列表,值為地址
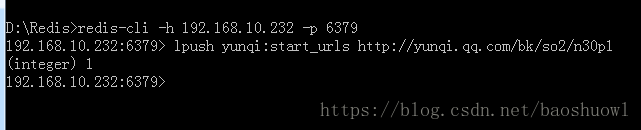
添加成功后,程序直接跑了起來
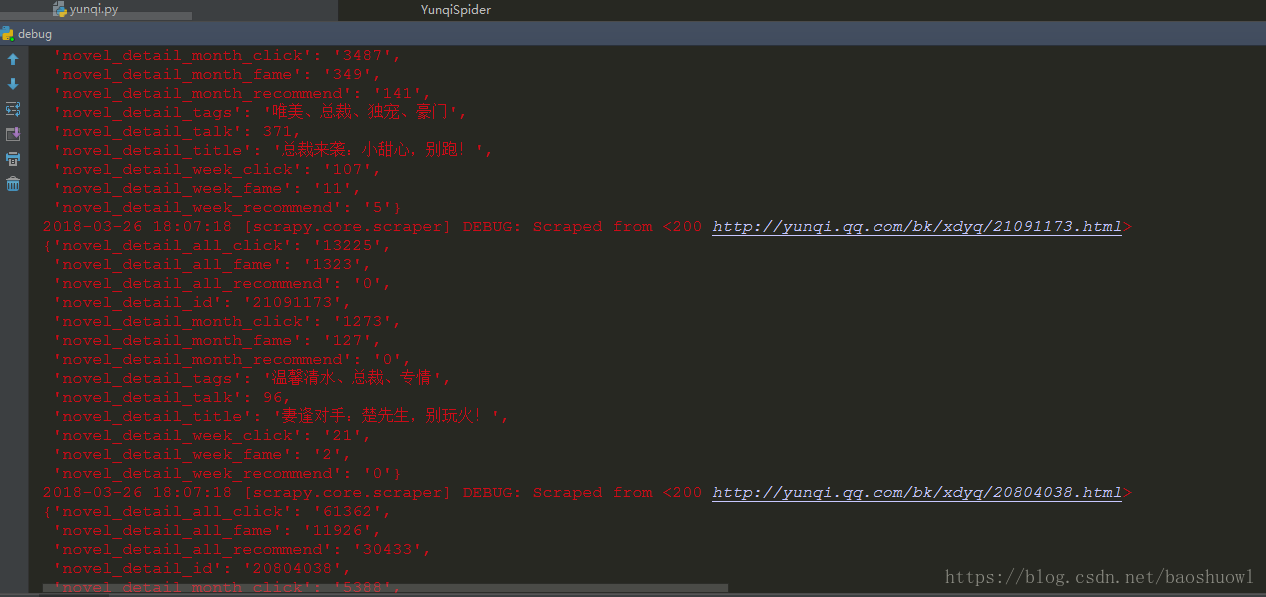
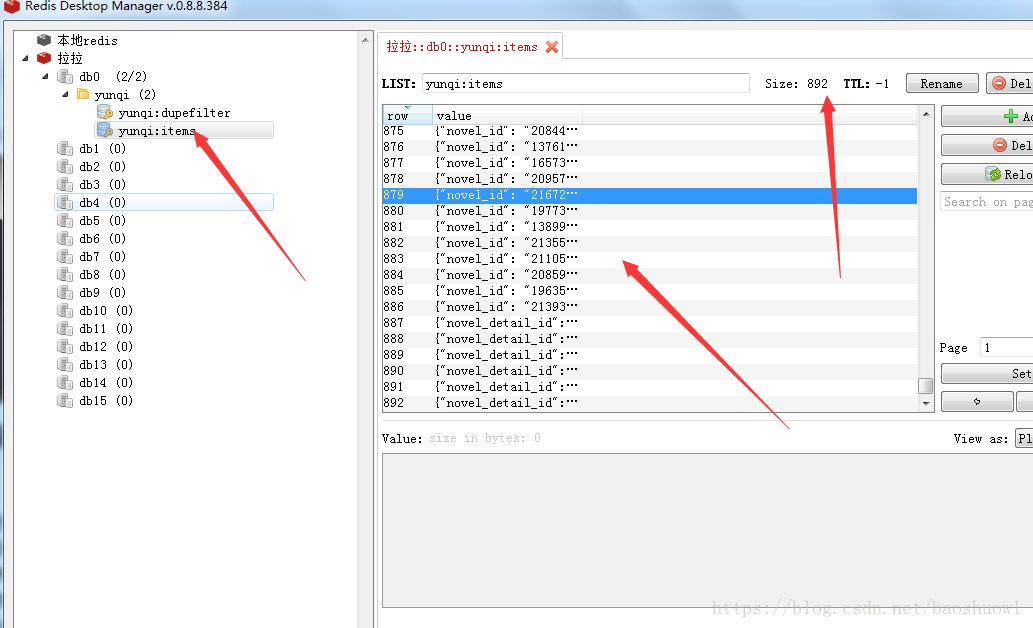
查看數據是否插入

分布式用到的代碼應該是同一套代碼
1) 先把項目配置為分布式
2) 把項目拷貝到多臺服務器中
3) 把所有爬蟲項目都跑起來
4) 在主redis-cli中lpush你的網址即可
5) 效果:所有爬蟲都開始運行,并且數據還都不一樣
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





