溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Elasticsearch中的倒排索引結構是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Elasticsearch中的倒排索引結構是什么”吧!
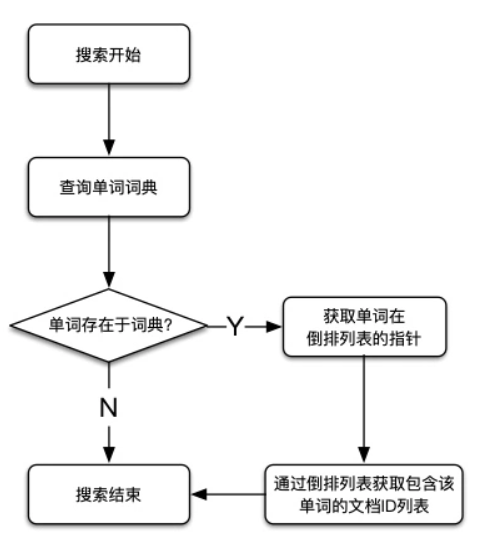
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地來講,正向索引是通過key找value,反向索引則是通過value找key。
先來回憶一下我們是怎么插入一條索引記錄的:
curl -X PUT "localhost:9200/user/_doc/1" -H 'Content-Type: application/json' -d'
{
"name" : "Jack",
"gender" : 1,
"age" : 20
}
'其實就是直接PUT一個JSON的對象,這個對象有多個字段,在插入這些數據到索引的同時,Elasticsearch還為這些字段建立索引——倒排索引,因為Elasticsearch最核心功能是搜索。
那么,倒排索引是個什么樣子呢?

倒排索引由兩部分構成:
單詞詞典
倒排列表
它的結構如下:
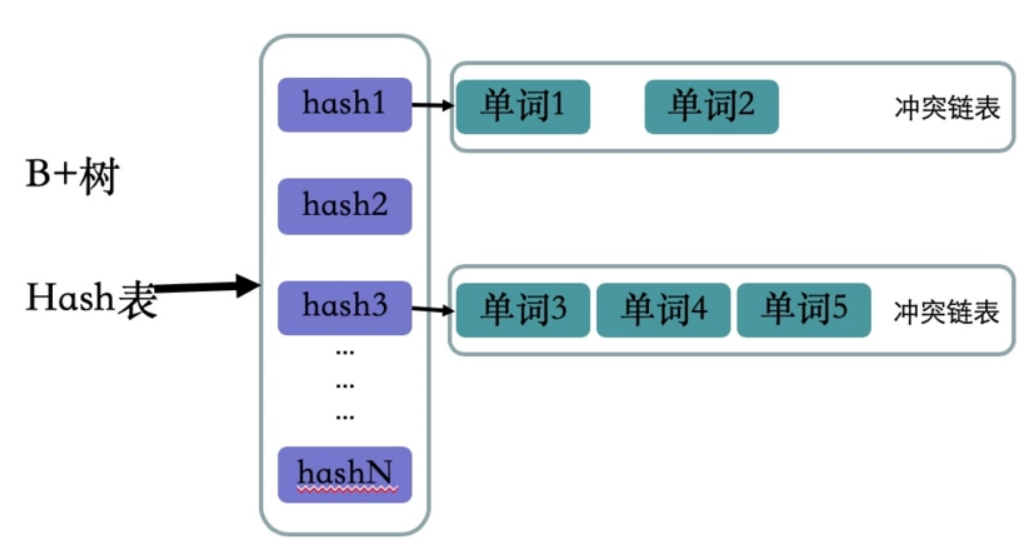
單詞詞典有兩種數據結構實現:B+樹和Hash表
B+樹和Mysql索引結構中主鍵索引數據結構一樣,這里就不再介紹了
哈希表的key是單詞的hash值,值是單詞的鏈表,因為hash算法會有沖突的情況發生,所以這里的值是一個集合,里面保存著相同hash值得單詞以及改詞指向倒排列表的指針
倒排列表特性:
記錄出現過某個單詞的文檔列表
同時還記錄單詞在所有文檔中的出現次數和偏移位置
倒排列表元素數據結構:
(DocID;TF;<POS>)
其中:
DocID:出現某單詞的文檔ID
TF(Term Frequency):單詞在該文檔中出現的次數
POS:單詞在文檔中的位置
有下面單個文檔
| - | 內容 |
|---|---|
| 文檔1 | 百度的年度目標 |
| 文檔2 | AI技術生態部的年度目標 |
| 文檔3 | AI市場的年度目標 |
則他們生成的倒排索引
| 單詞ID | 單詞 | 逆向文檔頻率 | 倒排列表(DocID;TF;<POS>) |
|---|---|---|---|
| 1 | 目標 | 3 | (1;1;<3>),(2;1;<5>),(3;1;<4>) |
| 2 | 年度 | 3 | (1;1;<2>),(2;1;<4>),(3;1;<3>) |
| 3 | AI | 2 | (2;1;<1>),(3;1;<1>) |
| 4 | 技術 | 1 | (2;1;<2>) |
| 5 | 生態 | 1 | (2;1;<3>) |
| 6 | 市場 | 1 | (3;1;<2>) |
比如單詞“年度”,單詞ID為2,在三個文檔中出現過,所以逆向文檔頻率為3,同時倒排索引中的元素也有三個:(1;1;<2>),(2;1;<4>),(3;1;<3>)。拿第一個元素(1;1;<2>)進行說明,他表示“年度”再文檔ID為1的文檔中出現過1次,出現的位置是第二個單詞
首先,來搞清楚幾個概念,為此,舉個例子:
假設有個user索引,它有四個字段:分別是name,gender,age,address。畫出來的話,大概是下面這個樣子,跟關系型數據庫一樣

