溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

Part1:寫在最前
在副本集架構中,當我們面臨寫多讀少,且大多數寫為update操作時,WT引擎的瓶頸初顯。這直接導致業務反饋寫入操作耗時較久等異常。為此,Percona版本的MongoDB里支持rocksDB存儲引擎,應對寫比較多的時候會顯得更加從容。
Part2:背景
在業務大量更新的場景中我們發現WT存儲引擎的disk lantency會比較高,在嘗試調大cache_size和并發數、eviction后效果不佳,因此我們嘗試使用rocksDB引擎代替。
Part3:措施
將write concern從majority變更為1,觀察效果
w: 數據寫入到number個節點才向用客戶端確認{w: 0} 對客戶端的寫入不需要發送任何確認,適用于性能要求高,但不關注正確性的場景
{w: 1} 默認的writeConcern,數據寫入到Primary就向客戶端發送確認
{w: “majority”} 數據寫入到副本集大多數成員后向客戶端發送確認,適用于對數據安全性要求比較高的場景,該選項會降低寫入性能
j: 寫入操作的journal持久化后才向客戶端確認默認為”{j: false},如果要求Primary寫入持久化了才向客戶端確認,則指定該選項為true
之前開了majority,慢的同時,在3.2.6版本后,也會同時開啟journal日志的磁盤寫入,導致磁盤耗時增加,進而導致寫入更慢,把writeconcern改到1,可以提升寫入速率
相關參數
writeConcernMajorityJournalDefault
Part4:日志抓取
