溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Redis中內部數據結構dict的作用是什么,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
dict的數據結構定義
為了實現增量式重哈希(incremental rehashing),dict的數據結構里包含兩個哈希表。在重哈希期間,數據從第一個哈希表向第二個哈希表遷移。
dict的C代碼定義如下(出自Redis源碼dict.h):
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;為了能更清楚地展示dict的數據結構定義,我們用一張結構圖來表示它。如下。
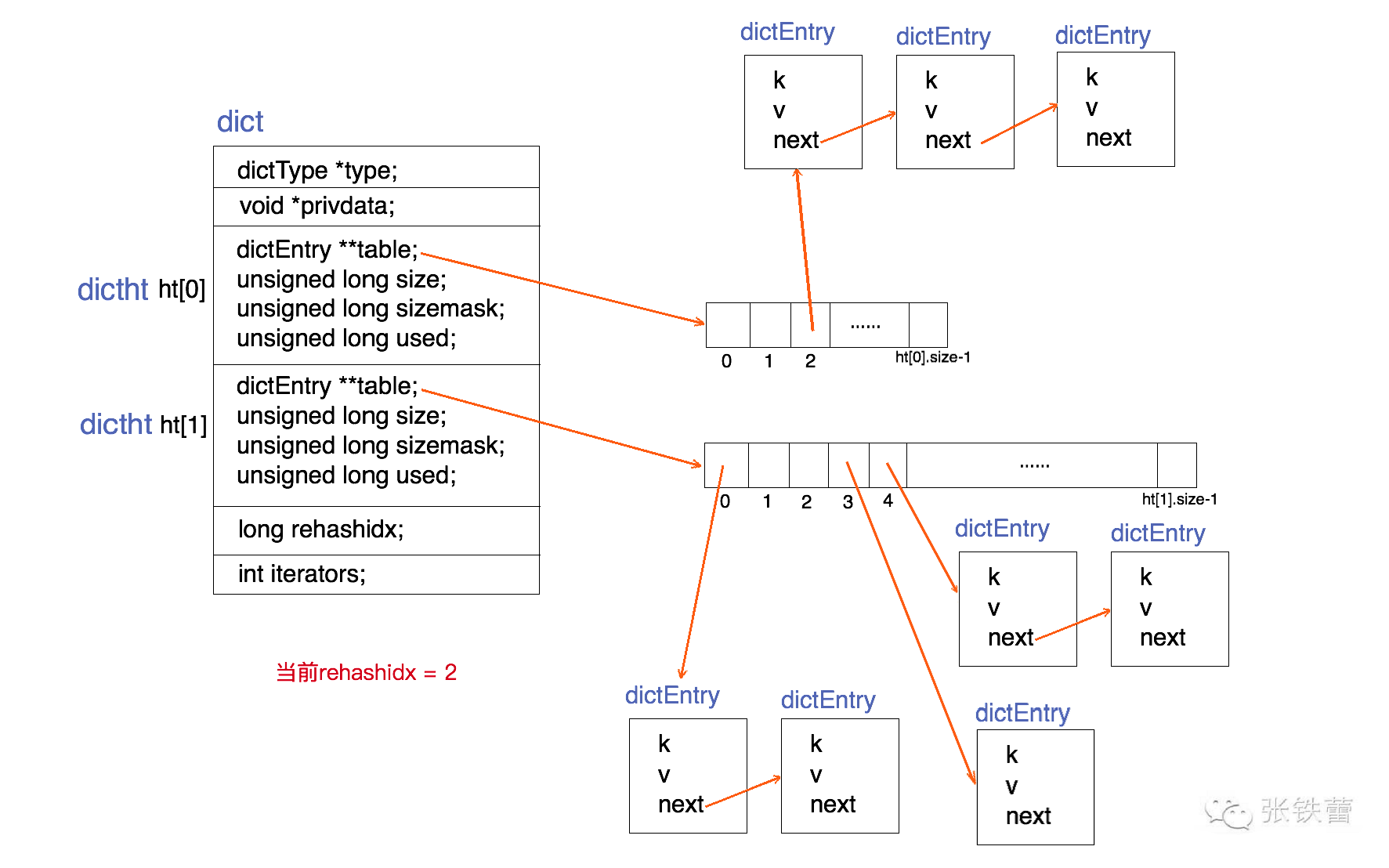
結合上面的代碼和結構圖,可以很清楚地看出dict的結構。一個dict由如下若干項組成:
一個指向dictType結構的指針(type)。它通過自定義的方式使得dict的key和value能夠存儲任何類型的數據。
一個私有數據指針(privdata)。由調用者在創建dict的時候傳進來。
兩個哈希表(ht[2])。只有在重哈希的過程中,ht[0]和ht[1]才都有效。而在平常情況下,只有ht[0]有效,ht[1]里面沒有任何數據。上圖表示的就是重哈希進行到中間某一步時的情況。
當前重哈希索引(rehashidx)。如果rehashidx = -1,表示當前沒有在重哈希過程中;否則,表示當前正在進行重哈希,且它的值記錄了當前重哈希進行到哪一步了。
當前正在進行遍歷的iterator的個數。這不是我們現在討論的重點,暫時忽略。
dictType結構包含若干函數指針,用于dict的調用者對涉及key和value的各種操作進行自定義。這些操作包含:
hashFunction,對key進行哈希值計算的哈希算法。
keyDup和valDup,分別定義key和value的拷貝函數,用于在需要的時候對key和value進行深拷貝,而不僅僅是傳遞對象指針。
keyCompare,定義兩個key的比較操作,在根據key進行查找時會用到。
keyDestructor和valDestructor,分別定義對key和value的析構函數。
私有數據指針(privdata)就是在dictType的某些操作被調用時會傳回給調用者。
需要詳細察看的是dictht結構。它定義一個哈希表的結構,由如下若干項組成:
一個dictEntry指針數組(table)。key的哈希值最終映射到這個數組的某個位置上(對應一個bucket)。如果多個key映射到同一個位置,就發生了沖突,那么就拉出一個dictEntry鏈表。
size:標識dictEntry指針數組的長度。它總是2的指數。
sizemask:用于將哈希值映射到table的位置索引。它的值等于(size-1),比如7, 15, 31, 63,等等,也就是用二進制表示的各個bit全1的數字。每個key先經過hashFunction計算得到一個哈希值,然后計算(哈希值 & sizemask)得到在table上的位置。相當于計算取余(哈希值 % size)。
used:記錄dict中現有的數據個數。它與size的比值就是裝載因子(load factor)。這個比值越大,哈希值沖突概率越高。
dictEntry結構中包含k, v和指向鏈表下一項的next指針。k是void指針,這意味著它可以指向任何類型。v是個union,當它的值是uint64_t、int64_t或double類型時,就不再需要額外的存儲,這有利于減少內存碎片。當然,v也可以是void指針,以便能存儲任何類型的數據。
