溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“LSM-tree的基本原理及應用”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“LSM-tree的基本原理及應用”吧!
LSM-tree 在 NoSQL 系統里非常常見,基本已經成為必選方案了。今天介紹一下 LSM-tree 的主要思想,再舉一個 LevelDB 的例子。
LSM-tree
起源于 1996 年的一篇論文《The Log-Structured Merge-Tree (LSM-Tree)》,這篇論文 32 頁,我一直沒讀,對 LSM 的學習基本都來自頂會論文的背景知識以及開源系統文檔。今天的內容和圖片主要來源于 FAST'16 的《WiscKey: Separating Keys from Values in SSD-conscious Storage》。
先看名字,log-structured,日志結構的,日志是軟件系統打出來的,就跟人寫日記一樣,一頁一頁往下寫,而且系統寫日志不會寫錯,所以不需要更改,只需要在后邊追加就好了。各種數據庫的寫前日志也是追加型的,因此日志結構的基本就指代追加。注意他還是個 “Merge-tree”,也就是“合并-樹”,合并就是把多個合成一個。
好,不扯淡了,說正文了。
LSM-tree 是專門為 key-value 存儲系統設計的,key-value 類型的存儲系統最主要的就兩個個功能,put(k,v):寫入一個(k,v),get(k):給定一個 k 查找 v。
LSM-tree 最大的特點就是寫入速度快,主要利用了磁盤的順序寫,pk掉了需要隨機寫入的 B-tree。關于磁盤的順序和隨機寫可以參考:《硬盤的各種概念》
下圖是 LSM-tree 的組成部分,是一個多層結構,就更一個樹一樣,上小下大。首先是內存的 C0 層,保存了所有最近寫入的 (k,v),這個內存結構是有序的,并且可以隨時原地更新,同時支持隨時查詢。剩下的 C1 到 Ck 層都在磁盤上,每一層都是一個在 key 上有序的結構。
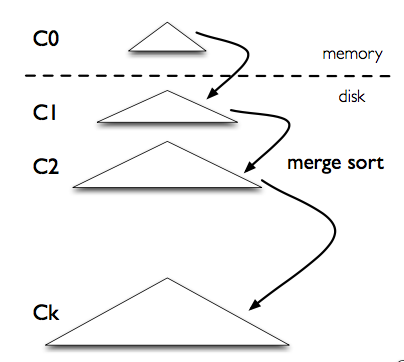
寫入流程:一個 put(k,v) 操作來了,首先追加到寫前日志(Write Ahead Log,也就是真正寫入之前記錄的日志)中,接下來加到 C0 層。當 C0 層的數據達到一定大小,就把 C0 層 和 C1 層合并,類似歸并排序,這個過程就是 Compaction(合并)。合并出來的新的 new-C1 會順序寫磁盤,替換掉原來的 old-C1。當 C1 層達到一定大小,會繼續和下層合并。合并之后所有舊文件都可以刪掉,留下新的。
注意數據的寫入可能重復,新版本需要覆蓋老版本。什么叫新版本,我先寫(a=1),再寫(a=233),233 就是新版本了。假如 a 老版本已經到 Ck 層了,這時候 C0 層來了個新版本,這個時候不會去管底下的文件有沒有老版本,老版本的清理是在合并的時候做的。
寫入過程基本只用到了內存結構,Compaction 可以后臺異步完成,不阻塞寫入。
查詢流程:在寫入流程中可以看到,最新的數據在 C0 層,最老的數據在 Ck 層,所以查詢也是先查 C0 層,如果沒有要查的 k,再查 C1,逐層查。
一次查詢可能需要多次單點查詢,稍微慢一些。所以 LSM-tree 主要針對的場景是寫密集、少量查詢的場景。
LSM-tree 被用在各種鍵值數據庫中,如 LevelDB,RocksDB,還有分布式行式存儲數據庫 Cassandra 也用了 LSM-tree 的存儲架構。
LevelDB
其實光看上邊這個模型還有點問題,比如將 C0 跟 C1 合并之后,新的寫入怎么辦?另外,每次都要將 C0 跟 C1 合并,這個后臺整理也很麻煩啊。這里以 LevelDB 為例,看一下實際系統是怎么利用 LSM-tree 的思想的。
下邊這個圖是 LevelDB 的架構,首先,LSM-tree 被分成三種文件,第一種是內存中的兩個 memtable,一個是正常的接收寫入請求的 memtable,一個是不可修改的immutable memtable。
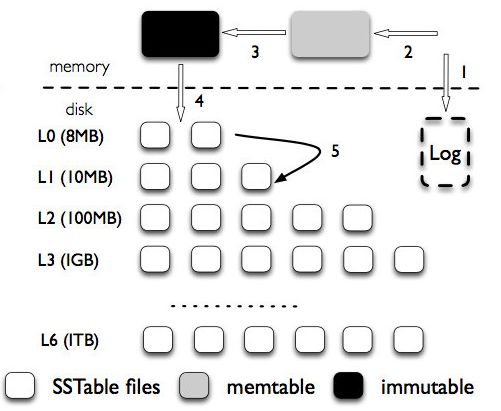