2018-08-21T01:00:50.096+0800 I COMMAND [conn4072412] command kgcxxxt.$cmd command: update { update: "col", ordered: true, writeConcern: { w: "majority" }, $db: "kgcxxxt" } numYields:0 reslen:295 locks:{ Global: { acquireCount: { r: 2, w: 2 } }, Database: { acquireCount: { w: 2 } }, Collection: { acquireCount: { w: 1 } }, oplog: { acquireCount: { w: 1 } } } protocol:op_query 137ms
....
....
2018-08-21T01:00:50.096+0800 I COMMAND [conn4072176] command kgcxxxt.$cmd command: update { update: "col", ordered: true, writeConcern: { w: "majority" }, $db: "kgcxxxt" } numYields:0 reslen:295 locks:{ Global: { acquireCount: { r: 2, w: 2 } }, Database: { acquireCount: { w: 2 } }, Collection: { acquireCount: { w: 1 } }, oplog: { acquireCount: { w: 1 } } } protocol:op_query 137ms
Part5:監控
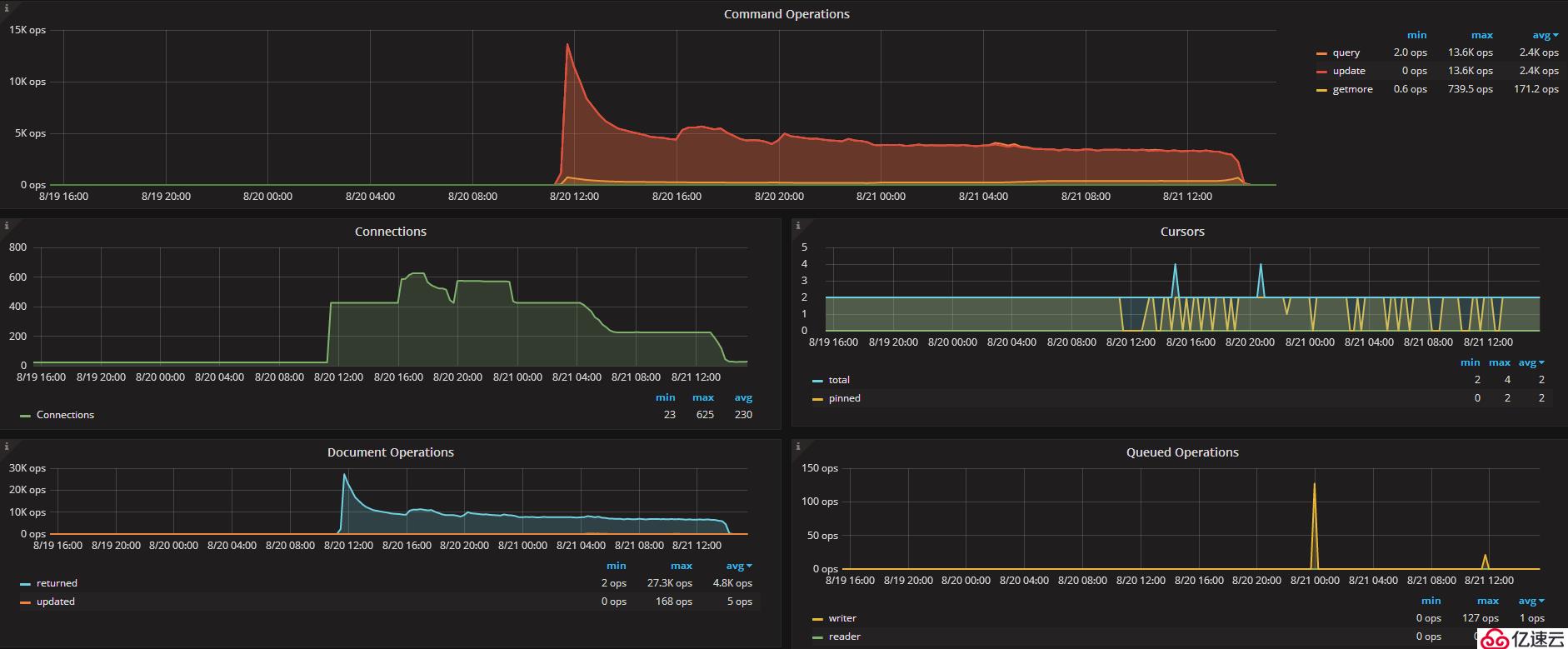
替換為write concern 1后,qps提高到15k
