溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
導語: 本文根據馬進老師在2018年5月10日【第九屆中國數據庫技術大會(DTCC)】現場演講內容整理而成。

馬進 網易 DDB項目負責人
來自網易杭研大數據平臺組,入職以來先后參與了分布式數據庫DDB,緩存NKV,網易數據運河NDC等項目,目前是DDB項目負責人,主導數據庫中間件的各種項目研發。專注于分布式系統架構與數據庫技術,熱衷于構建高效的,高性能的分布式后臺應用。
摘要:
分布式數據庫DDB是網易研發最早的分布式系統,過去十幾年來一直為網易各大互聯網產品提供穩定透明的分庫分表服務,四年前我們推出了私有云DDB,為開發和運維人員在使用DDB和彈性伸縮上提供了極大便利;一年半之前我們從DDB的在線數據遷移模塊中分化出來一套平臺化的異構數據庫數據遷移、同步和訂閱服務NDC;現今隨著網易內外部應用的網絡環境更加復雜,應用場景日益繁多,對DDB的易用性,平臺化,面向機房和多租戶的解決方案提出更多需求和挑戰,這次分享將帶大家一起見證DDB在向結構化數據中心進化過程中的思考和架構變遷。
正文:
DDB發展簡介
DDB:一步到位的分布式數據庫
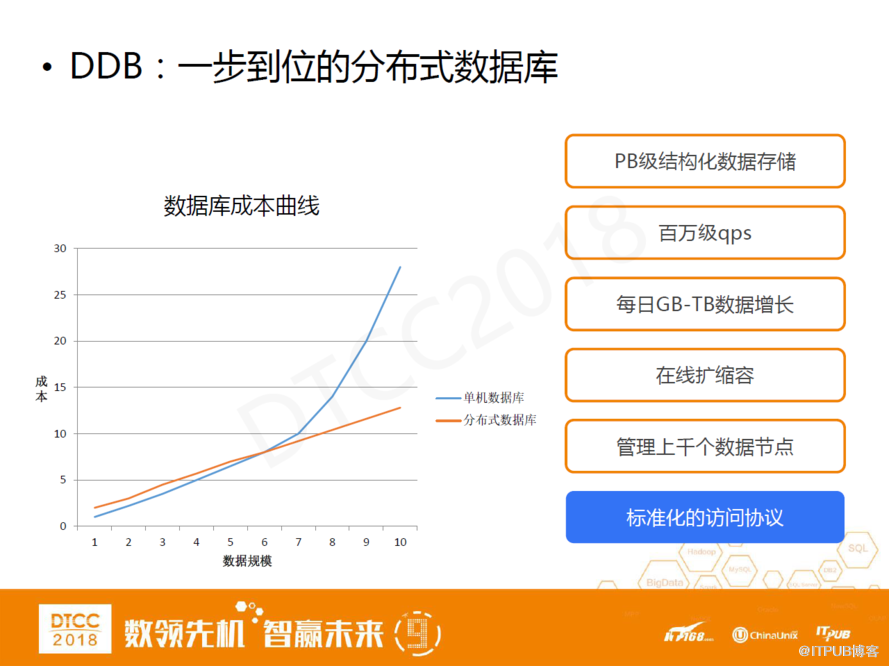
DDB是一個分庫分表數據庫,管理成千上萬個數據節點,并且可以支持PB級結構化數據存儲。目前公司內部使用的版本基本上都是查詢服務器模式,查詢服務和存儲服務相分離,可以分開進行水平線性擴展以及可以支持百萬級的qps。此外,DDB還支持在線數據遷移的功能,可以支持每日GB-TB數據增長并且有標準化的訪問協議。
DDB的在線遷移功能本質上是我們分布式數據庫的一個核心需求,目前我們分庫分表架構還是將它定義為運維人員需要參與的過程。業界中說我們這種方式有上一代數據庫的感覺,其一是因為它還不夠標準化,其二是因為數據庫縮容還需運維人員的參與。但我個人覺得這屬于一個設計哲學的問題,我們可以很好的解決這兩個問題,但歸根結底還是要看它的運維和使用成本有多低。
