溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何運用爬蟲框架Scrapy部署爬蟲,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
這里主要講述如何將我們編寫的爬蟲程序部署到生產環境中。我們使用由 scrapy 官方提供的爬蟲管理工具 scrapyd 來部署爬蟲程序。
一是它由 scrapy 官方提供的,二是我們使用它可以非常方便地運用 JSON API來部署爬蟲、控制爬蟲以及查看運行日志。
選擇一臺主機當做服務器,安裝并啟動 scrapyd 服務。再這之后,scrapyd 會以守護進程的方式存在系統中,監聽爬蟲地運行與請求,然后啟動進程來執行爬蟲程序。
使用 pip 能比較方便地安裝 scrapyd。
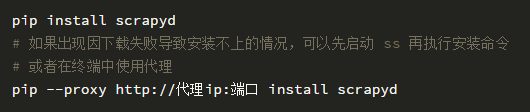
在終端命令行下以下命令來啟動服務:

啟動服務結果如下:

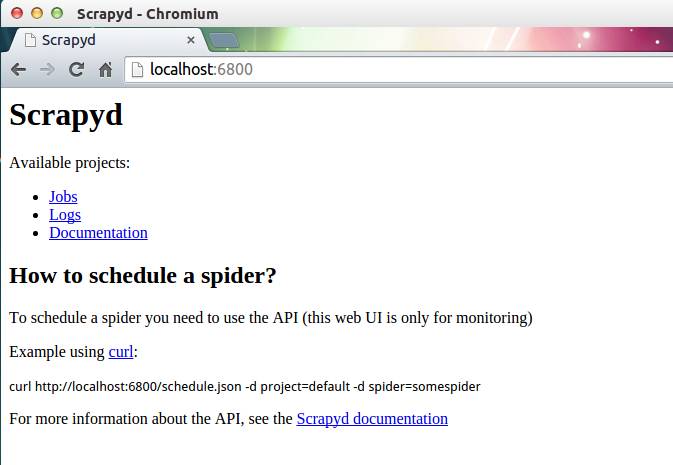
scrapyd 也提供了 web 的接口。方便我們查看和管理爬蟲程序。默認情況下 scrapyd 監聽 6800 端口,運行 scrapyd 后。在本機上使用瀏覽器訪問 http://localhost:6800/地址即可查看到當前可以運行的項目。
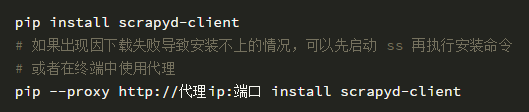
直接使用 scrapyd-client 提供的 scrapyd-deploy 工具
scrapyd 是運行在服務器端,而 scrapyd-client 是運行在客戶端。客戶端使用 scrapyd-client 通過調用 scrapyd 的 json 接口來部署爬蟲項目。
在終端下運行以下安裝命令:
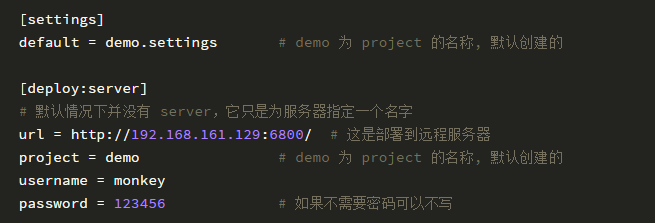
修改工程目錄下的 scrapy.cfg 文件。
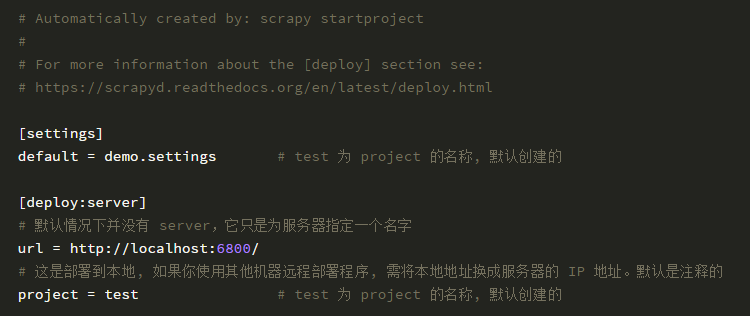
如果你服務器有配置 HTTP basic authentication 驗證,那么需要在 scrapy.cfg 文件增加用戶名和密碼。這是用于登錄服務器用的。
在爬蟲項目根目錄下執行下面的命令:

其中 target 為上一步配置的服務器名稱,project 為項目名稱,可以根據實際情況自己指定。
我指定 target 為 server,project 為 demo,所以我要執行的命令如下:

部署操作會打包你的當前項目,如果當前項目下有setup.py文件,就會使用它,沒有的會就會自動創建一個。(如果后期項目需要打包的話,可以根據自己的需要修改里面的信息,也可以暫時不管它). 從返回的結果里面,我們可以看到部署的狀態,項目名稱,版本號和爬蟲個數,以及當前的主機名稱.
運行結果如下:

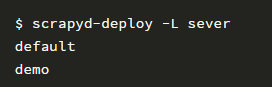
使用以下命令檢查部署爬蟲結果:

我指定服務器名稱為 server,所以要執行命令如下:
刷新 http://localhost:6800/ 頁面, 也可以看到Available projects: demo的字樣。
scrapyd 的 web 界面比較簡單,主要用于監控,所有的調度工作全部依靠接口實現。官方推薦使用 curl 來管理爬蟲。
所以要先安裝 curl。
windows 用戶可以到該網站https://curl.haxx.se/download.html下載 curl 安裝包進行安裝。
ubuntu/Mac 用戶直接使用命令行安裝即可。
在爬蟲項目的根目錄下,使用終端運行以下命令:

成功啟動爬蟲結果如下:





關于如何運用爬蟲框架Scrapy部署爬蟲就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





