溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Lucene倒排索引原理是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Lucene倒排索引原理是什么”吧!
這里引用百度百科的介紹:
搜索引擎(Search Engine)是指根據一定的策略、運用特定的計算機程序從互聯網上搜集信息,在對信息進行組織和處理后,為用戶提供檢索服務,將用戶檢索相關的信息展示給用戶的系統。
搜索引擎包括全文索引、目錄索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、門戶搜索引擎與免費鏈接列表等。
本文主要介紹全文索引,即百度使用的搜索引擎分類。
全文索引
首先是數據庫中數據的搜集,搜索引擎的自動信息搜集功能分兩種:
一種是定期搜索,即每隔一段時間(比如Google一般是28天),搜索引擎主動派出“蜘蛛”程序,對一定IP地址范圍內的互聯網網站進行檢索,一旦發現新的網站,它會自動提取網站的信息和網址加入自己的數據庫。
另一種是提交網站搜索,即網站擁有者主動向搜索引擎提交網址,它在一定時間內(2天到數月不等)定向向你的網站派出“蜘蛛”程序,掃描你的網站并將有關信息存入數據庫,以備用戶查詢。
當用戶以關鍵詞查找信息時,搜索引擎會在數據庫中進行搜尋,如果找到與用戶要求內容相符的網站,便采用特殊的算法——通常根據網頁中關鍵詞的匹配程度、出現的位置、頻次、鏈接質量——計算出各網頁的相關度及排名等級,然后根據關聯度高低,按順序將這些網頁鏈接返回給用戶。這種引擎的特點是搜全率比較高。
高效查詢數據(運用多種算法查詢數據,查詢速率是毫秒級別,無論是千萬條數據還是上億的數據)
比較容易,將普通的數據庫切換成搜索引擎比較容易。
大數據量、時效性、高并發等等。
數據庫達到百萬數據級別的時候
要求檢索時效性、性能要求高,Ms級響應
接下來看在平常的互聯網中搜索引擎的應用Solr。那么什么是Solr呢?它和es相比有什么優點和不足呢?
我們先來簡單地介紹一下solr:
Solr是一個基于Lucene的全文搜索服務器。同時對其進行了擴展,提供了比Lucene更為豐富的面向使用的查詢語言,同時實現了可配置、可擴展并對查詢性能進行了優化,并且提供了一個完善的功能管理界面。它支持Xml/Http協議,支持JSONAPI接口。
它具有如下特點:
可擴展性:Solr可以把建立索引和查詢處理的運算分布到一個集群內的多臺服務器上。
快速部署:Solr是開源軟件,安裝和配置都很方便,可以根據安裝包內的Sample配置直接上手,可分為單機和集群模式。
海量數據:Solr是針對億級以上的海量數據處理而設計的,可以很好地處理海量數據檢索。
優化的搜索功能:Solr搜索速度夠快,對于復雜的搜索查詢Solr可以做到毫秒級的處理,通常,幾十毫秒就能處理完一次復雜查詢。
接下來,我們將了解分詞是如何實現的。那么,我們為什么要去分詞呢,這和搜索引擎有什么關系呢?我們在搜索框里輸入的幾個詞或者一段話是如何拆成多個關鍵字的呢?