左邊這張圖是我們數據庫的成本曲線。單機數據庫隨著數據規模和訪問規模的提升,成本曲線成長很不線性。例如,我們一旦達到了商務機器成本上線,往上擴容成本就很大。如果使用分庫分表分布式數據庫,我們能很好的實現存儲和查詢功能的線性擴展,它的使用方式能達到我們的要求,自然就會得到一個理想的線性曲線。
DDB發展歷程
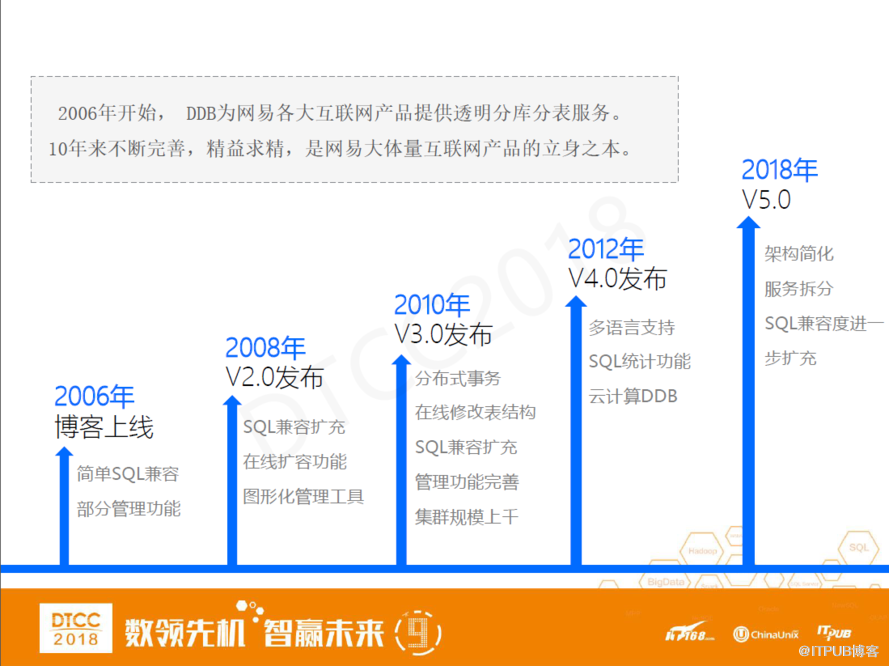
2006年DDB第一個版本上線,當時的功能相對比較簡單,就是一個簡單SQL兼容和部分管理功能。概括的說,從2006年的V1版本到2010的V3版本,都是一套驅動模式,我們內部叫做DBI模式。2012年,隨著私有云上線,我們開發了查詢服務器,可以支持多語言,在查詢服務器內部提供豐富的SQL統計功能。同時,我們在云計算的管理平臺上提供云計算DDB Pass服務,可以進行一鍵部署和管理監控。2017年之后,我們開始研發DDB 5.0版本,逐漸簡化架構并且把相關服務做了模塊化的拆分,以及進一步擴充了SQL的兼容度。
DDB功能特性:數據信道
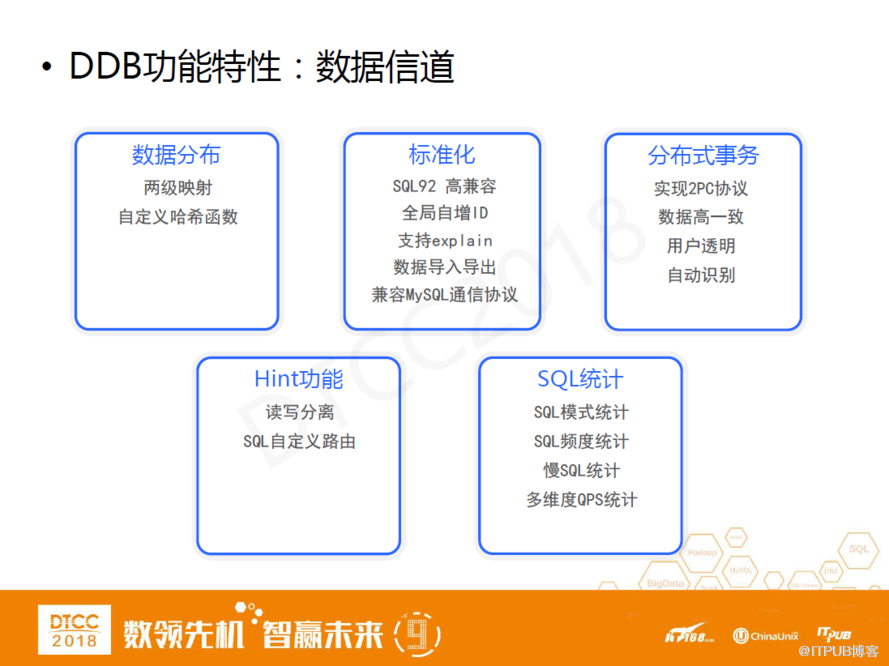
在數據信道方面,第一,我們有比較好的均衡方式,有兩級映射的功能,有應用自定義配置的哈希函數。
第二,我們有比較高的標準化,SQL 92能達到90%的兼容度,5.0之后達到了95%。并且我們支持全局自增ID、explain計劃,有數據標準導入導出,查詢服務器兼容MySQL通信協議。
第三,我們支持分布式事務。業內很多專家人士可能會吐槽兩階段提交協議不可靠,但我認為ACID本質上是一個概率問題,兩階段提交協議的ACID功能在概率上遠不如單機版的事務,但并不代表它的可靠性沒有提升。另外,我們也會跟應用強調,業務場景里涉及到的敏感數據交易。并且我們分布式事務兩階段提交協議的實現對用戶是透明的,內部會有一些優化措施,并不是所有的事務都是兩階段提交。最后強調一點,分布式事物兩階段提交協議在性能上還是存在瓶頸,在業務中我們也會跟應用具體強調。
