溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹如何解決億級用戶的分布式數據庫數據存儲問題,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
一、MySQL復制
1.MySQL的主從復制
MySQL的主從復制,就是將MySQL主數據庫中的數據復制到從數據庫中去。
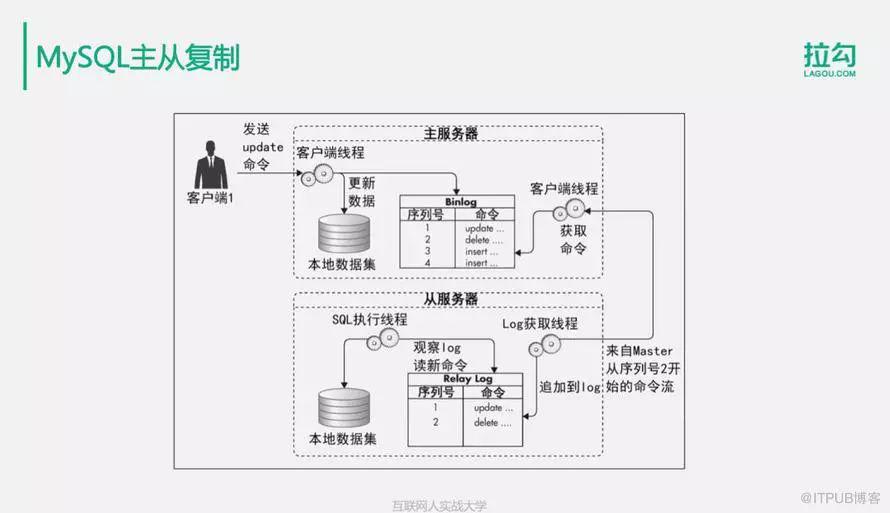
主要目的是實現數據庫讀寫分離,寫操作訪問主數據庫,讀操作訪問從數據庫,從而使數據庫具有更強大的訪問負載能力,支撐更多的用戶訪問。
它的主要的復制原理是:當應用程序客戶端發送一條更新命令到數據庫的時候,數據庫會把這條更新命令同步記錄到Binlog中, 然后由另外一個線程從Binlog中讀取這條日志,然后通過遠程通訊的方式將它復制到從服務器上面去,從服務器獲得這條更新日志后,將其加入到自己的Relay log中,然后由另外一個SQL執行線程從Relay log中讀取這條新的日志,并把它在本地的數據庫中重新執行一遍。
這樣當客戶端應用程序執行一個update命令的時候,這個命令會在主數據庫和從數據庫上同步執行,從而實現了主數據庫向從數據庫的復制,讓從數據庫和主數據庫保持一樣的數據。
2.MySQL的一主多從復制
MySQL的主從復制是一種數據同步機制,除了可以將一個主數據庫中的數據同步復制到一個從數據庫上,還可以將一個主數據庫上的數據同步復制到多個從數據庫上,也就是所謂的MySQL的一主多從復制。
多個從數據庫關聯到主數據庫后,將主數據庫上的Binlog日志同步地復制到了多個從數據庫上。通過執行日志,讓每個從數據庫的數據都和主數據庫上的數據保持了一致。這里面的數據更新操作表示的是所有數據庫的更新操作,除了不包括SELECT之類的查詢讀操作,其他的INSERT、DELETE、UPDATE這樣的DML寫操作,以及CREATE TABLE、DROPT ABLE、ALTER TABLE等DDL操作也都可以同步復制到從數據庫上去。
3.一主多從復制的優點
一主多從復制有四大優點,分別是分攤負載、專機專用、便于冷備和高可用。
