溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文根據沈劍在2018年10月18日【第十屆中國系統架構師大會(SACC2018)】現場演講內容整理而成。
講師介紹:

沈劍,快狗打車CTO,互聯網架構技術專家,“架構師之路”公眾號作者。曾任百度高級工程師,58同城高級架構師,58同城技術委員會主席。2015年調至58到家任高級總監,技術委員會主席,負責基礎架構,技術平臺,運維安全,信息系統等后端技術體系搭建。現任快狗打車CTO,負責快狗打車技術體系的搭建,本質是技術人一枚。
本文摘要:
沈劍分享了快狗打車數據庫架構的一致性實踐,在一致性實踐的過程中,能夠體現快狗打車數據庫架構的演進歷程。從單庫到多庫再到高可用等等,包括在研究的過程中,每個階段可能會碰到不同的問題,快狗打車是采用一些什么樣的技術手段去解決這些問題?以快狗打車的實踐跟大家做一些分享。
分享大綱:
主從不一致,優化實踐
緩存不一致,優化實踐
數據冗余不一致,優化實踐
多庫事務不一致,優化實踐
總結
演講正文:
快狗打車(原58速運)是一個創業型公司,技術架構、技術體系、數據庫架構的變遷,和在座很多公司是很相近的,今天和大家聊一聊,我們在快狗打車數據庫架構一致性方面碰到一些問題。
不一致的優化歷程,也是數據庫架構演進的過程
主線是我們的數據庫架構變化的過程,在這個過程中,我列出了四個跟一致性相關的節點,主從會不一致、緩存會不一致、冗余數據會不一致、多庫多實例會不一致。不一致的優化歷程,也是我們數據庫架構演進的一個過程。從單庫到現在,有哪些坑在等著我們呢?

先看一下,最初的數據庫架構,最早是這個樣子的。那個時候沒有什么微服務分層, web通過DAO訪問一個單庫數據庫,最早我這么玩的。單庫,它不具備什么高可用,高并發特性,擴展性也比較差。我相信很多創業公司初期也是這樣。
單庫最早會遇到什么樣的瓶頸呢?在創業的時候,數據量變大了,并發量大了,業務變復雜了,整個系統的瓶頸最先出現在哪里?我的經驗是數據庫。數據庫的瓶頸又會在哪里?我的經驗是讀。因為絕大部分的業務是讀多寫少的業務,讀,最容易稱為系統的瓶頸。
最早在數據庫讀扛不住的時候,最先想到的優化方式是什么?互聯網公司都講快,今天出問題,能不能明天后天給我搞定?最先想到的方案是什么,如何能快速擴充數據庫的讀性能呢?
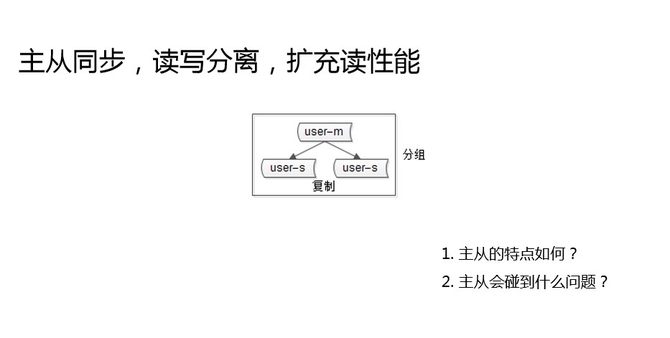
加兩個實例,主從同步,讀寫分離,這是創業型公司,當數據庫讀成為瓶頸的時候,最先想到的方案,快速擴充讀性能。主從同步碰到的問題是什么?這就是本主題要講的第一個問題,主從一致性的問題。
當數據量越來越多,吞吐量越來越大的時候,寫到了主庫,主庫同步到從庫,主從同步存在延時,在延時窗口期內,讀寫分離去讀從庫,就有可能讀到一個舊數據。這個問題,我相信大家也會碰到。
對于這個問題,不少接業務的解法方案是,忍,有些業務如果對一致性的要求沒這么高。但有沒有優化方案呢?