第四,我們提供Hint功能,可以在DDB內部實現讀寫分離,然后實現SQL自定義路由。
第五,我們在查詢服務器層面提供豐富的統計功能,包括SQL模式統計、SQL頻度統計、慢SQL 統計、多維度QPS統計。
DDB功能特性:管理信道

在管理信道方面,需要特別說明的是我們兼容MySQL管理語法,創建表等操作都跟MySQL在語法上高度一致,用戶管理上也比較類似。并且,我們在線數據遷移功能提供較多的是場景化的在線遷移。前期應用在創建表的時候,如果沒有選擇好分區字段,我們可以在管理工具上做分區字段更改的操作,底層就會實施數據重分布。另外還有一些擴展功能,比如定時任務、懸掛事務報警。在高可用方面,我們查詢服務器是一個熱備的,底層的數據庫也是比較經典的主從架構,內部做了自動fail-over機制。
DDB核心優勢
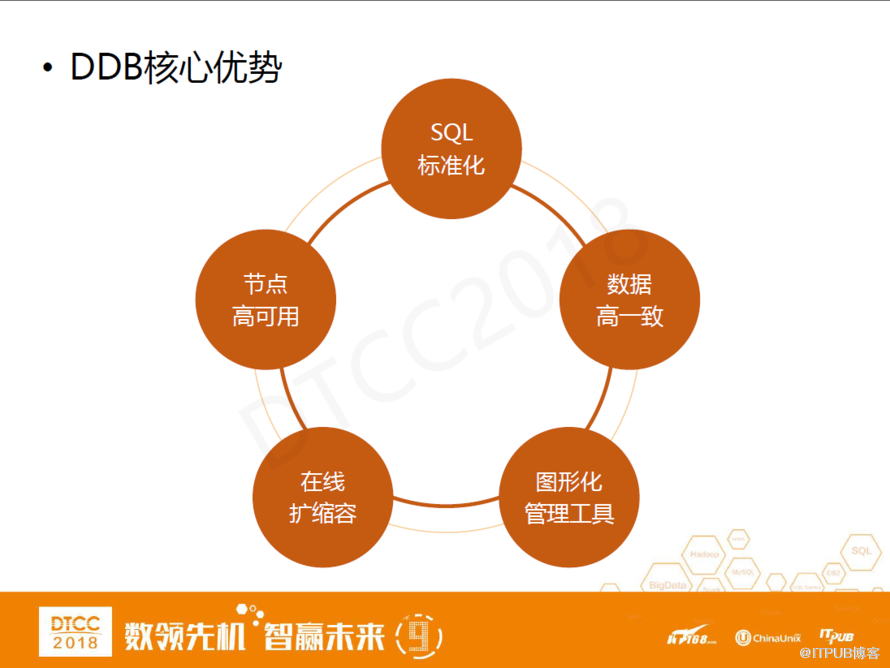
DDB的核心優勢,第一,有標準化的訪問協議,有較高的SQL兼容度。第二,分布式事務能夠保證數據的高一致,有較完善的圖形化管理工具、在線擴縮容功能。第三,所有的組件都是高可用的。
DDB V1-V3架構:DBI模型
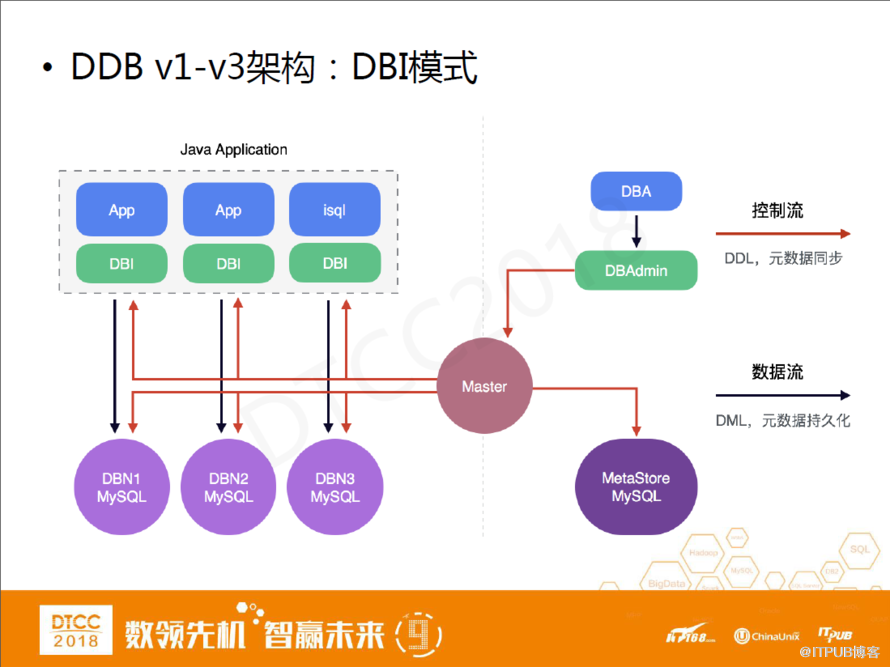
DDB架構過去十年的變遷:
這是V1-V3的經典架構,在這套架構里,分庫分表實現在驅動層。在應用端,它們會依賴我們提供的JDBC驅動的jar包來訪問DDB。DDB內部的語法解析執行計劃都在驅動層做。另外,我們有一個Master組件,負責整個集群的元數據管理和同步。
但這套集群也會帶來一些問題。第一,從語法解析到執行計劃到最后的結果集合并,DBI內部的這些實現比較耗費CPU。第二,在這種架構里,DDB版本很難管理。第三個問題比較嚴重,尤其對于提量大的應用。DBI跟隨應用層做水平擴展,如果我們發現體量不夠,就要加應用服務器,DBI也會跟著增加,訪問底層數據庫節點的連接數也會隨著增加,這樣就很可能會導致底下數據庫被打爆的問題。