另外一部分是磁盤上的 SStable (Sorted String Table),有序字符串表,這個有序的字符串就是數據的 key。SStable 一共有七層(L0 到 L6)。下一層的總大小限制是上一層的 10 倍。
寫入流程:首先將寫入操作加到寫前日志中,接下來把數據寫到 memtable中,當 memtable 滿了,就將這個 memtable 切換為不可更改的 immutable memtable,并新開一個 memtable 接收新的寫入請求。而這個 immutable memtable 就可以刷磁盤了。這里刷磁盤是直接刷成 L0 層的 SSTable 文件,并不直接跟 L0 層的文件合并。
每一層的所有文件總大小是有限制的,每下一層大十倍。一旦某一層的總大小超過閾值了,就選擇一個文件和下一層的文件合并。就像玩 2048 一樣,每次能觸發合并都會觸發,這在 2048 里是最爽的,但是在系統里是挺麻煩的事,因為需要倒騰的數據多,但是也不是壞事,因為這樣可以加速查詢。
這里注意,所有下一層被影響到的文件都會參與 Compaction。合并之后,保證 L1 到 L6 層的每一層的數據都是在 key 上全局有序的。而 L0 層是可以有重疊的。
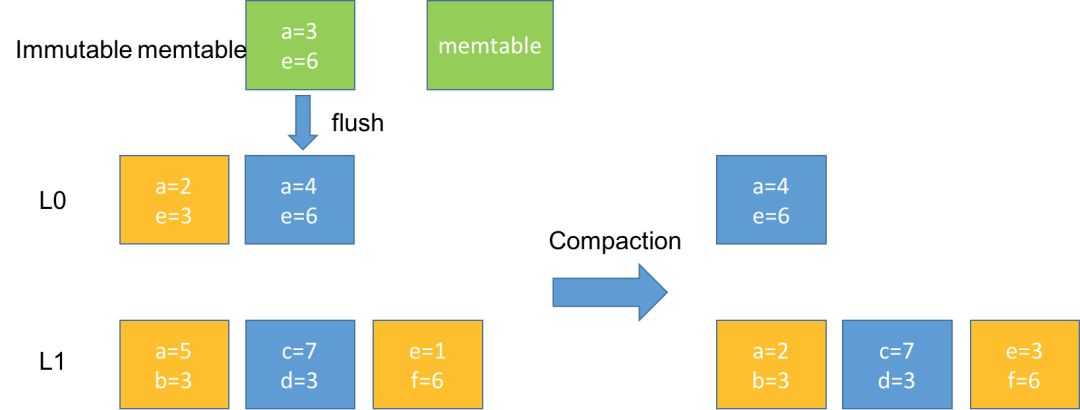
上圖是個例子,一個 immutable memtable 刷到 L0 層后,觸發 L0 和 L1 的合并,假如黃色的文件是涉及本次合并的,合并后,L0 層的就被刪掉了,L1 層的就更新了,L1 層還是全局有序的,三個文件的數據順序是 abcdef。
雖然 L0 層的多個文件在同一層,但也是有先后關系的,后面的同個 key 的數據也會覆蓋前面的。這里怎么區分呢?為每個key-value加個版本號。所以在 Compaction 時候應該只會留下最新的版本。
查詢流程:先查memtable,再查 immutable memtable,然后查 L0 層的所有文件,最后一層一層往下查。
LSM-tree讀寫放大
讀寫放大(read and write amplification)是 LSM-tree 的主要問題,這么定義的:讀寫放大 = 磁盤上實際讀寫的數據量 / 用戶需要的數據量。注意是和磁盤交互的數據量才算,這份數據在內存里計算了多少次是不關心的。比如用戶本來要寫 1KB 數據,結果你在內存里計算了1個小時,最后往磁盤寫了 10KB 的數據,寫放大就是 10,讀也類似。
寫放大:我們以 RocksDB 的 Level Style Compaction 機制為例,這種合并機制每次拿上一層的所有文件和下一層合并,下一層大小是上一層的 r 倍。這樣單次合并的寫放大就是 r 倍,這里是 r 倍還是 r+1 倍跟具體實現有關,我們舉個例子。
假如現在有三層,文件大小分別是:9,90,900,r=10。又寫了個 1,這時候就會不斷合并,1+9=10,10+90=100,100+900=1000。總共寫了 10+100+1000。按理來說寫放大應該為 1110/1,但是各種論文里不是這么說的,論文里說的是等號右邊的比上加號左邊的和,也就是10/1 + 100/10 + 1000/100 = 30 = r * level。個人感覺寫放大是一個過程,用一個數字衡量不太準確,而且這也只是最壞情況。
讀放大:為了查詢一個 1KB 的數據。最壞需要讀 L0 層的 8 個文件,再讀 L1 到 L6 的每一個文件,一共 14 個文件。而每一個文件內部需要讀 16KB 的索引,4KB的布隆過濾器,4KB的數據塊(看不懂不重要,只要知道從一個SSTable里查一個key,需要讀這么多東西就可以了)。一共 24*14/1=336倍。key-value 越小讀放大越大。
總結
關于 LSM-tree 的內容和 LevelDB 的設計思想就介紹完了,主要包括寫前日志 WAL,memtable,SStable 三個部分。逐層合并,逐層查找。LSM-tree 的主要劣勢是讀寫放大,關于讀寫放大可以通過一些其他策略去降低。
感謝各位的閱讀,以上就是“LSM-tree的基本原理及應用”的內容了,經過本文的學習后,相信大家對LSM-tree的基本原理及應用這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