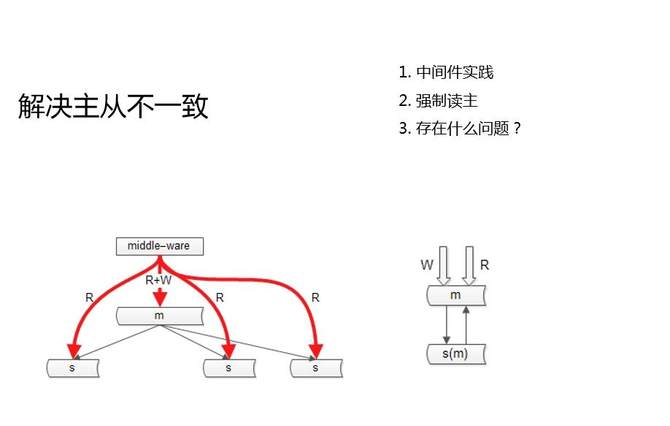
這兩個圖是我們的兩個常見的實踐。
第一個是中間件,我們的服務層或者站點層不直接調數據庫,通過一個中間層,去調數據庫。中間層它能夠知道哪一個庫,哪一個表,哪一個KEY發生了寫操作,如果說接下來的這一段時間(假設主從同步一秒鐘完成),有讀請求落到從庫上,就會讀到舊數據。那么此時,中間件就要將讀請求,路由到主庫上去,讀新數據。
第二個是強制讀主。第二個圖,雙主同步,強制讀主有什么好處?第一解決了高可用問題,雙主使用同一個VIP,一個主庫如果掛了,另一個主庫能隨時頂上,保障高可用。第二避免了主從之間的不一致。
強制讀主它帶來的新的問題是什么呢?解決了一致性問題,但讀性能擴展的問題又來了,主庫抗讀寫,還是沒有解決讀性的擴大的問題。
除了增加從庫,互聯網公司還有一種常見的提升系統讀性能的方式,緩存加服務化。抽象出服務層,向調用方屏蔽底層數據庫的復雜性,屏蔽數據庫的高可用的復雜性,屏蔽緩存的復雜性,對業務層提供服務。
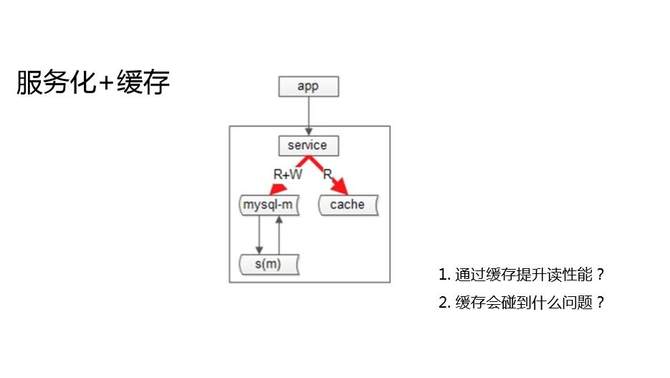
服務化加緩存確實是提升系統讀容量的架構方案。通過緩存來提升讀性,又會遇到什么新的問題呢?用主從架構,有主從不一致問題;用緩存架構,當然也有緩存不一致的問題。只要你把同一份數據放在了多個地方,多個地方的修改有時間差,這個時間差就會有數據訪問不一致的問題。
當我們出現數據庫與緩存中的數據不一致的時候,我們怎么來解決?