大家聽說過哪些分詞器嗎?比如lucene自帶的中文分詞器smartcn,還有最常用的IK分詞器等等,今天我們主要講一下IK分詞器。
IK分詞器首先會維護幾個詞典來記錄一些常用的詞,如主詞表:main2012.dic、量詞表quantifier.dic、停用詞stopword.dic。
Dictionary為字典管理類中,分別加載了這個詞典到內存結構中。具體的字典代碼,位于org.wltea.analyzer.dic.DictSegment。 這個類實現了一個分詞器的一個核心數據結構,即Tire Tree。
Tire Tree(字典樹)是一種結構相當簡單的樹型結構,用于構建詞典,通過前綴字符逐一比較對方式,快速查找詞,所以有時也稱為前綴樹。具體的例子如下。
舉例
比如:我是北京海淀區中關村的中國人民。
我們設置的詞典是:北京、海淀區、中關村、中國、中國人民,那么根據詞典組成的字典樹如圖所示:
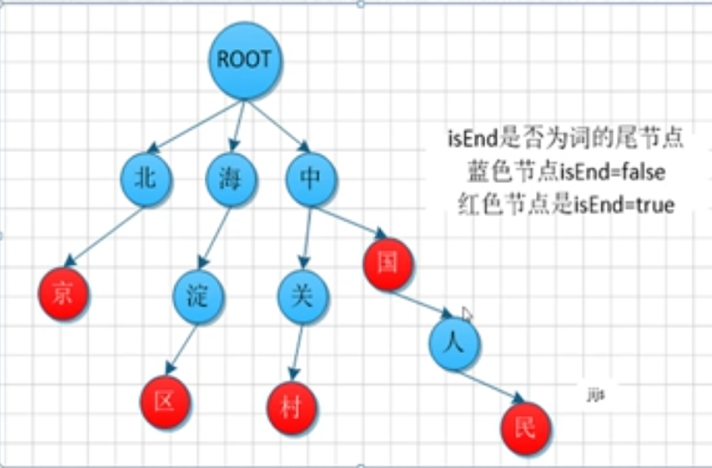
然后我們根據這個字典樹來對這段話進行詞語切分。IK分詞器中,基本可以分為兩種模式:一種是smart模式、一種是非smart模式,可以在代碼中初始化的時候去配置。
我們其實不用解釋這兩種模式的字面含義,直接打印兩種模式的結果就可以看出來:
原句:我是北京海淀區中關村的中國人民
smart模式:北京、海淀區、中關村、中國人民
非smart模式:北京、海淀區、中關村、中國、中國人民
顯而易見,非smart模式是將能夠分出來的詞全部輸出;smart模式是根據內在的方法輸出一個合理的分詞結果,這就涉及到了歧義判斷。
舉例
舉個更有代表性的例子:張三說的確實在理。
根據正向匹配可能的詞元鏈:
L1:{張三,張,三}
L2:{說}
L3:{的確,的,確實,確,實在,實,在理,在,理}
首來看一下最基本的一些元素結構類:
public class Lexeme implements Comparable{
……
//詞元的起始位移
private int offset;
//詞元的相對起始位置
private int begin;
//詞元的長度
private int length;
//詞元文本
private String lexemeText;
//詞元類型
private int lexemeType;
……
}這里的Lexeme(詞元),可以理解為是一個詞語或單詞。其中的begin,是指其在輸入文本中的位置。注意,它是實現Comparable的,起始位置靠前的優先,長度較長的優先,這可以用來決定一個詞在一條分詞結果的詞元鏈中的位置,可以用于得到上面例子中分詞結果中的各個詞的順序。
/*
* 詞元在排序集合中的比較算法
* @see java.lang.Comparable#compareTo(java.lang.Object)
*/
public int compareTo(Lexeme other) {
//起始位置優先
if(this.begin < other.getBegin()){
return -1;
}else if(this.begin == other.getBegin()){
//詞元長度優先
if(this.length > other.getLength()){
return -1;
}else if(this.length == other.getLength()){
return 0;
}else {//this.length < other.getLength()
return 1;
}
}else{//this.begin > other.getBegin()
return 1;
}
}smart模式歧義消除算法:
詞元位置權重比較(詞元長度積),含義是選取長的詞元位置在后的集合
L31:{的,確實,在理}1*1+2*2+3*2=11
L32:{的確,實,在理} 1*2+2*1+3*2=10
L33:{的確,實在,理} 1*2+2*2+3*1=9
最后的分詞結果:張三,說,的,確實,在理
我們可以把倒排索引算法想象成查字典時的目錄一樣,我們知道需要查的字的目錄后,就會很快地查找到。如果用專業的語言解釋的話就是:
倒排索引源于實際應用中需要根據屬性的值來查找記錄。這種索引表中的每一項都包括一個屬性值和具有該屬性值的各記錄的地址。由于不是由記錄來確定屬性值,而是由屬性值來確定記錄的位置,因而稱為倒排索引(inverted index)。帶有倒排索引的文件我們稱為倒排索引文件,簡稱倒排文件(inverted file)。
倒排文件(倒排索引),索引對象是文檔或者文檔集合中的單詞等,用來存儲這些單詞在一個文檔或者一組文檔中的存儲位置,是對文檔或者文檔集合的一種最常用的索引機制。
搜索引擎的關鍵步驟就是建立倒排索引,倒排索引一般表示為一個關鍵詞,然后是它的頻度(出現的次數),位置(出現在哪一篇文章或網頁中,及有關的日期,作者等信息),它相當于為互聯網上幾千億頁網頁做了一個索引,好比一本書的目錄、標簽一般。讀者想看哪一個主題相關的章節,直接根據目錄即可找到相關的頁面。不必再從書的第一頁到最后一頁,一頁一頁地查找。
Lucerne是一個開放源代碼的高性能的基于java的全文檢索引擎工具包,不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎,部分文本分析引擎。目的是為軟件開發人員提供一個簡單易用的工具包,以方便在目標系統中實現全文檢索的功能,或者以此為基礎建立起完整的全文檢索引擎。
假設有兩篇文章1和2:
文章1的內容為: Jack lives in BeiJing,I live in BeiJing too. 文章2的內容為: He lived in Taiyuan.