這套架構也比較經典,很多小伙伴應該能看出來這套架構跟阿里TDDL比較相似。但很重要的一點區別是我們的集群管理比較獨立,每一套集群都有一個單獨的Master做管理。這個跟我們公司的背景也有關系,例如淘寶當初做中間件,是為了淘寶的核心業務服務的,它只需服務于一個業務。但網易不一樣,從一開始網易內部就有很多不同類型的產品,比如網易考拉、網易音樂兩個截然不同的應用,一個是典型的電商場景,一個是典型的讀多寫少場景,這就要求把不同的集群隔離開。
DDB V4架構:QS模式
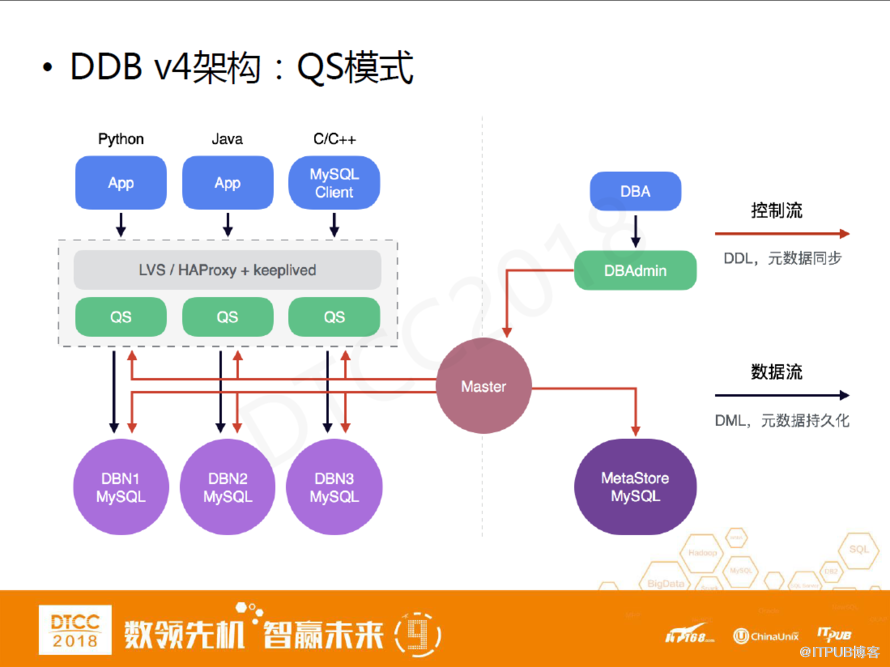
DDB V4是提供查詢服務器的,這套架構就相當于通過單獨部署QueryServer組件,把DBI包起來,然后對應用提供一個標準的MySQL協議支持。同時在Query Server和應用之間部署LVS\HAPProxy+keepplived組合做負載均衡。
如圖所示,應用發起一個請求要通過LVS、QueryServer到最后的數據庫,這套架構比原來的架構多了兩次轉發,鏈路或許會有點長,但卻很好的解決了之前DBI存在的問題。
首先Query Server的數量和應用的數量沒有綁定關系。其次Query Server由平臺的運維人員部署,我們能追蹤它的版本管理和內部問題定位。
除此之外,在集群管理上我們還是沿用老一套,包括管理工具。
DDB V1-V4:小結
﹣DBI模式
部署簡單,省機器
對JAVA應用較為友好
問題跟蹤和定位成本高
占用比較多應用端的CPU資源
版本升級周期長,新功能推廣困難
﹣QS模式
多語言支持,集成任意連接池和DAO
版本便于管理,跟蹤定位問題成本大大降低
慢語句,TopSQL等功能便于SQL優化
連接收斂,連接池熔斷等功能提升可用性
DDB v5:LBDriver
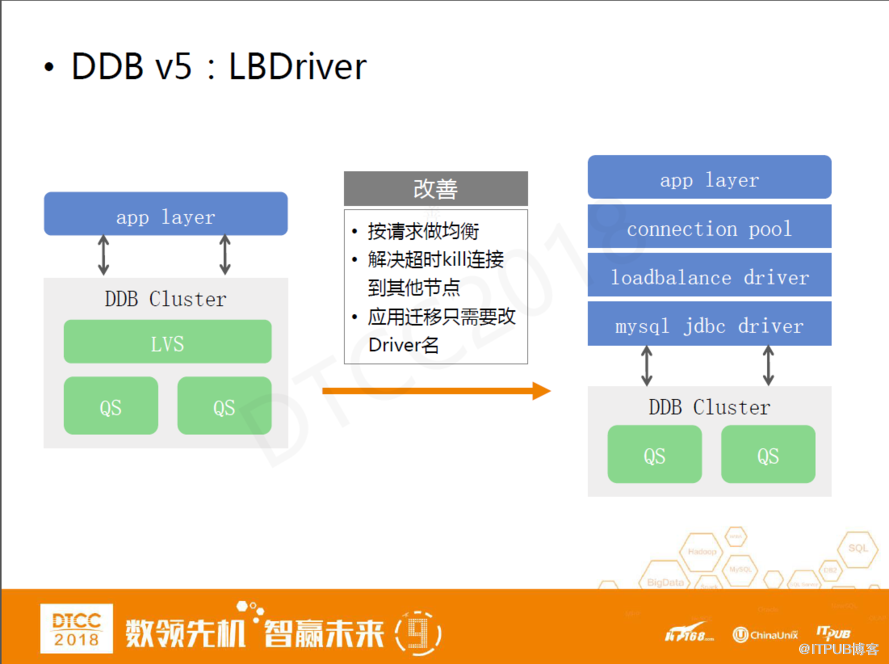
DDB V4雖然解決了之前DBI模式的各種問題但還是會有一些潛在問題。