a.分攤負載
將只讀操作分布在多個從數據庫上,從而將負載分攤到多臺服務器上。
b.專機專用
可以針對不同類型的查詢,使用不同的從服務器。
c.便于進行冷備
即使數據庫進行了一主多從的復制,在一些極端的情況下。也可能會導致整個數據中心的數據服務器都丟失。所以通常說來很多公司會對數據做冷備,但是進行冷備的時候有一個困難點在于,數據庫如果正在進行寫操作,冷備的數據就可能不完整,數據文件可能處于損壞狀態。使用一主多從的復制就就可以實現零停機時間的備份。只需要關閉數據的數據復制進程,文件就處于關閉狀態了,然后進行數據文件拷貝,拷貝完成后再重新打開數據復制就可以了。
d.高可用
如果一臺服務器宕機了,只要不發請求給這臺服務器就不會出問題。當這臺服務器恢復的時候,重新發請求到這臺服務器。所以,在一主多從的情況下,某一臺從服務器宕機不可用,對整個系統的影響是非常小的。
4.MySQL的主主復制
但是一主多從只能夠實現從服務器上的這些優點,當主數據庫宕機不可用的時候,數據依然是不能夠寫入的,因為數據不能夠寫入到從服務器上面去,從服務器是只讀的。
為了解決主服務器的可用性問題,我們可以使用MySQL的主主復制方案。所謂的主主復制方案是指兩臺服務器都當作主服務器,任何一臺服務器上收到的寫操作都會復制到另一臺服務器上。
如上主主復制原理圖,當客戶端程序對主服務器A進行數據更新操作的時候,主服務器A會把更新操作寫入到Binlog日志中。然后Binlog會將數據日志同步到主服務器B,寫入到主服務器的Relay log中,然后執Relay log,獲得Relay log中的更新日志,執行SQL操作寫入到數據庫服務器B的本地數據庫中。B服務器上的更新也同樣通過Binlog復制到了服務器A的Relay log中,然后通過Relay log將數據更新到服務器A中。
通過這種方式,服務器A或者B任何一臺服務器收到了數據的寫的操作都會同步更新到另一臺服務器,實現了數據庫主主復制。主主復制可以提高系統的寫可用,實現寫操作的高可用。
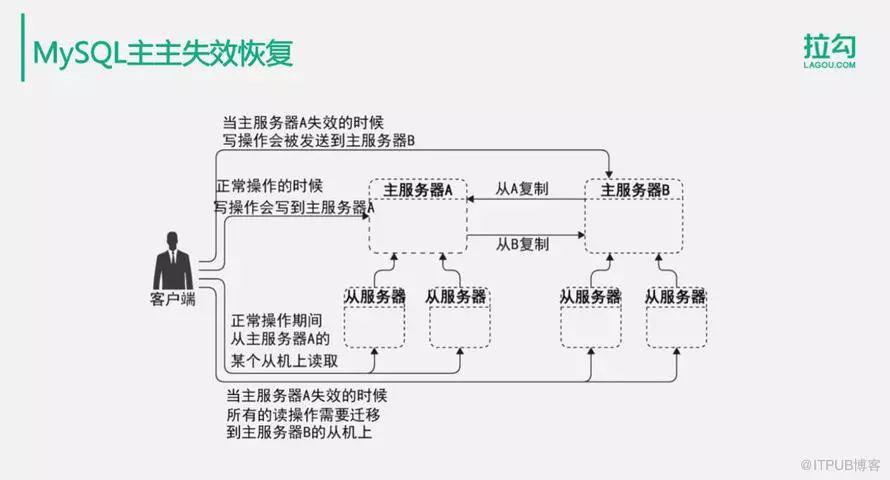
5.MySQL的主主失效恢復
使用MySQL服務器實現主主復制時,數據庫服務器失效該如何應對?