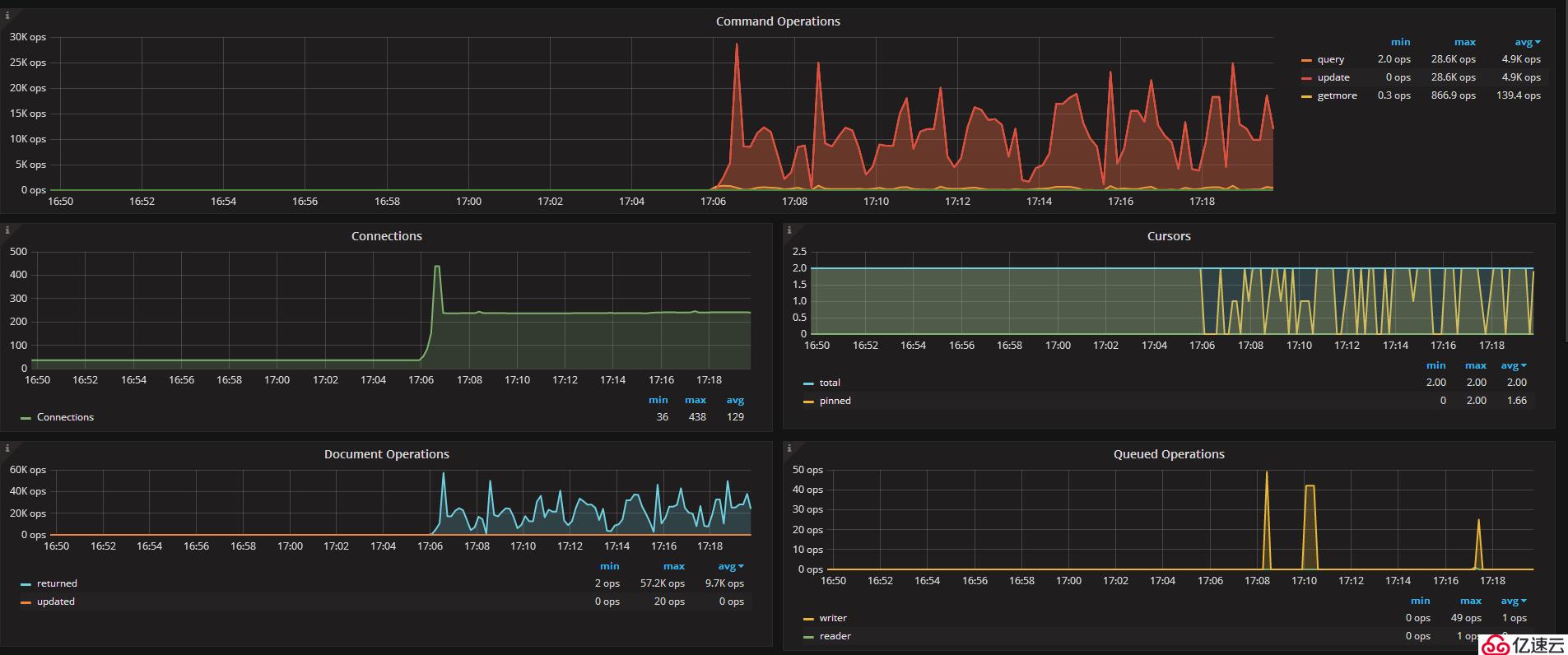
Part6:調大相關參數
嘗試調大cache_size和eviction
db.adminCommand({setParameter: 1, wiredTigerEngineRuntimeConfig: "cache_size=90G"})
db.adminCommand({setParameter: 1, wiredTigerEngineRuntimeConfig: "eviction=(threads_min=1,threads_max=8)"})可以看出,在調大參數后排隊的情況降下來了
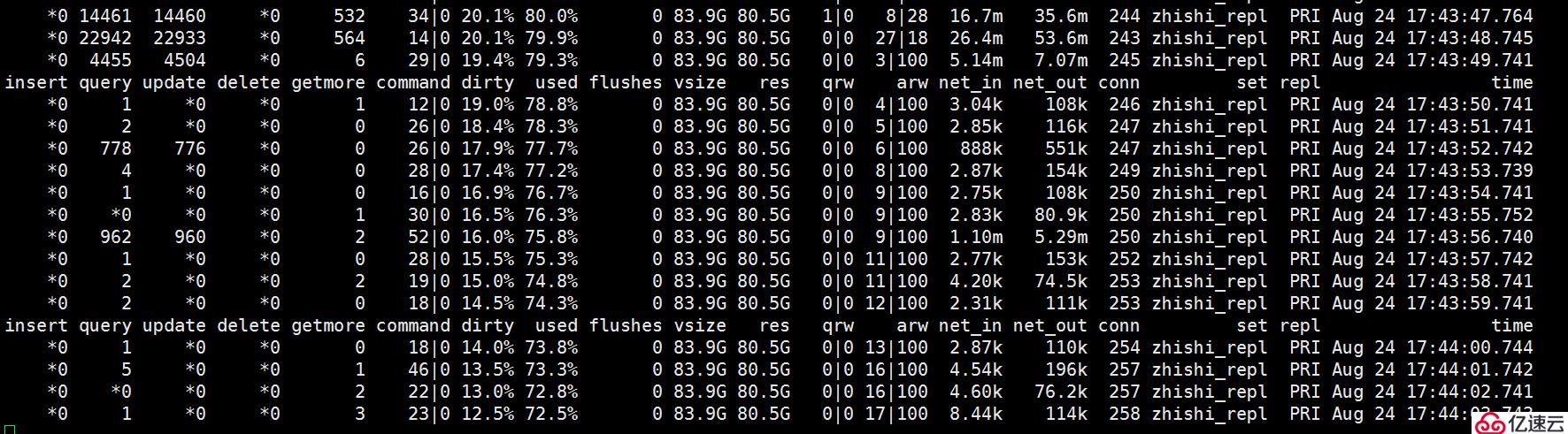
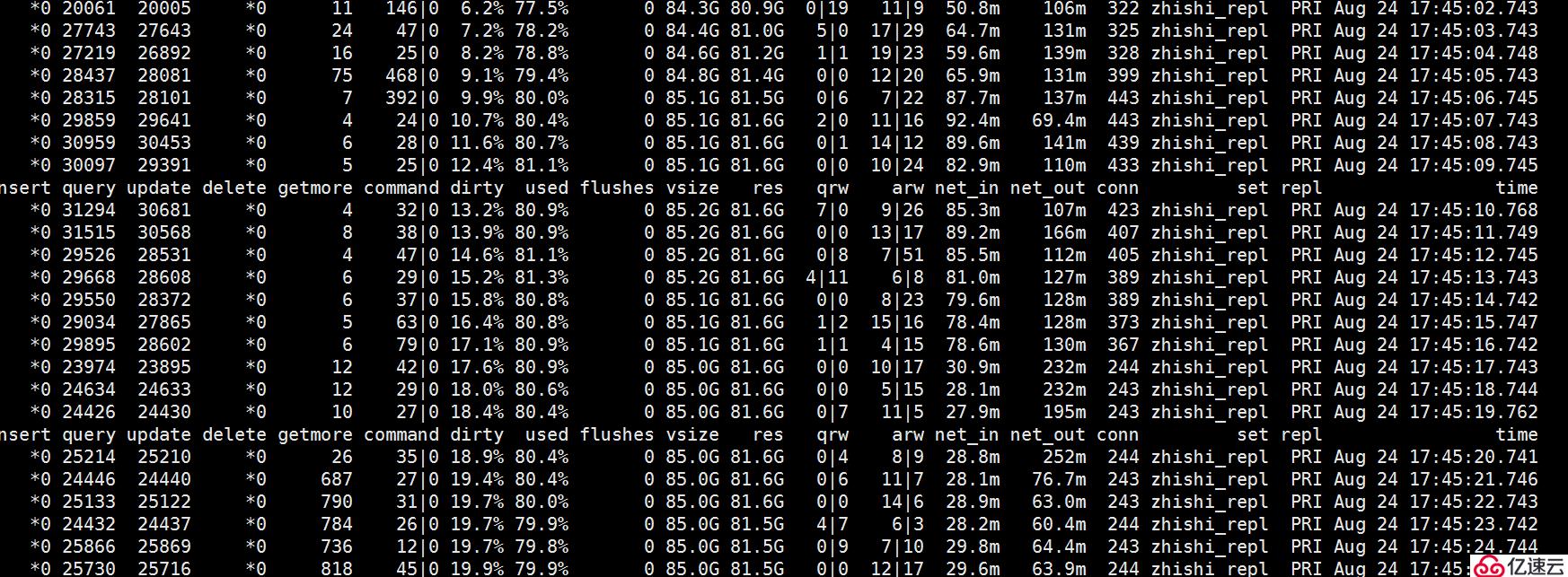
但是這一好景不長,沒過多久依舊出現了我們不希望看到的情況,因此后續我們決定采用rocksDB引擎。
Part1:整體架構
原有集群為3節點副本集架構,均使用WT存儲引擎。我們將其中一臺從庫換為rocksDB存儲引擎,觀察disk lantancy情況。
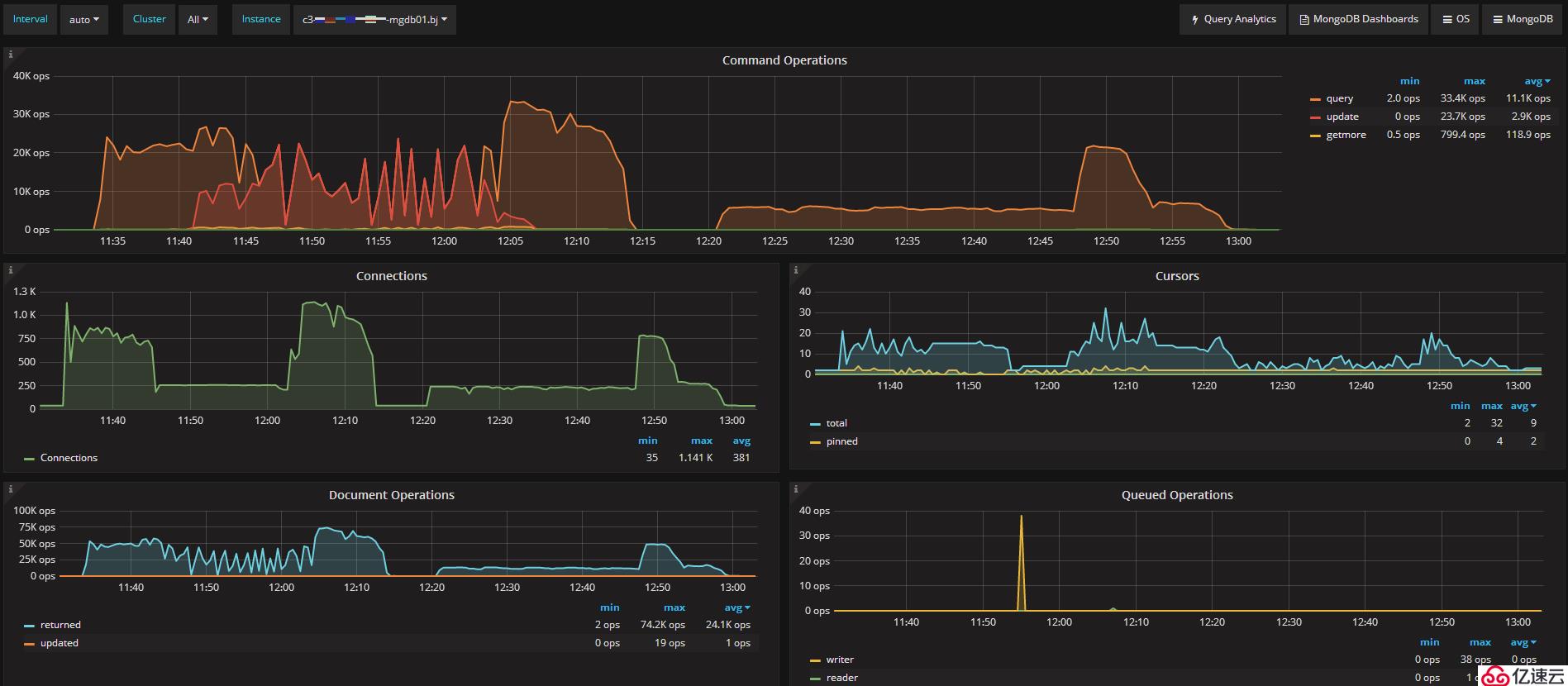
如上圖所示,可以看出主節點的QPS情況。
Part2:rocksDB引擎從庫
我們將其中一臺從庫配置為rocksDB引擎,RocksDB相對WT一大改進是采用LSM樹存儲引擎。Wiredtiger 基于 btree 結構組織數據,在一些極端場景下,因為 Cache eviction 及寫入放大的問題,可能導致 Write hang,細節可以到 MongoDB jira 上了解相關的issue,針對這些問題 MongoDB 官方團隊一直在優化,我們也看到 Wiredtiger 穩定性在不斷提升;而 RocksDB 是基于 LSM tree 結構組織數據,其針對寫入做了優化,將隨機寫入轉換成了順序寫入,能保證持續高效的數據寫入。