首先就是之前提到過的鏈路長的問題。其次,LVS通過連接做負載均衡存在弊端。第一,在低峰期活躍連接數比較少的情況下,無法保證這些活躍連接數均勻分散到每個Query Server上,如果使用云計算部署查詢服務器,這種不均衡容易導致CPU使用率飆升。另外一點,使用LVS做負載均衡,在應用端cancel語句或query timeout情況下,創建臨時連接執行kill query指令的時候,可能創建的臨時連接落到另外一個QueryServer上,這樣如果這個節點上沒有一樣的connection id,那相當于cancel或timeout沒有實現,如果有connection id,相當于錯誤的kill掉了一個連接。
因此,我們給應用提供了一套全新均衡方案:在應用端的連接池和驅動之間開發了一個loadbalance driver組件,這個組件包裝了JDBC驅動,對連接池提供邏輯連接,并與各個QueryServer的物理連接實現映射。在連接池使用連接的過程中,它會按照SQL請求做負載均衡,這樣首先解決了LVS不能夠按照請求去均衡的問題。其次,在連接超時的情況下,能夠拿到底層的真實物理連接,并通過它復制臨時連接來執行kill指令。
最后,我們的lLBDriver不會給應用帶來遷移成本,因為它本身就是一個JDBC驅動,應用使用lLBDriver時 ,只需要配置里更改下driver名稱和URL就可以了。
DDB V5:去master
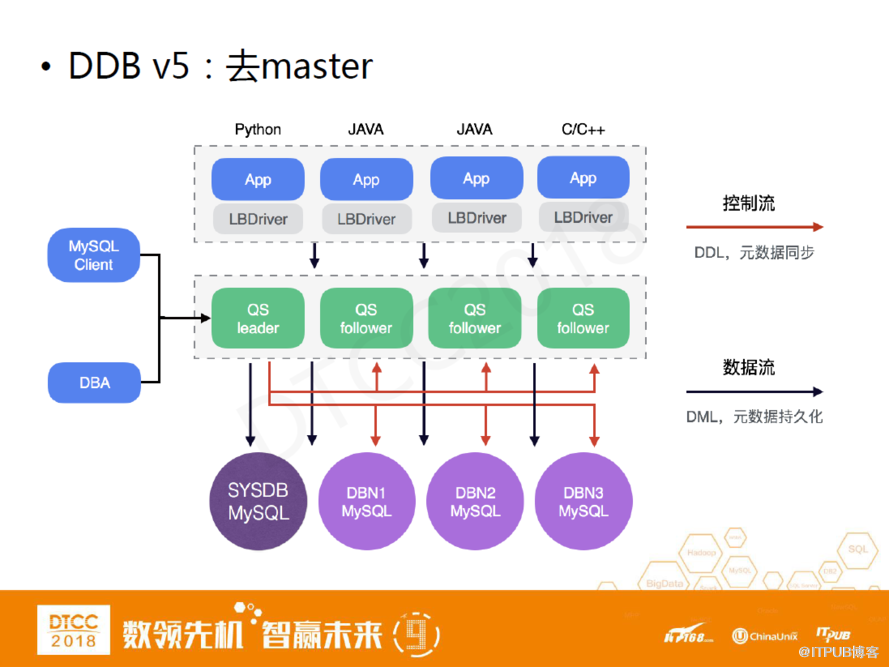
這是DDB V5的架構。除了通過LBDriver做負載均衡外,我們還去掉了Master組件。原因第一是出于省成本考慮。第二,Query Server本身是一個我們自己去掌控的服務端,所以完全可以用它去做一些管理上的功能,QueryServer之間本身互為熱備,在實施了master的部分功能集成到QueryServer上后,在多個QueryServer之間選擇一個leader作為管控節點,這樣同時解決了我們管理功能的高可用問題。
DDB V5:面向租戶的WEB管理工具
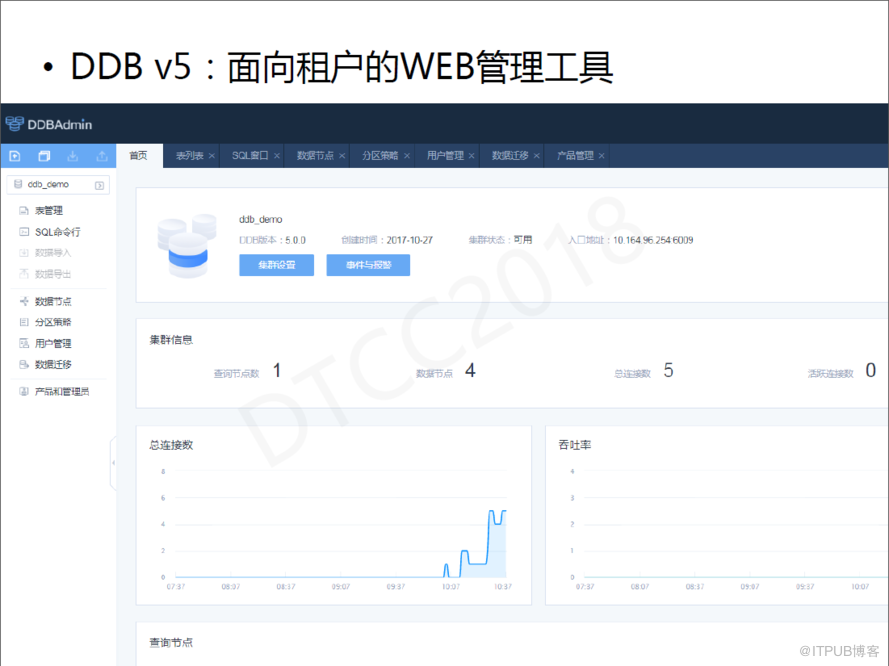