正常情況下用戶會寫入到主服務器A中,然后數據從A復制到主服務器B上。當主服務器A失效的時候,寫操作會被發送到主服務器B中去,數據從B服務器復制到A服務器。
主主失效的維護過程如下:
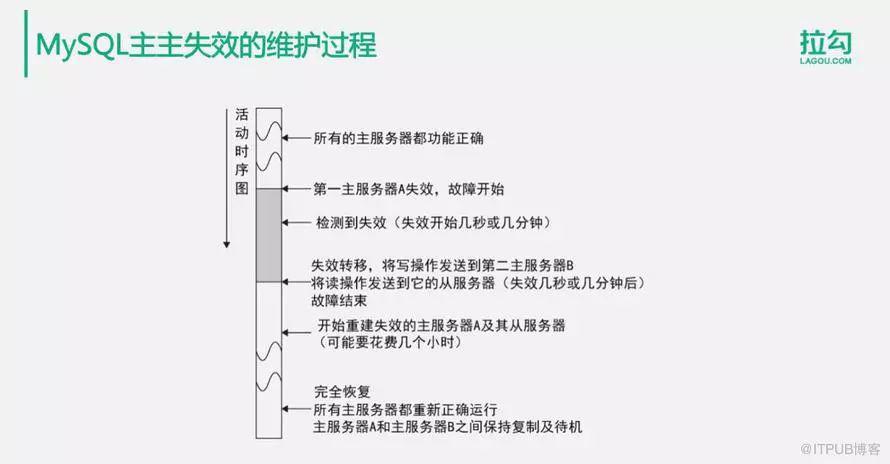
最開始的時候,所有的主服務器都可以正常使用,當主服務器A失效的時候,進入故障狀態,應用程序檢測到主服務器A失效,檢測到這個失效可能需要幾秒鐘或者幾分鐘的時間,然后應用程序需要進行失效轉移,將寫操作發送到備份主服務器B上面去,將讀操作發送到B服務器對應的從服務器上面去。
一段時間后故障結束,A服務器需要重建失效期間丟失的數據,也就是把自己當作從服務器從B服務器上面去同步數據。同步完成后系統才能恢復正常。這個時候B服務器是用戶的主要訪問服務器,A服務器當作備份服務器。
5.MySQL復制注意事項
使用MySQL進行主主復制的時候需要注意的事項如下:
a.不要對兩個數據庫同時進行數據寫操作,因為這種情況會導致數據沖突。
b.復制只是增加了數據的讀并發處理能力,并沒有增加寫并發的能力和系統存儲能力。
c.更新數據表的結構會導致巨大的同步延遲。
需要更新表結構的操作,不要寫入到到Binlog中,要關閉更新表結構的Binlog。如果要對表結構進行更新,應該由運維工程師DBA對所有主從數據庫分別手工進行數據表結構的更新操作。
二、數據分片