首先來看一下為什么會不一致。緩存的常用玩法是“Cache Aside Pattern”。Cache Aside Pattern,旁路緩存,一般是怎么玩的?淘汰緩存,而不是更新緩存,這是Cache Aside Pattern的結論。
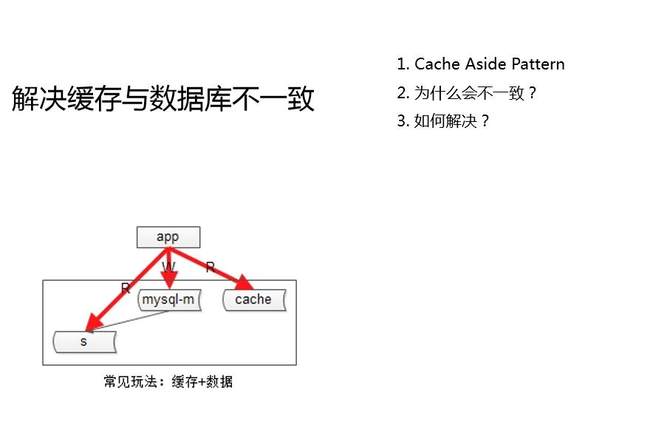
讀寫時序是什么樣的?對于讀請求有緩存,毫無爭議的,先讀緩存,如果數據命中我就直接返回,如果數據沒有命中,讀從庫讀寫分離,把這個數據從從庫里拿出,放到緩存里,這是讀請求的一個流程。
對于寫請求,Cache Aside Pattern的做法是,先寫數據庫,再淘汰緩存。在什么情況下會出現不一致?當并發量相對會比較高時,對于同一個KEY做了一個寫操作,馬上又來了一個讀操作,會出現什么樣的情況?先發生一個寫操作,先更新到數據庫,淘汰了Cache,馬上又來了一個讀操作,這個時候主從同步還沒同步完成,先讀緩存,緩存被剛剛的寫操作已經淘汰掉了,又去讀從庫,把從庫的臟數據拿過來放到緩存里去,不一致就出現。
高并發狀態下,寫后立即讀的場景,容易出現臟數據入Cache。
大家發現沒有,這里的數據不一致,比主從的數據不一致的情況更嚴重。主從不一致,只有一個主動同步時間差不一致,同步之后,從庫就能讀到新數據了。但是緩存與數據庫的不一致,它會導致后續一直不一致,一旦臟數據入了緩存,臟數據會延續到下一個寫發生的時候才會被淘汰掉,所以它其實更嚴重。
如何來解決呢?緩存和數據庫的數據不一致,我們的兩個實踐:異步淘汰緩存,確保從庫已經同步成功;設定超時時間,極限情況下有機會修正。
第一個,等從庫已經完全同步成功,再去異步淘汰緩存?只要監聽從庫的binlog,從庫binlog完成,一定是寫操作執行完畢,此時再淘汰緩存,就能避免時間差。
第二個,就是如果允許Cache miss,不要將緩存過期時間設為永久,如果你設置為無限長的過期時間,就沒有一個機會去修正不一致了。
隨著業務的發展,除了流量的增加,我們要提升系統的讀性能,我們要提升系統的數據庫高可用,還會面臨一個什么問題?對了,數據量會增大。我們業務數據量越來越大了,通常采用什么樣的方式去解決?創業型公司,這兩個方案應該是大家用得最多的。
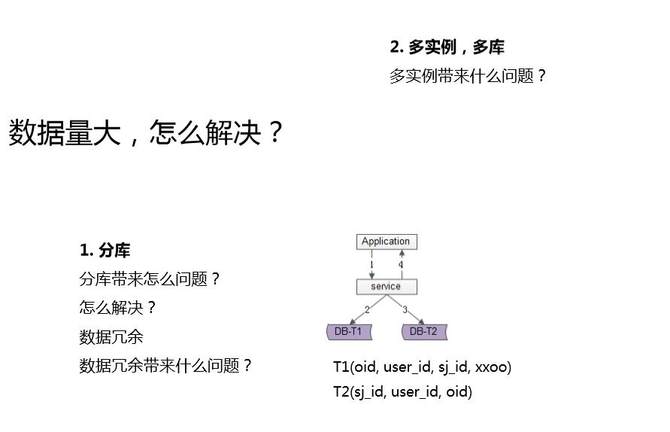
第一個,分庫。降低每個庫,降低每個實例的數據量,這樣就能夠承載更多的數據。分庫又帶來什么新的問題?舉了個例子,訂單一個庫,它有多個維度的查詢,有訂單ID的查詢,有用戶ID的查詢,有司機ID的查詢,一個庫沒有任何問題。
但分庫以后,變成多個庫以后,一旦用了一個維度分庫,你會發現其他的維度的查詢就要變成多個庫了,是不是?
一般來說是通過用戶的ID去分庫,在訂單ID里去放上分庫因子,這樣通過用戶ID以及訂單ID都能夠定位到相關數據。但是對于司機ID就不同了,司機ID和用戶ID是一個多對多的關系。一個用戶他可能下了多個司機的單,一個司機接了多個用戶的單,通過司機ID去查詢,并不能一次性查詢到所有的數據,同一個司機的訂單一定是分布在多個庫里。怎么辦呢?此時最常用解決方案是,數據冗余。
我用一個存儲元數據,用一個存儲關系數據,元數據通過用戶ID來分庫,保證同一個用戶的所有訂單在一個庫里。關系數據用司機ID來分庫,保證同一個司機的所有訂單在一個庫里。同一份數據,由于它存在兩個維度的查詢,這兩個維度查詢都可以不夸庫,而通過數據冗余來實現,這個在業內屬于很常見的方案。
數據冗余,又會出現什么問題?一起來看一下。上面是應用,中間是服務,一個數據存在兩個庫里,一個庫是通過用戶ID分庫,一個庫是通過司機ID去分庫,調用方來了一個請求,先要往第一份數據里寫一個數據,再往另外一個庫里寫一個冗余數據。能保證冗余數據的一致性么?是不能夠保證,這兩個庫同時寫成功的,那怎么辦呢?