DDB V5版本還提供了面向租戶的WEB管理工具。因為之前實踐私有云的Pass服務時,最大的感觸就是,面向租戶的管理方式能夠很大程度上減少運維人員在運維上的開銷和代價。除此之外,我們還在這套WEB管理工具里還提供了SQL統計,審核,報表和大屏服務等。
DDB V5:NDC服務拆分
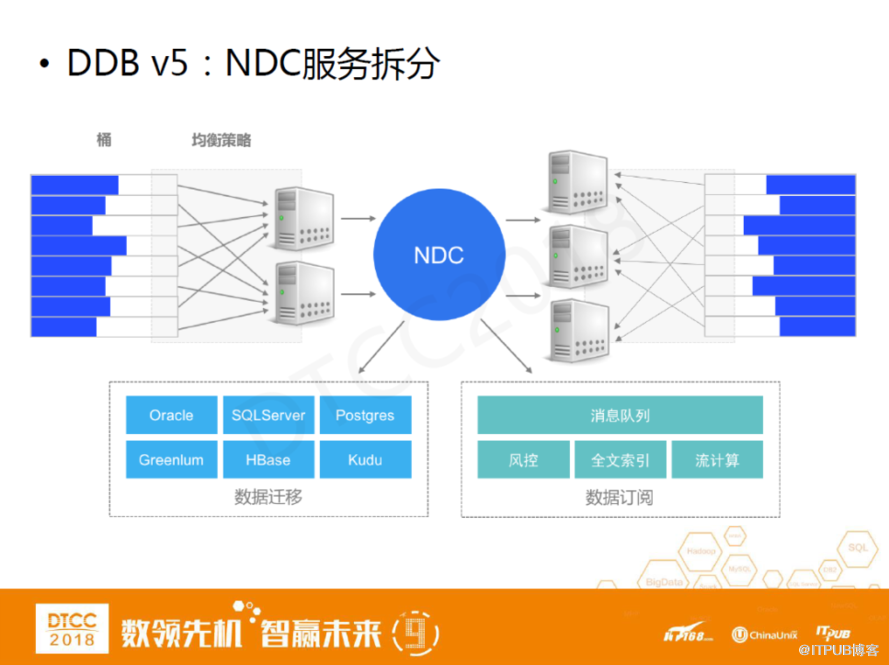
DDB V5還做了服務拆分。我們把DDB以前的在線數據遷移組件拎出來獨立做了一套NDC服務,全名Netease Data Canal,直譯為網易數據運河系統。它除了可以做DDB在線數據遷移之外,也可以把MySQL的binlog獨立拉出來做一些復雜的ETL,這樣我們中間件產品棧就會更加豐富。
DDB V5:面向IDC的解決方案
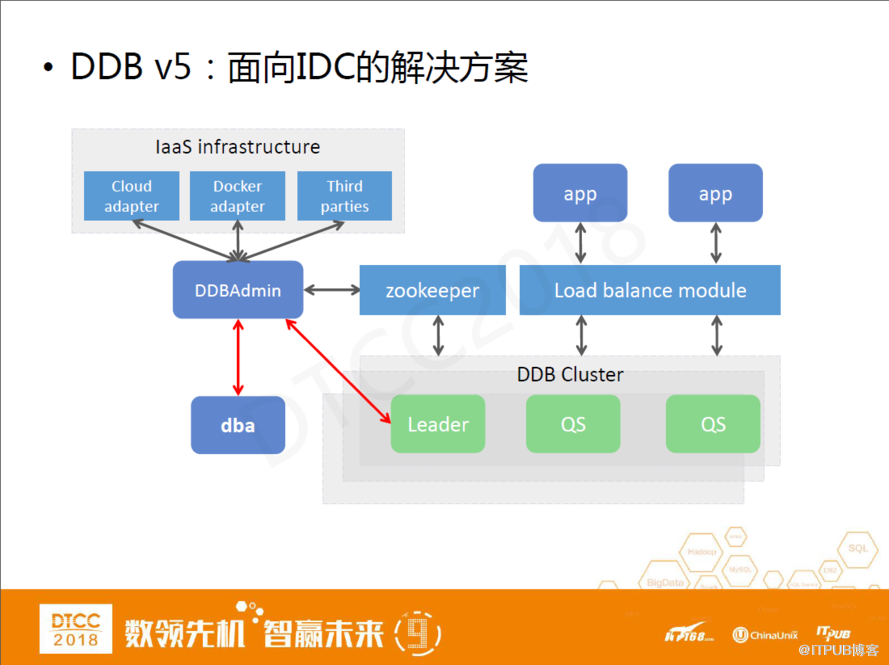
最后,我們在DDB V5里面提供了面向IDC的解決方案。DDB V5做的最大的改進就是架構精簡化。我們一般怎樣評價一個分布式系統是一個好分布式系統呢?例如Hadoop,它給我們最大的感受就是復雜。但它會提供 Standalone模式,通過一臺機器和一些簡單的指令就可以拉起一個系統,這是所謂的重中有輕,我們DDB也希望做到這一點。
我們最簡單的一個QueryServer集成了分庫分表和相關管理功能,這樣我們只需要部署一個QueryServer和數據節點,分布式數據庫就能建立起來,并且具有DDB整套功能集。后面這些管理工具、組件都是選裝的,即便沒有它,DDB也可以使用。
DDB的WEB管理工具通過DDL向QS管控節點發起管理操作,可以把它當做更加豐富的上層功能。值得一提的是,這個管理功能可以跨IaaS,一套集群里它既可以有物理部署也可以在云端部署。我們提供了可插拔的接口,可以在上面做不同的IaaS層適配,好處是在不同的物理平臺或云平臺上我們可以用統一的界面去運維和使用它。
DDB V5:小結
﹣降低各種成本
架構精簡,去master,降低學習和部署成本
以LBDriver替換LVS,提升可用性,降低使用成本
QS兼容MySQL DDL,向標準化更加邁進一步
面向租戶的平臺化方案,降低部署和運維成本