數據復制只能提高數據讀并發操作能力,并不能提高數據寫操作并發的能力以及數據整個的存儲容量,也就是并不能提高數據庫總存儲記錄數。如果我們數據庫的寫操作也有大量的并發請求需要滿足,或者是我們的數據表特別大,單一的服務器甚至連一張表都無法存儲。解決方案就是數據分片。
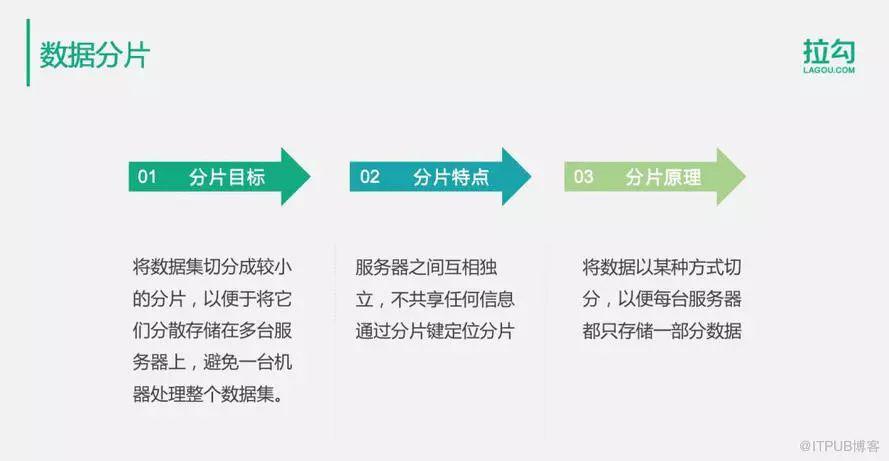
1.數據分片介紹
a.主要目標:將一張數據表切分成較小的片,不同的片存儲到不同的服務器上面去,通過分片的方式使用多臺服務器存儲一張數據表,避免一臺服務器記錄存儲處理整張數據表帶來的存儲及訪問壓力。
b.主要特點:數據庫服務器之間互相獨立,不共享任何信息,即使有部分服務器故障,也不影響整個系統的可用性。第二個特點是通過分片鍵定位分片,也就是說一個分片存儲到哪個服務器上面去,到哪個服服務器上面去查找,是通過分片鍵進行路由分區算法計算出來的。在SQL語句里面,只要包含分片鍵,就可以訪問特定的服務器,而不需要連接所有的服務器,跟其他的服務器進行通信。
.主要原理:將數據以某種方式進行切分,通常就是用剛才提到的分片鍵的路由算法。通過分片鍵,根據某種路由算法進行計算,使每臺服務器都只存儲一部分數據。
2.硬編碼實現數據分片
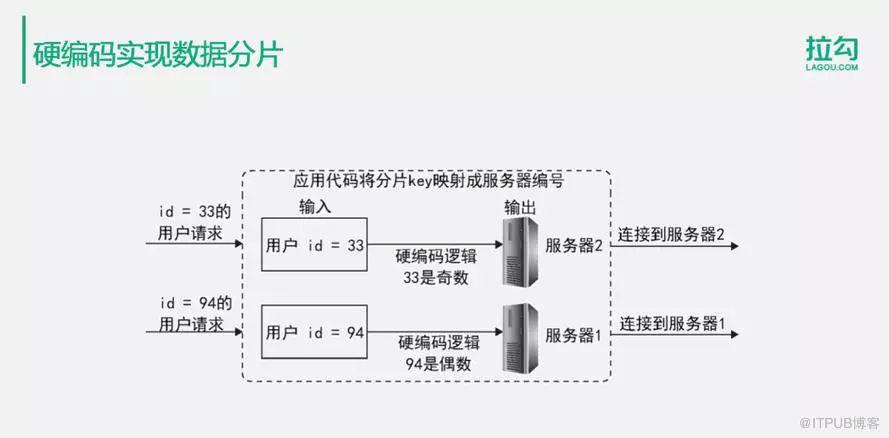
如圖例子,通過應用程序硬編碼的方式實現數據分片。假設我們的數據庫將數據表根據用戶ID進行分片,分片的邏輯是用戶ID為奇數的數據存儲在服務器2中,用戶ID為偶數的數據存儲在服務器1中。那么,應用程序在編碼的時候,就可以直接通過用戶ID進行哈希計算,通常是余數計算。如果余數為奇數就連接到服務器2上,如果余數為偶數,就連接到服務器1上,這樣就實現了一張用戶表分片在兩個服務器上。