這就是冗余數據的一致性問題。數據冗余數據的不一致優化,今天介紹三種方法,其實本質的方法論都是最終一致性。
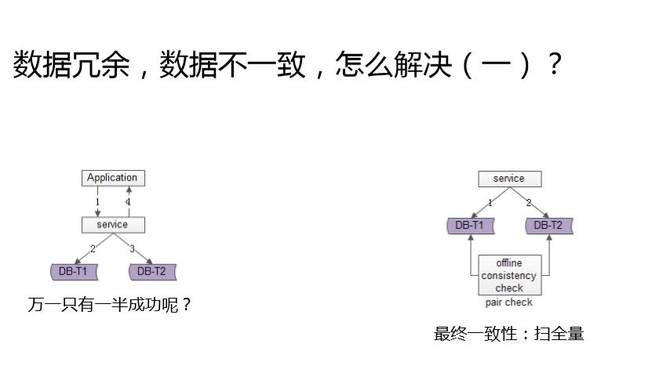
第一個方案是掃全量。怎么發現冗余數據不一致?寫個腳本,每天晚上跑,理論上A庫里有的B庫里面也有,一旦掃庫發現怎么A庫有B庫里沒有,就是出現不一致了,就要根據業務特性來做補償。到底是將后一半補進去,還是把前一半刪掉,跟業務特性相關,不過思路大致是這樣的,一個異步的方式,最終來保證一致性。
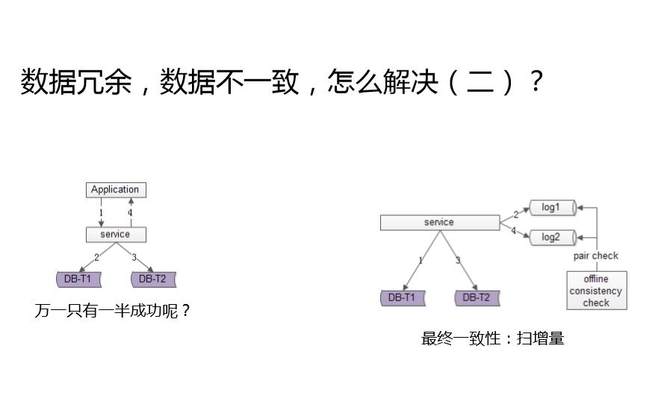
第二個方案是掃增量。通過服務操作兩個庫,寫成功第一個庫寫一條日志,寫成功第二個庫再寫一條日志。這些日志里的就是每天改變的數據,每天不用掃描全量,只要掃描每天改變的數據就行了。如果掃描日志不匹配,就通過異步的方式修復,保證最終一致性。
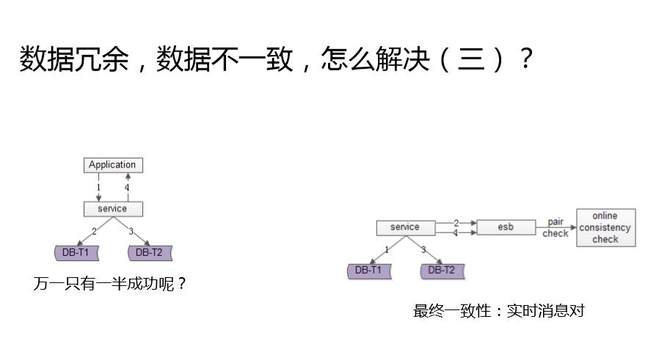
第三個方式,比前兩種方式更加實時。不寫日志了,而是發消息。用一個消息組件,數據庫正向表操作成功了,發一個消息,冗余表操作成功了,發另一個消息。用一個異步的服務去監聽這兩個消息,如果只有一條消息到達,就去數據庫檢測一致性,并用異步的方式來補償。

最后是多實例多庫,這也是解決數據量大的一個常見方案。它會帶來什么樣的不一致呢?這里有一個案例,下單的一個操作,可能有三個數據要修改,一個是余額的數據,我可能要扣減一些余額;一個是訂單的數據,要新增一條訂單;一個是流水的數據,要新增一條流水。原來是單庫事務來保證一致性,現在數據量大了,變成多個庫,余額是一個單獨的實例,訂單是一個單獨的實例,流水是一個單獨的實例,所以原來的一個事務,在多庫狀態下,就變成三個事務。
多實例,多庫事務,不一致,怎么辦?這一塊我們有兩個優化實踐。

第一個是補償事務,業內應該也經常用到補償事務。
余額操作,正向的操作是扣減余額,補償事務就是把余額加回來。
訂單操作,正向的操作是新增訂單,補償事務就是把訂單刪除掉。
流水操作,正向的操作是新增流水,補償事務就是把流水刪除。
總之,補償事務就是當你發現前面的事務執行失敗的時候,要執行一個應用層的事務,回滾一個動作。
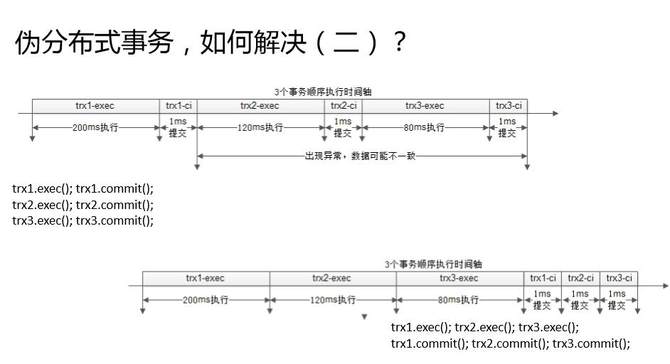