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}dictCreate為dict的數據結構分配空間并為各個變量賦初值。其中兩個哈希表ht[0]和ht[1]起始都沒有分配空間,table指針都賦為NULL。這意味著要等第一個數據插入時才會真正分配空間。
#define dictIsRehashing(d) ((d)->rehashidx != -1)
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
unsigned int h, idx, table;
if (d->ht[0].used + d->ht[1].used == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}上述dictFind的源碼,根據dict當前是否正在重哈希,依次做了這么幾件事:
如果當前正在進行重哈希,那么將重哈希過程向前推進一步(即調用_dictRehashStep)。實際上,除了查找,插入和刪除也都會觸發這一動作。這就將重哈希過程分散到各個查找、插入和刪除操作中去了,而不是集中在某一個操作中一次性做完。
計算key的哈希值(調用dictHashKey,里面的實現會調用前面提到的hashFunction)。
先在第一個哈希表ht[0]上進行查找。在table數組上定位到哈希值對應的位置(如前所述,通過哈希值與sizemask進行按位與),然后在對應的dictEntry鏈表上進行查找。查找的時候需要對key進行比較,這時候調用dictCompareKeys,它里面的實現會調用到前面提到的keyCompare。如果找到就返回該項。否則,進行下一步。
判斷當前是否在重哈希,如果沒有,那么在ht[0]上的查找結果就是最終結果(沒找到,返回NULL)。否則,在ht[1]上進行查找(過程與上一步相同)。
下面我們有必要看一下增量式重哈希的_dictRehashStep的實現。
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}dictRehash每次將重哈希至少向前推進n步(除非不到n步整個重哈希就結束了),每一步都將ht[0]上某一個bucket(即一個dictEntry鏈表)上的每一個dictEntry移動到ht[1]上,它在ht[1]上的新位置根據ht[1]的sizemask進行重新計算。rehashidx記錄了當前尚未遷移(有待遷移)的ht[0]的bucket位置。
如果dictRehash被調用的時候,rehashidx指向的bucket里一個dictEntry也沒有,那么它就沒有可遷移的數據。這時它嘗試在ht[0].table數組中不斷向后遍歷,直到找到下一個存有數據的bucket位置。如果一直找不到,則最多走n*10步,本次重哈希暫告結束。
最后,如果ht[0]上的數據都遷移到ht[1]上了(即d->ht[0].used == 0),那么整個重哈希結束,ht[0]變成ht[1]的內容,而ht[1]重置為空。
根據以上對于重哈希過程的分析,我們容易看出,本文前面的dict結構圖中所展示的正是rehashidx=2時的情況,前面兩個bucket(ht[0].table[0]和ht[0].table[1])都已經遷移到ht[1]上去了。
dictAdd插入新的一對key和value,如果key已經存在,則插入失敗。
dictReplace也是插入一對key和value,不過在key存在的時候,它會更新value。