這種硬編碼主要的缺點在于,數據庫的分片邏輯是應用程序自身實現的,應用程序需要耦合數據庫分片邏輯,不利于應用程序的維護和擴展。一個簡單的解決辦法就是將映射關系存儲在外面。
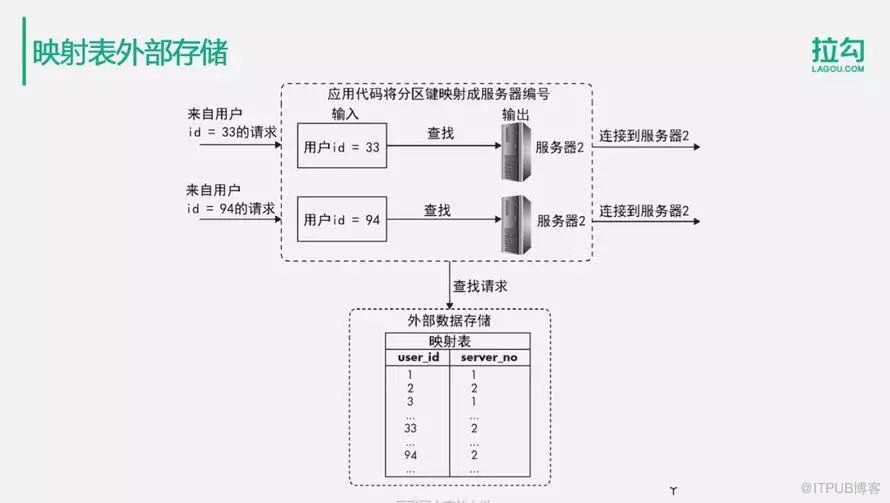
3.映射表外部存儲
應用程序在連接數據庫進行SQL操作的時候,通過查找外部的數據存儲查詢自己應該連接到哪臺服務器上面去,然后根據返回的服務器的編號,連接對應的服務器執行相應的操作。在這個例子中,用戶ID=33查是2,用戶ID=94查也是2,它們根據查找到的用戶服務器的編號,連接對應的服務器,將數據寫入到對應的服務器分片中。
4.數據分片的挑戰及解決方案
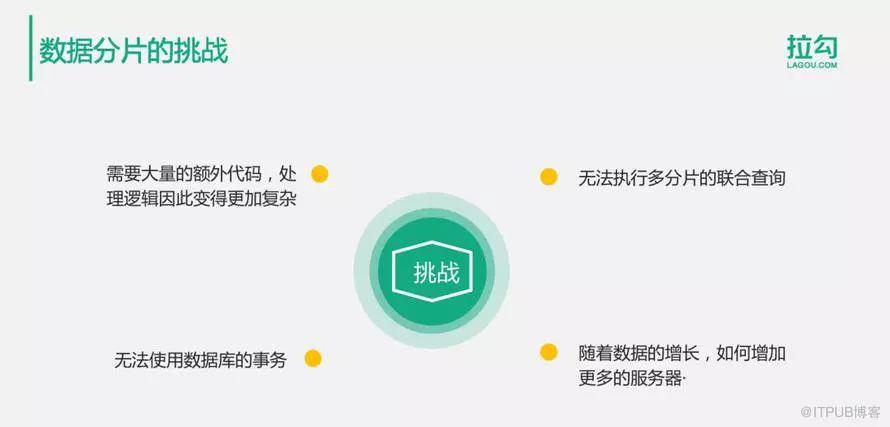
數據庫分片面臨如圖的挑戰:
現在有一些專門的分布式數據庫中間件來解決上述這些問題,比較知名的有Mycat。Mycat是一個專門的分布式數據庫中間件,應用程序像連接數據庫一樣的連接Mycat,而數據分片的操作完全交給了Mycat去完成。
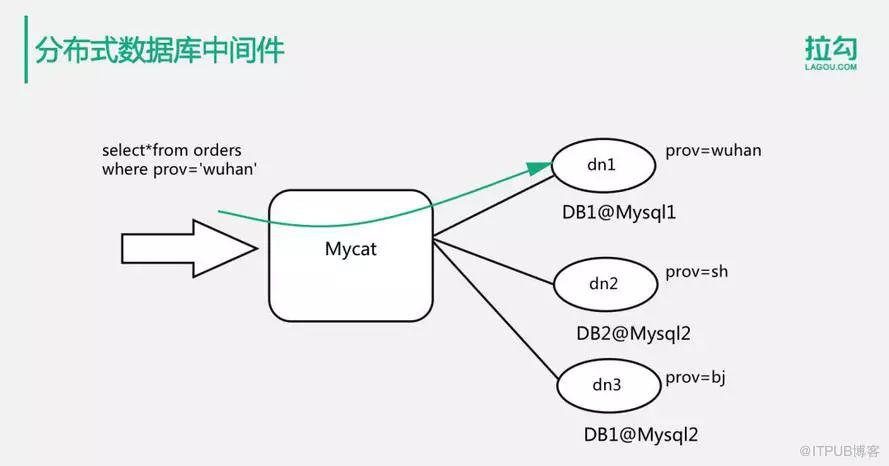