在替換其中一臺從庫為rocksDB引擎后,我們將其與另外一臺WT引擎的從庫進行disk lantency的對比。
下圖為使用lsm Tree 結構的rocksDB存儲引擎從庫的disk lantency,可以看出都在1ms內。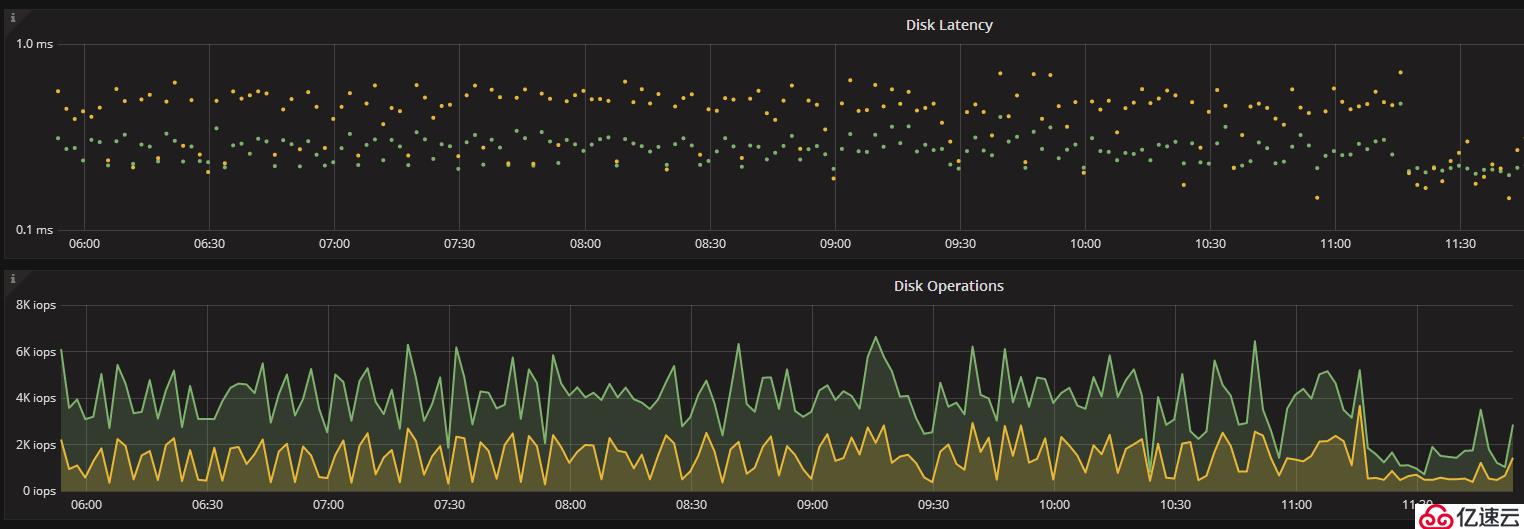
其qps如下圖所示,repl_delete在3k左右且連續穩定。
Part3:WT引擎從庫
下圖為使用WT存儲引擎從庫,其disk lantency和主庫一樣,寫入的lantency達到了8ms,讀也有4ms
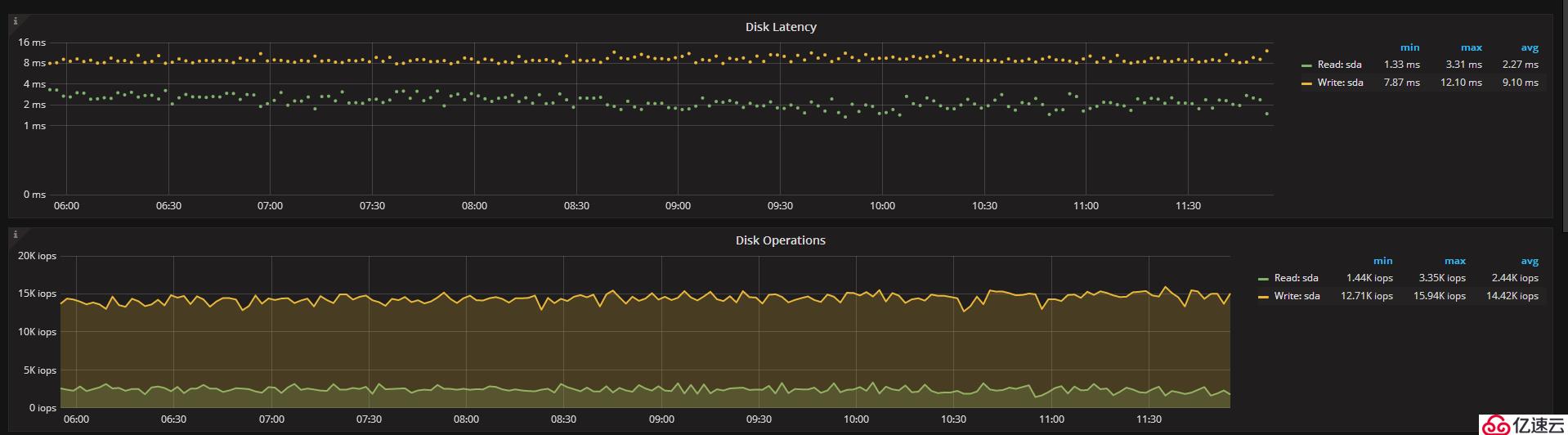
其qps在2.3k左右,且監控出現斷點,從庫出現因壓力大登錄超時的情況。
Part4:RocksDB引擎配置參數
storage: engine: rocksdb useDeprecatedMongoRocks: true dbPath: /home/work/mongodb/mongo_28000/data/db_28000 indexBuildRetry: true journal: enabled: true commitIntervalMs: 100 rocksdb: cacheSizeGB: 10 compression: snappy maxWriteMBPerSec: 1024 configString: write_buffer_size=512M;level0_slowdown_writes_trigger=12;min_write_buffer_number_to_merge=2; crashSafeCounters: false counters: true singleDeleteIndex: false