1)取得關鍵詞
首先我們要用我們之前講的方式分詞,然后由于英文的原因,我們需要將in、on、of這些沒用實際意義的詞過濾掉,然后將第三人稱單數加s或者過去式加ed這些詞還原回去,如lived變回live,lives變回live,然后把不需要的標點符號也去掉。經過上面的處理之后,剩下的關鍵字為:
文章1的所有關鍵詞為:[Jack] [live] [BeiJing] [i] [live] [BeiJing]
文章2的所有關鍵詞為:[he] [live] [Taiyuan]
2)建立倒排索引
關鍵詞 文章號[出現頻率] 出現位置 BeiJing 1[2] 3,6 he 2[1] 1 i 1[1] 4 live 1[2] 2,5, 2[1] 2 Taiyuan 2[1] 3 tom 1[1] 1
以上就是lucene索引結構中最核心的部分。我們注意到關鍵字是按字符順序排列的(lucene沒有使用B樹結構),因此lucene可以用二元搜索算法快速定位關鍵詞。
實現時,lucene將上面三列分別作為詞典文件(Term Dictionary)、頻率文件(frequencies)、位置文件 (positions)保存。其中詞典文件不僅保存有每個關鍵詞,還保留了指向頻率文件和位置文件的指針,通過指針可以找到該關鍵字的頻率信息和位置信息。
為了減小索引文件的大小,Lucene對索引還使用了壓縮技術。