如下這個例子中,有3個分片數據庫服務器,數據庫服務器dn1、dn2和dn3,它們的分片規則是根據prov字段進行分片。那么,當我們執行一個查詢操作”select * from orders where prov=’wuhan’“的時候,Mycat會根據分片規則將這條SQL操作路由到dn1這個服務器節點上。dn1執行數據查詢操作返回結果后,Mycat再返回給應用程序。通過使用Mycat這樣的分布式數據庫中間件,應用程序可以透明的無感知的使用分片數據庫。同時,Mycat還一定程度上支持分片數據庫的聯合join查詢以及數據庫事務。
5.分片數據庫擴容伸縮
一開始,數據量還不是太多,兩個數據庫服務器就夠了。但是隨著數據的不斷增長,可能需要增加第三個第四個第五個甚至更多的服務器。在增加服務器的過程中,分片規則需要改變。分片規則改變后,以前寫入到原來的數據庫中的數據,根據新的分片規則,可能要訪問新的服務器,所以還需要進行數據遷移。
不管是更改路由算法規則,還是進行數據遷移,都是一些比較麻煩和復雜的事情。因此在實踐中通常的做法是數據分片使用邏輯數據庫,也就是說一開始雖然只需要兩個服務器就可以完成數據分片存儲,但是依然在邏輯上把它切分成多個邏輯數據庫。具體的操作辦法,本文不用大篇幅進行闡述了。
三、數據庫部署方案
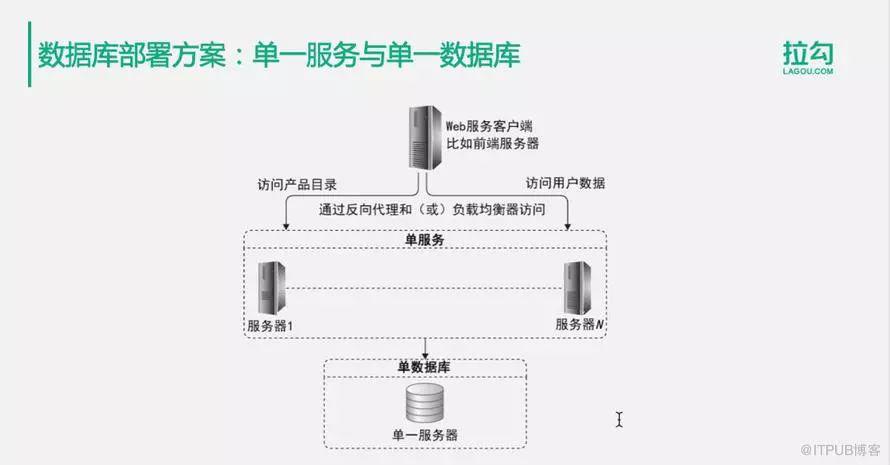
1.單一服務和單一數據庫
這是最簡單的部署方案。應用服務器可能有多個,但是它們完成的功能是單一的功能。多個完成單一功能的服務器,通過負載均衡對外提供服務。它們只連一臺單一數據庫服務器,這是應用系統早期用戶量比較低的時候的一種架構方法。
2.主從復制實現伸縮