注釋1
#storage Options storage: engine: "rocksdb" useDeprecatedMongoRocks: true ##percona 3.6版本需要加 dbPath: /home/work/mongodb/mongo_10001/data rocksdb: cacheSizeGB: 10 # 默認是30% of physical memory compression: snappy maxWriteMBPerSec: 1024 #單位MB,rocks writes to storage 的速度,降低這個值可以減少讀延遲刺尖,但該值太低會降低寫入速度 configString: write_buffer_size=512M;level0_slowdown_writes_trigger=12;min_write_buffer_number_to_merge=2; crashSafeCounters: false #指定crash之后是否正確計數,開啟這個選項可能影響性能 counters: true #(默認開)指定是否使用advanced counters,關閉它可以提高寫性能 singleDeleteIndex: false
在添加 configString: write_buffer_size=512M;level0_slowdown_writes_trigger=12;min_write_buffer_number_to_merge=2; 參數后,磁盤延遲進一步降低,iops也進一步降低
這里需要注意的是,percona從3.6版本起不建議使用rocksdb,可能在下一個大版本移除,至于是否選用,要根據實際情況出發,最好能夠拉上業務一起進行一個壓測,滿足業務需求的,就是最好的。
https://www.percona.com/doc/percona-server-for-mongodb/LATEST/mongorocks.html
注釋2
rocksdb參數的調節一般是在三個因素之間做平衡:寫放大、讀放大、空間放大 1.flush選項: write_buffer_size: memtable的最大size,如果超過了這個值,RocksDB就會將其變成immutablememtable,并在使用另一個新的memtable max_write_buffer_number: 最大memtable的個數,如果activememtablefull了,并且activememtable加上immutablememtable的個數已經到了這個閥值,RocksDB就會停止后續的寫入。通常這都是寫入太快但是flush不及時造成的。 min_write_buffer_number_to_merge: 在flush到level0之前,最少需要被merge的memtable個數。如果這個值是2,那么當至少有兩個immutable的memtable的時候,RocksDB會將這兩個immutablememtable先merge,再flush到level0。預先merge能減小需要寫入的key的數據,譬如一個key在不同的memtable里面都有修改,那么我們可以merge成一次修改。但這個值太大了會影響讀取性能,因為Get會遍歷所有的memtable來看這個key是否存在。 舉例:write_buffer_size=512MB;max_write_buffer_number=5;min_write_buffer_number_to_merge=2; 假設寫入速率是16MB/s,那么每32s的時間都會有一個新的memtable生成,每64s的時間就會有兩個memtable開始merge。