Term(單詞):一段文本經過分析器分析以后就會輸出一串單詞,這一個一個的就叫做Term(直譯為:單詞)
Term Dictionary(單詞字典):顧名思義,它里面維護的是Term,可以理解為Term的集合
Term Index(單詞索引):為了更快的找到某個單詞,我們為單詞建立索引
Posting List(倒排列表):倒排列表記錄了出現過某個單詞的所有文檔的文檔列表及單詞在該文檔中出現的位置信息,每條記錄稱為一個倒排項(Posting)。根據倒排列表,即可獲知哪些文檔包含某個單詞。(PS:實際的倒排列表中并不只是存了文檔ID這么簡單,還有一些其它的信息,比如:詞頻(Term出現的次數)、偏移量(offset)等,可以想象成是Java中的對象)
(PS:如果類比現代漢語詞典的話,那么Term就相當于詞語,Term Dictionary相當于漢語詞典本身,Term Index相當于詞典的目錄索引)
我們知道,每個文檔都有一個ID,如果插入的時候沒有指定的話,Elasticsearch會自動生成一個,因此ID字段就不多說了
上面的例子,Elasticsearch建立的索引大致如下:
name字段:

gender字段:

Elasticsearch分別為每個字段都建立了一個倒排索引。比如,在上面“張三”、“北京市”、22 這些都是Term,而[1,3]就是Posting List。Posting list就是一個數組,存儲了所有符合某個Term的文檔ID。
只要知道文檔ID,就能快速找到文檔。可是,要怎樣通過我們給定的關鍵詞快速找到這個Term呢?
當然是建索引了,為Terms建立索引,最好的就是B-Tree索引(PS:MySQL就是B樹索引最好的例子)。
首先,讓我們來回憶一下MyISAM存儲引擎中的索引是什么樣的:

我們查找Term的過程跟在MyISAM中記錄ID的過程大致是一樣的
MyISAM中,索引和數據是分開,通過索引可以找到記錄的地址,進而可以找到這條記錄
在倒排索引中,通過Term索引可以找到Term在Term Dictionary中的位置,進而找到Posting List,有了倒排列表就可以根據ID找到文檔了
(PS:可以這樣理解,類比MyISAM的話,Term Index相當于索引文件,Term Dictionary相當于數據文件)
(PS:其實,前面我們分了三步,我們可以把Term Index和Term Dictionary看成一步,就是找Term。因此,可以這樣理解倒排索引:通過單詞找到對應的倒排列表,根據倒排列表中的倒排項進而可以找到文檔記錄)
實際的 term index 是一棵 trie 樹:
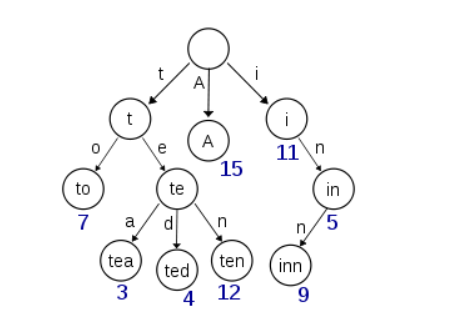
例子是一個包含 "A", "to", "tea", "ted", "ten", "i", "in", 和 "inn" 的 trie 樹。這棵樹不會包含所有的 term,它包含的是 term 的一些前綴。通過 term index 可以快速地定位到 term dictionary 的某個 offset,然后從這個位置再往后順序查找。再加上一些壓縮技術(搜索 Lucene Finite State Transducers) term index 的尺寸可以只有所有 term 的尺寸的幾十分之一,使得用內存緩存整個 term index 變成可能。整體上來說就是這樣的效果。