首先,對詞典文件中的關鍵詞進行了壓縮,關鍵詞壓縮為<前綴長度,后綴>,例如:當前詞為“阿拉伯語”,上一個詞為“阿拉伯”,那么“阿拉伯語”壓縮為<3,語>。
其次大量用到的是對數字的壓縮,數字只保存與上一個值的差值(這樣可以減小數字的長度,進而減少保存該數字需要的字節數)。例如當前文章號是16389(不壓縮要用3個字節保存),上一文章號是16382,壓縮后保存7(只用一個字節)。
假設要查詢單詞 “live”,lucene先對詞典二元查找、找到該詞,通過指向頻率文件的指針讀出所有文章號,然后返回結果。詞典通常非常小,因而,整個過程的時間是毫秒級的。
而用普通的順序匹配算法,不建索引,而是對所有文章的內容進行字符串匹配,這個過程將會相當緩慢,當文章數目很大時,時間往往是無法忍受的。
我們在windows系統中安裝solr。
解壓后:
cmd 進入solr的bin目錄,使用命令 solr start(為了更方便,可以配置solr的環境變量,配好后可以直接在cmd中使用solr命名)

看到這個界面,說明solr服務啟動成功,端口號為 8983,訪問 http://localhost:8983,會自動跳轉到http://localhost:8983/solr/#/
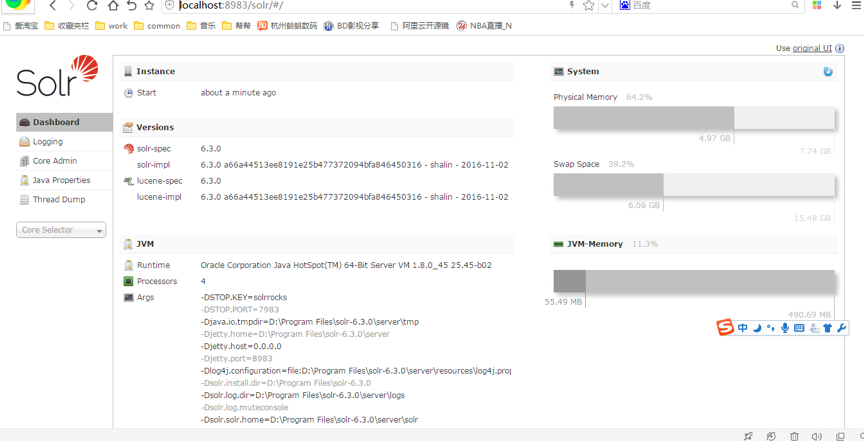