取決于實際的數據,需要flush到level0的大小可能在512MB和1024MB之間,一次flush也可能需要幾秒的時間 (取決于盤的順序寫入速度)。最多有5個memtable,當達到這個閥值,RocksDB就會組織后續的寫入了。 2.LevelStyleCompaction: level0_slowdown_writes_trigger: 當level0的文件數據達到這個值的時候,就開始進行level0到level1的compaction。所以通常level0的大小就是write_buffer_size*min_write_buffer_number_to_merge*level0_file_num_compaction_trigger。 max_background_compactions: 是指后臺壓縮的最大并發線程數,默認為1,但為了充分利用你的CPU和存儲,可以將該值配置為機器核數 max_background_flushes: 并發執行flush操作的最大線程數,通常設置為1已經是足夠了。
如下是使用 sysbench 進行的一個簡單的 insert 測試,insert 的集合默認帶一個二級索引,在剛開始 Wiredtiger 的寫入性能遠超 RocksDB,而隨著數據量越來越大,WT的寫入能力開始下降,而 RocksDB 的寫入一直比較穩定。
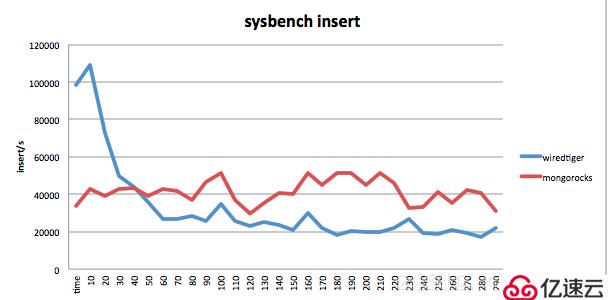
更多 Wiredtiger、Mongorocks 的對比可以參考 Facebook 大神在 Percona Live 上的技術分享。