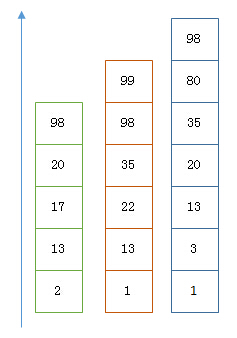
以上是三個 posting list。我們現在需要把它們用 AND 的關系合并,得出 posting list 的交集。首先選擇最短的 posting list,然后從小到大遍歷。遍歷的過程可以跳過一些元素,比如我們遍歷到綠色的 13 的時候,就可以跳過藍色的 3 了,因為 3 比 13 要小。
整個過程如下
Next -> 2 Advance(2) -> 13 Advance(13) -> 13 Already on 13 Advance(13) -> 13 MATCH!!! Next -> 17 Advance(17) -> 22 Advance(22) -> 98 Advance(98) -> 98 Advance(98) -> 98 MATCH!!!
最后得出的交集是 [13,98],所需的時間比完整遍歷三個 posting list 要快得多。但是前提是每個 list 需要指出 Advance 這個操作,快速移動指向的位置。什么樣的 list 可以這樣 Advance 往前做蛙跳?skip list:
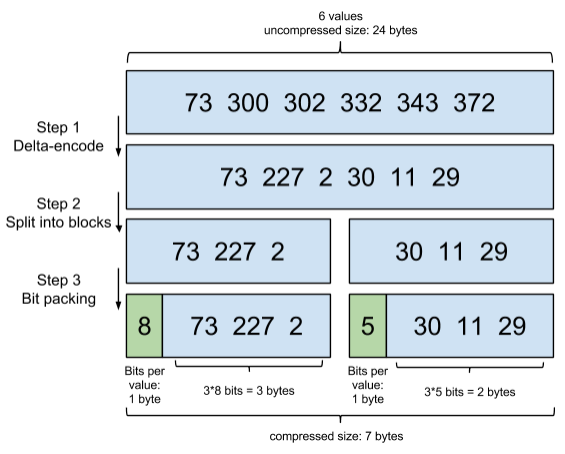
考慮到頻繁出現的 term(所謂 low cardinality 的值),比如 gender 里的男或者女。如果有 1 百萬個文檔,那么性別為男的 posting list 里就會有 50 萬個 int 值。用 Frame of Reference 編碼進行壓縮可以極大減少磁盤占用。這個優化對于減少索引尺寸有非常重要的意義。當然 mysql b-tree 里也有一個類似的 posting list 的東西,是未經過這樣壓縮的。
因為這個 Frame of Reference 的編碼是有解壓縮成本的。利用 skip list,除了跳過了遍歷的成本,也跳過了解壓縮這些壓縮過的 block 的過程,從而節省了 cpu。
Bitset 是一種很直觀的數據結構,對應 posting list 如:
[1,3,4,7,10]
對應的 bitset 就是:
[1,0,1,1,0,0,1,0,0,1]
每個文檔按照文檔 id 排序對應其中的一個 bit。Bitset 自身就有壓縮的特點,其用一個 byte 就可以代表 8 個文檔。所以 100 萬個文檔只需要 12.5 萬個 byte。但是考慮到文檔可能有數十億之多,在內存里保存 bitset 仍然是很奢侈的事情。而且對于個每一個 filter 都要消耗一個 bitset,比如 age=18 緩存起來的話是一個 bitset,18<=age<25 是另外一個 filter 緩存起來也要一個 bitset。
所以秘訣就在于需要有一個數據結構:
可以很壓縮地保存上億個 bit 代表對應的文檔是否匹配 filter;
這個壓縮的 bitset 仍然可以很快地進行 AND 和 OR 的邏輯操作。
Lucene 使用的這個數據結構叫做 Roaring Bitmap。
到此,相信大家對“Elasticsearch中的倒排索引結構是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