如果對系統的可用性和對數據庫的訪問性能提出更高要求的時候,就可以通過數據庫的主從復制進行初步的伸縮。通過主從復制,實現一主多從。應用服務器的寫操作連接主數據庫,讀操作從從服務器上進行讀取。
3.兩個Web服務及兩個數據庫
隨著業務更加復雜,為了提供更高的數據庫處理能力,可以進行數據的業務分庫。數據的業務分庫是一種邏輯上的,是基于功能的一種分割,將不同用途的數據表存儲在不同的物理數據庫上面去。
在這個例子中,有產品類目服務和用戶服務,兩個應用服務器集群,對應的也將數據庫也拆分成兩個,一個叫做類目數據庫,一個叫做用戶數據庫。每個數據庫依然使用主從復制。通過業務分庫的方式,在同一個系統中,提供了更多的數據庫存儲,同時也就提供了更強大的數據訪問能力,同時也使系統變得更加簡單,系統的耦合變得更低。
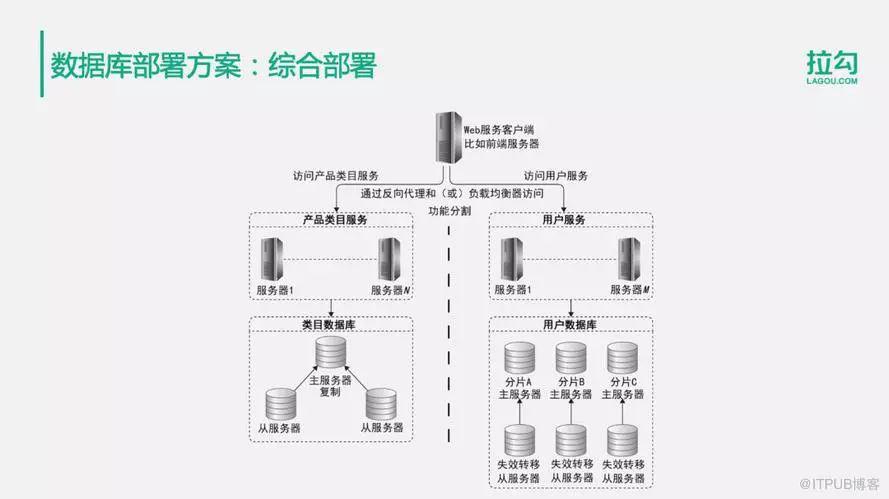
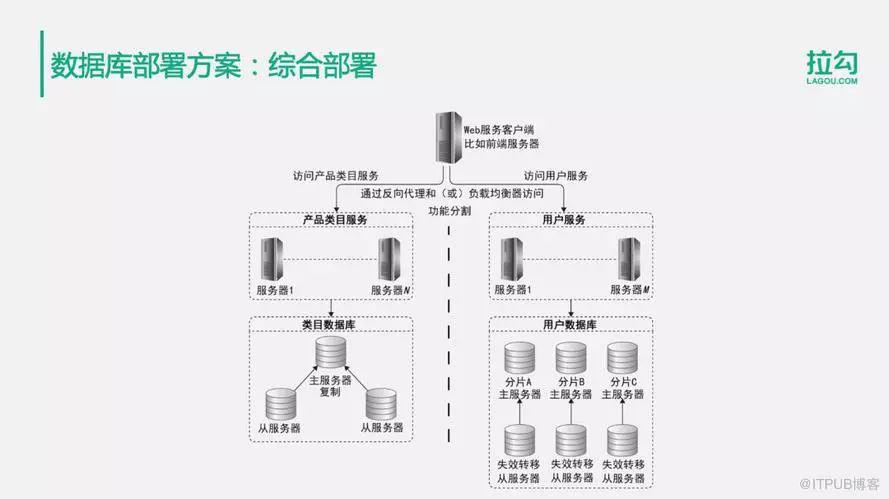
4.綜合部署方案
根據不同數據的訪問特點,使用不同的解決方案進行應對。比如說類目數據庫,也許通過主從復制就能夠滿足所有的訪問要求。但是如果用戶量特別大,進行主從復制或主主復制,還是不能夠滿足數據存儲以及寫操作的訪問壓力,這時候就就可以對用戶數據庫進行數據分片存儲了。同時每個分片數據庫也使用主從復制的方式進行部署。
關于如何解決億級用戶的分布式數據庫數據存儲問題就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