另外一種方式,偽分布式事務的解決方案,是后置提交。
先細化的看一下三個事務是怎么執行的?第一個事務先執行再提交,第二個事務執行再提交,第三個事務執行再提交。事務的執行過程很慢,事務的提交過程很快。上圖這個例子,可能執行時間200毫秒,提交時間幾毫秒,什么時候會出現不一致呢?第一個事務提交成功之后,最后一個事務提交成功之前的中間,任何一個地方出現異常都會導致不一致。
優化其實也很簡單,后置提交。第一個事務執行,第二個事務執行,第三個事務執行;第一個事務提交,第二個事務提交,第三個事務提交。什么時候會出現不一致呢?仍然是第一個事務提交成功之后,第三個事務提交成功之前的時間間隔,如果出現了,網絡異常,服務器掛了,就會不一致。但是這個間隔就只有后面的兩毫秒,所以整個不一致的概率是降低了百倍左右。
最后做一個簡單的總結。根據我的經驗,40分鐘50分鐘的一個技術分享,第二天能夠記住的只有10%。如果只記住10%,那我希望大家能夠記住這一頁的內容,并希望自己的邏輯是清晰的。

數據庫架構最初是單庫,單庫會碰到什么問題?會碰到讀性能瓶頸的問題。讀性能瓶頸最早用什么樣的方式去解決?主從同步讀寫分離,它會帶來什么問題?主從的不一致,用什么方案解決?我們的實踐是中間件,以及強制讀主。
提升讀性能,服務化加緩存也是常見方案,帶來什么新的問題?緩存和數據庫的不一致。在Cache Aside Pattern的情況下,有寫后立即讀的問題,舊數據可能入緩存。我們的實踐,可以通過異步淘汰的方式,當寫操作在從庫上真正完成的時候再去淘汰緩存。同時,我們建議為所有允許Cache miss的數據設置超時時間。
數據庫架構,數據量大的問題,怎么解決?常用的解決方案是分庫,多實例。分庫帶來什么新的問題?記得我的例子么,分了庫之后,可以保證同一個用戶的數據在同一個庫里,不能夠保證同一個司機數據也在同一個庫里,怎么解決?使用數據冗余。冗余帶來什么問題?冗余數據的不一致問題,方向是最終一致性。怎么最終保證一致性?掃全量,掃增量,實時消息對。除了多庫,多實例也可以擴展數據存儲量,會遇到什么問題?多庫的事務不能在保證原則性,補償事務,后置提交,都是我們的優化實踐。
今天的內容這么多,希望大家有收獲,謝謝大家。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