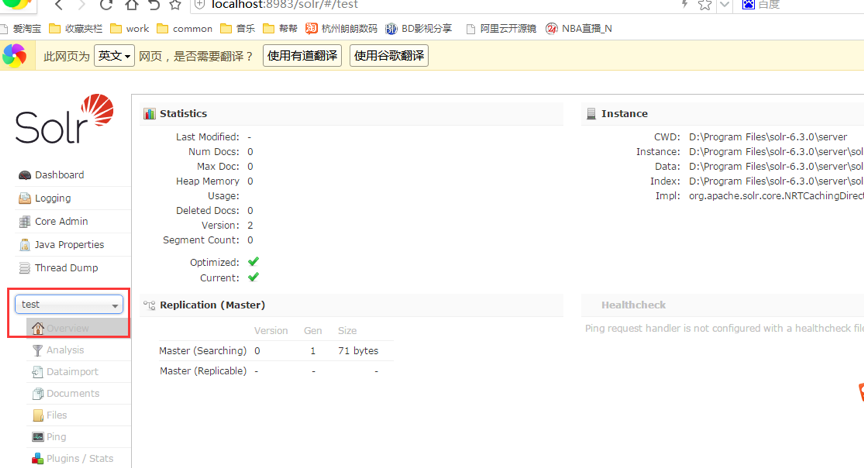
在這個頁面會顯示 solr的基本信息,lucene信息,Java信息等
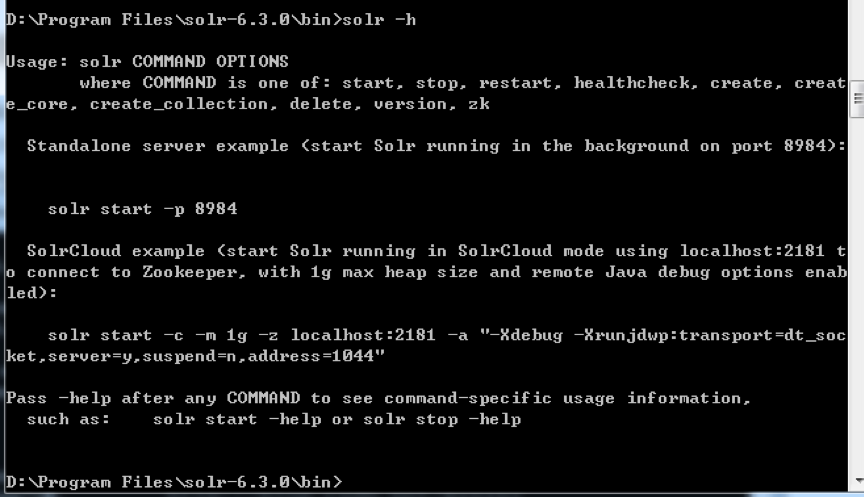
然后我們介紹一個solr的指令: solr -h 可以看到solr的基本信息
配置solr
配置核心core
solr create -c mycore -d baisc_configs:-c參數指定定義的核心名稱,-d參數指定配置目錄
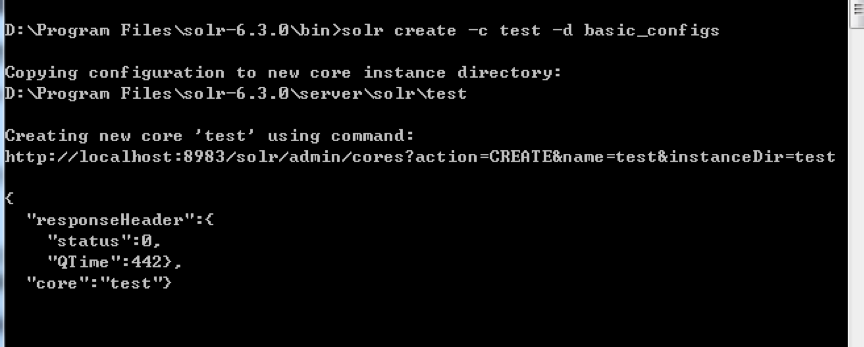
執行該命令后,會多出一個test目錄。
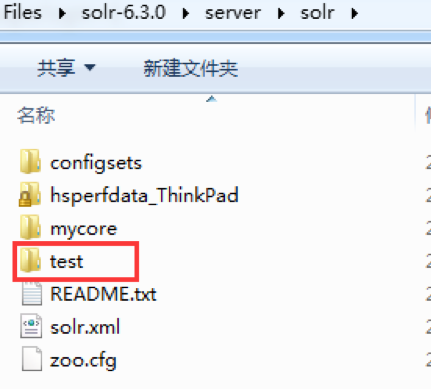
訪問Solr Admin頁面:http://localhost:8983/,查看core,多了一個 test
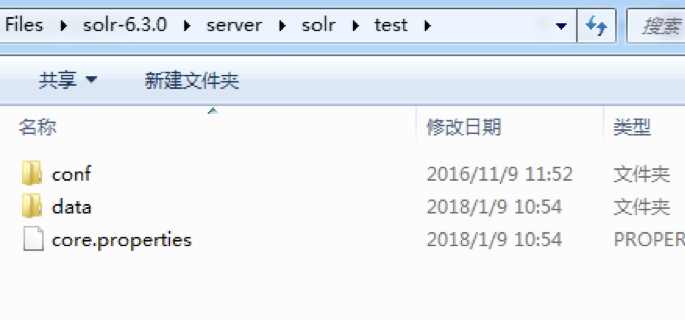
在\solr-6.3.0\server\solr\test目錄下有conf和data目錄,分別對應配置和數據。
給core添加數據
打開目錄:\solr-6.3.0\server\solr\test\conf,添加一個字段:
<field name="name" type="string" indexed="false" stored="true" required="true" multiValued="false" />
然后重啟solr: solr restart -p 8983
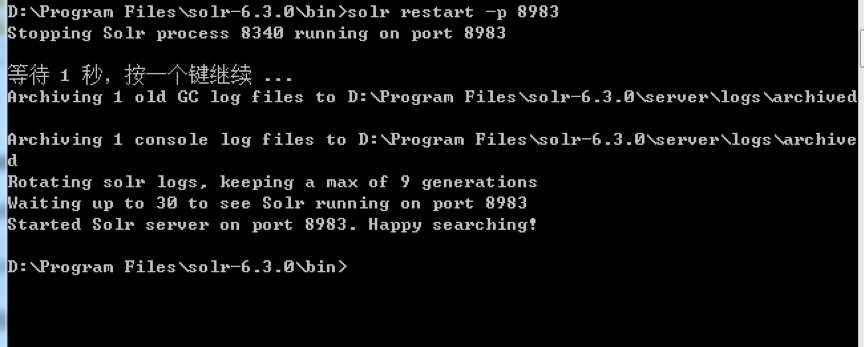
到Solr Admin頁面,選擇core-test-document,在Document(s)中填寫數據:
{
"id":"1",
"name":"寶馬"
}點擊submit,返回Status: success,則代表添加數據成功。

多加幾條后,點擊Query,查詢數據:
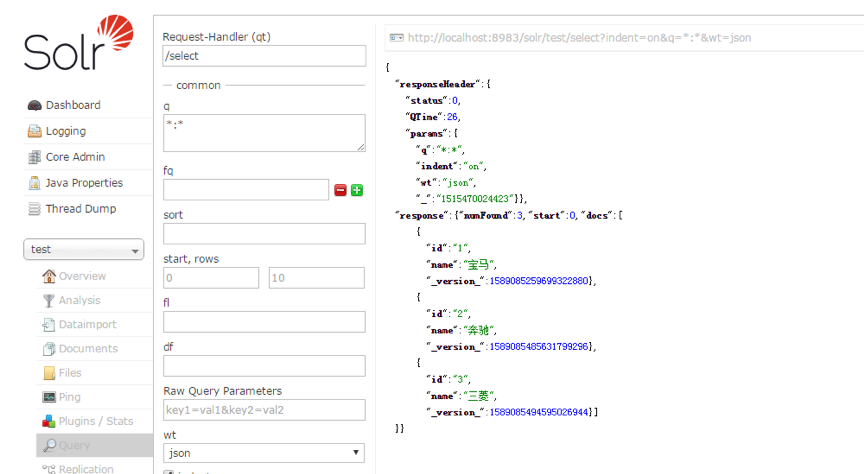
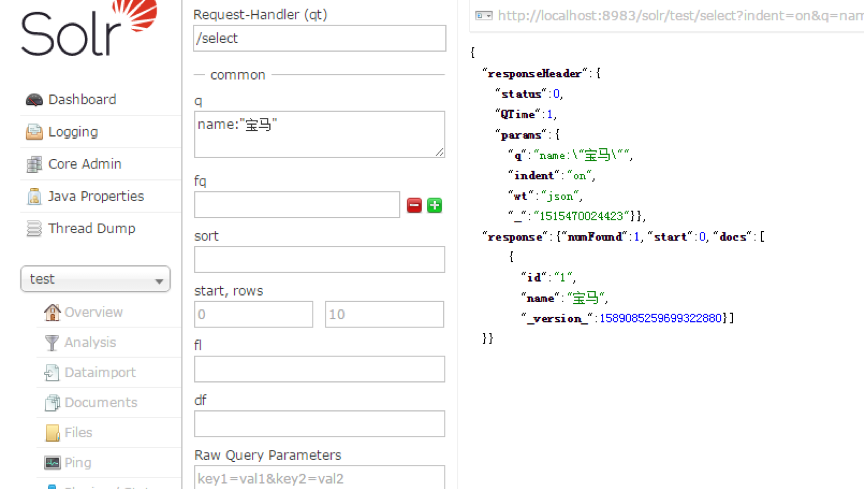
查詢界面的 q,代表 查詢條件,如輸入:name:"寶馬",再次執行查詢
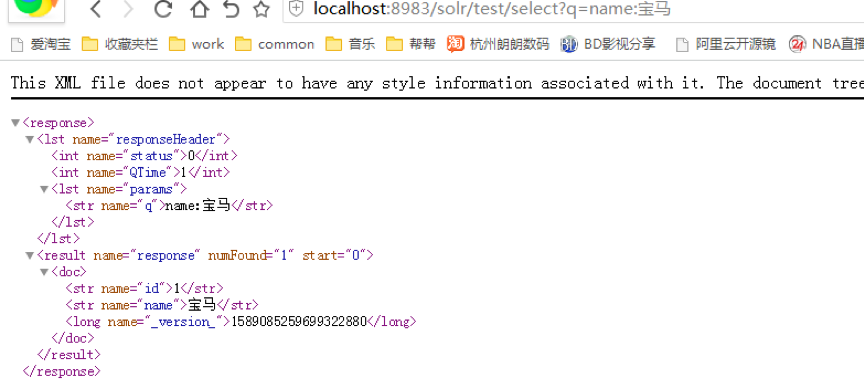
也可以直接get方式訪問url:http://localhost:8983/solr/test/select?q=name:寶馬
到此,相信大家對“Lucene倒排索引原理是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