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
/* Compute the key hash value */
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return -1;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return idx;
}以上是dictAdd的關鍵實現代碼。我們主要需要注意以下幾點:
它也會觸發推進一步重哈希(_dictRehashStep)。
如果正在重哈希中,它會把數據插入到ht[1];否則插入到ht[0]。
在對應的bucket中插入數據的時候,總是插入到dictEntry的頭部。因為新數據接下來被訪問的概率可能比較高,這樣再次查找它時就比較次數較少。
_dictKeyIndex在dict中尋找插入位置。如果不在重哈希過程中,它只查找ht[0];否則查找ht[0]和ht[1]。
_dictKeyIndex可能觸發dict內存擴展(_dictExpandIfNeeded,它將哈希表長度擴展為原來兩倍,具體請參考dict.c中源碼)。
dictReplace在dictAdd基礎上實現,如下:
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, auxentry;
/* Try to add the element. If the key
* does not exists dictAdd will suceed. */
if (dictAdd(d, key, val) == DICT_OK)
return 1;
/* It already exists, get the entry */
entry = dictFind(d, key);
/* Set the new value and free the old one. Note that it is important
* to do that in this order, as the value may just be exactly the same
* as the previous one. In this context, think to reference counting,
* you want to increment (set), and then decrement (free), and not the
* reverse. */
auxentry = *entry;
dictSetVal(d, entry, val);
dictFreeVal(d, &auxentry);
return 0;
}在key已經存在的情況下,dictReplace會同時調用dictAdd和dictFind,這其實相當于兩次查找過程。這里Redis的代碼不夠優化。
dictDelete的源碼這里忽略,具體請參考dict.c。需要稍加注意的是:
dictDelete也會觸發推進一步重哈希(_dictRehashStep)
如果當前不在重哈希過程中,它只在ht[0]中查找要刪除的key;否則ht[0]和ht[1]它都要查找。
刪除成功后會調用key和value的析構函數(keyDestructor和valDestructor)。
上述內容就是Redis中內部數據結構dict的作用是什么,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