通過平臺化的NDC支持在線數據遷移和同步
﹣從軟件包到解決方案
面向IDC的解決方案,通過NDC實現異地同步
跨IaaS的支持,物理環境和云環境混合部署
結構化數據中心——DDB以及NDC規劃和瞻望
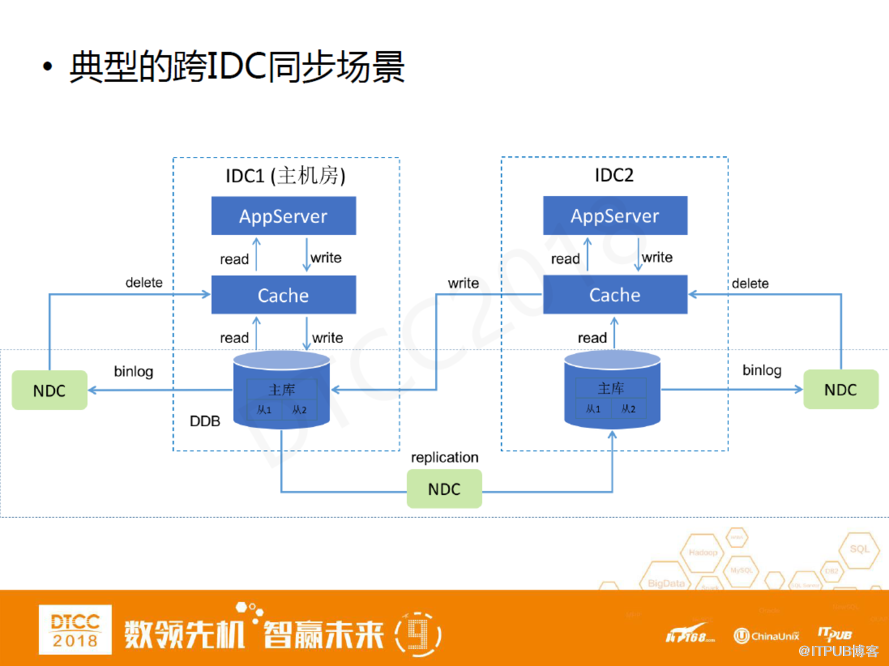
這是我們比較經典的一個多機房數據庫和緩存的架構。單機房內部一般會有應用層、緩存層以及數據庫層。傳統架構一般是應用層在執行數據庫操作之后,由它們去負責更新緩存。但如果我們把這種模式遷移到多機房場景,另一個機房的cache就很難維護。另外,它還可能導致數據不一致。
一個比較好的方法就是通過binlog方式,把每一個機房的binlog拉出來,由NDC數據訂閱功能去執行緩存的淘汰或更新。這種場景下我們可以把NDC當做DDB的一個跨系統的觸發器。這個在業界算是一個較成熟的方案,在很多的互聯網公司得到了廣泛應用。
在這套架構里,DDB和NDC可以看成一個有機整體,如果我們把NDC當成DDB的一個觸發器來看,它就可以被當做成一個系統來用。
以NDC為總棧的架構
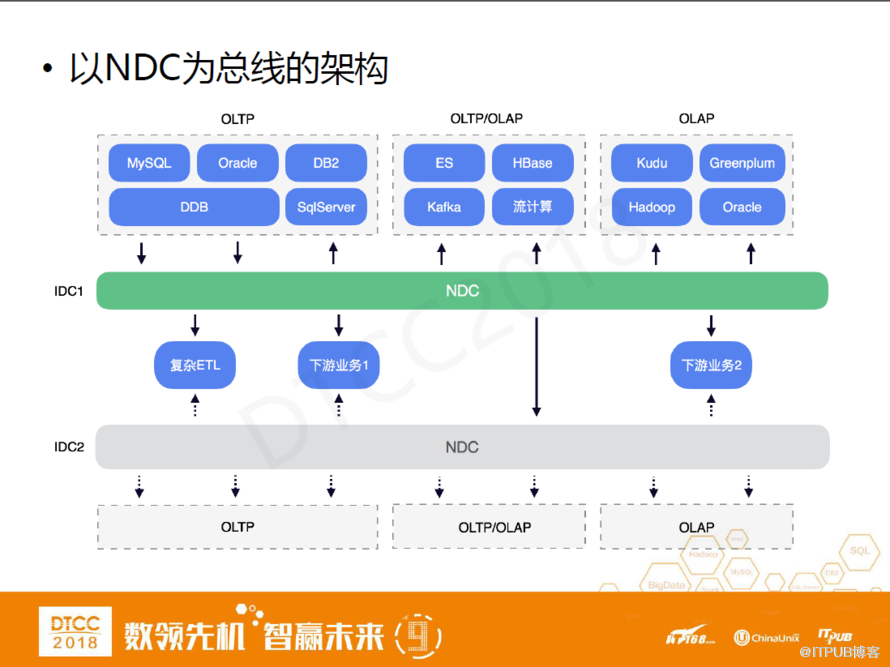
這是一個更加復雜的架構,除了在不同的機房之間做數據同步之外,在一個機房內部也可以通過NDC做異構的數據庫在線遷移。同時,我們可以用NDC做一些同機房內部的數據訂閱滿足一些下游應用的解耦。
這套復雜的架構里還存在很多可以被挖掘的點。例如,在不同的系統之間做數據同步,首先每一個系統要配合一個管理界面,然后需要把每一個系統之間的用戶權限打通,由運維人員配NDC任務。但這個過程中會有很多管理上的壁壘,我們做一個簡單的需求總結:
﹣ODMP潛在需求
各個數據系統之間管理方式有壁壘
缺乏統一的資源劃分,認證方式
各個系統間權限不通,需要人工同步
沒有統一的監控,部署平臺
傳統的工單流程容易造成資源浪費
﹣ODMP(在線數據管理平臺)
可插拔,可擴展,易集成,面向IDC的數據系統管理平臺
集成租戶管理,權限同步,資源池管理,報警監控,自動部署
