溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“LSM的存儲以及定位”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“LSM的存儲以及定位”吧!
LSM的存儲
主要思想是將直接修改樹形結構,改為分幾個層級來完成。當完成第一個層級時就反饋完成,其他交由后臺來處理。
流程是先寫入memory table,之后merge到低級別的sstable,最后merge到高級別的sstable。
如下是Hbase的大體結構:
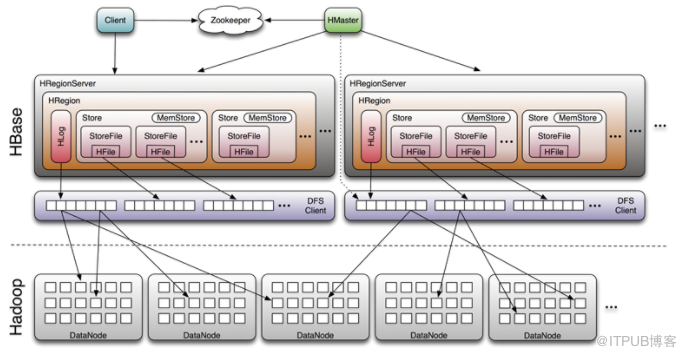
2. 定位
Trailer–這一段是定長的。保存了每一段的偏移量,讀取一個HFile時,會首先 讀取Trailer,Trailer保存了每個段的起始位置(段的Magic Number用來做安全check),然后,DataBlock Index會被讀取到內存中,這樣,當檢索某個key時,不需要掃描整個HFile,而只需從內存中找到key所在的block,通過一次磁盤io將整個 block讀取到內存中,再找到需要的key。DataBlock Index采用LRU機制淘汰。
首先,能快速找到行所在的region(分區),假設表有10億條記錄,占空間1TB, 分列成了500個region, 1個region占2個G. 最多讀取2G的記錄,就能找到對應記錄;
其次,是按列存儲的,其實是列族,假設分為3個列族,每個列族就是666M, 如果要查詢的東西在其中1個列族上,1個列族包含1個或者多個HStoreFile,假設一個HStoreFile是128M, 該列族包含5個HStoreFile在磁盤上. 剩下的在內存中。
再次,是排好序了的,你要的記錄有可能在最前面,也有可能在最后面,假設在中間,我們只需遍歷2.5個HStoreFile共300M
最后,每個HStoreFile(HFile的封裝),是以鍵值對(key-value)方式存儲,只要遍歷一個個數據塊中的key的位置,并判斷符合條件可以了。 一般key是有限的長度,假設跟value是1:19(忽略HFile上其它塊),最終只需要15M就可獲取的對應的記錄,按照磁盤的訪問100M/S,只需0.15秒。 加上塊緩存機制(LRU原則),會取得更高的效率。
感謝各位的閱讀,以上就是“LSM的存儲以及定位”的內容了,經過本文的學習后,相信大家對LSM的存儲以及定位這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