https://www.percona.com/live/17/sessions/comparing-mongorocks-wiredtiger-and-mmapv1-performance-and-efficiency?spm=a2c4e.11153940.blogcont231377.21.6c457b684BOXvj
——總結——
通過本文,我們了解到RocksDB引擎的特點和與WT存儲引擎的disk lantency對比,不同的業務場景不同,因此具體使用什么存儲引擎,還需要結合具體業務來進行評估。由于筆者的水平有限,編寫時間也很倉促,文中難免會出現一些錯誤或者不準確的地方,不妥之處懇請讀者批評指正。喜歡筆者的文章,右上角點一波關注,謝謝~
參考資料:
https://www.percona.com/doc/percona-server-for-mongodb/LATEST/mongorocks.html
https://yq.aliyun.com/articles/231377
https://www.percona.com/live/17/sessions/comparing-mongorocks-wiredtiger-and-mmapv1-performance-and-efficiency?spm=a2c4e.11153940.blogcont231377.21.6c457b684BOXvj
歷經1年時間,和我的摯友張甦先生合著了這本《MongoDB運維實戰》,感謝電子工業出版社,感謝張甦先生讓我圓了出書夢!感謝友東哥、李丹哥、李彬哥、張良哥的書評!感謝友飛哥、汝林哥在我入職小米以來工作上的指導和幫助!感謝我的愛人李愛璇女士,沒有你在背后支持,我不可能完成這項龐大的工程。京東自營有貨,喜歡MongoDB的同學歡迎支持!

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