基于NDC實現異構系統和IDC間數據同步(核心實現)
這是我們最終想要達到的效果。其實我們內部已經實現了這些功能,但都是彼此獨立不相同的。我們希望建立一個統一標準進行統一維護,這樣就能很大程度降低運維和使用成本。
兩個問題

一路下來我們總結出這兩個問題。其一:為什么我們在做應用的時候團隊越大,DEVOPS門檻越高?
隨著我們應用發展、團隊成長、規模擴充,面臨的業務場景越加復雜,需要做的技術選型越來越多,開發人員從調研到測試、從部署開發到最后運維,長期處于這樣的循環里。一套成熟的系統進入到一個比較正規的運維流程往往需要一個很長的周期。
其二:在這個過程中做中間件,怎樣做可以降低成本?
第一,盡可能自動化,減少工單流程。第二,盡可能挖掘出平臺運維的角色,即我們開發人員,開發人員本身就是DBVOPS,可以直接面向應用開發,這樣可以省去運維人員的介入。第四,注意各個平臺和系統之間的串聯,這一點也是ODMP的本質問題。
ODMP:hybrid console
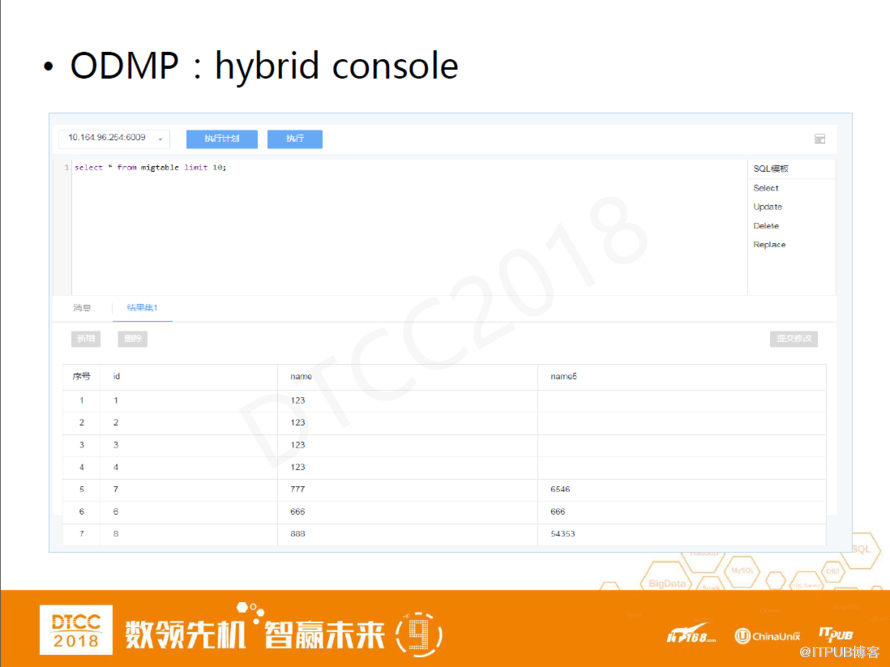
hybrid console相當于一個DDB的命令行工具,可以選擇訪問QueryServer的節點。我們可以對這個功能進行這樣的一些展望:在選擇節點之前是否可以選擇要訪問的系統,是否可以在同一界面進行這些操作,具體訪問了哪個系統是否可以隱藏起來。目前,業界很多產品都在朝這個方向發展,hybrid這種訪問方式或許會成為未來的主流趨勢。
總結
﹣DDB十年架構變遷
V1-V3:驅動模式,滿足JAVA應用所需
V4:代理模式,多語言支持,增強可用性和運維能力
V5:平臺模式,精簡掉lvs和master,面向租戶和IDC的解決方案
﹣ODMP展望
脫胎于DDB和NDC對平臺化的理念
核心價值:打通異構在線數據系統的壁壘,實現統一的部署,監控, 租戶認證,權限打通,使大團隊中DEVOPS成為可能
核心實現:基于NDC實現異構系統和IDC間數據總線
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





