溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python 對文件目錄操作的方法,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
概述
I/O操作不僅包括屏幕輸入輸出,還包括文件的讀取與寫入,Python提供了很多必要的方法和功能,進行文件及文件夾的相關操作。本文主要通過兩個簡單的小例子,簡述Python在文件夾及文件的應用,僅供學習分享使用,如有不足之處,還請指正。
涉及知識點
os模塊:os 模塊提供了非常豐富的方法用來處理文件和目錄。
open方法:open方法用于打開一個文件,用于讀取和寫入。
實例1:獲取指定目錄下所有的文件大小,并找出最大文件及最小文件
分解步驟:
遍歷文件夾下所有的子文件及子文件夾(需要遞歸),并計算每一個文件的大小
計算所有文件的大小總和
找出最大文件及最小文件
核心代碼
定義一個方法get_file_size,獲取單個文件的大小,單位有KB和MB兩種。關鍵點如下所示:
def get_file_size(file_path, KB=False, MB=False):
"""獲取文件大小"""
size = os.path.getsize(file_path)
if KB:
size = round(size / 1024, 2)
elif MB:
size = round(size / 1024 * 1024, 2)
else:
size = size
return size定義一個方法list_files,遍歷指定文件目錄,并存入字典當中。關鍵點如下所示:
def list_files(root_dir):
"""遍歷文件"""
if os.path.isfile(root_dir): # 如果是文件
size = get_file_size(root_dir, KB=True)
file_dict[root_dir] = size
else:
# 如果是文件夾,則遍歷
for f in os.listdir(root_dir):
# 拼接路徑
file_path = os.path.join(root_dir, f)
if os.path.isfile(file_path):
# 如果是一個文件
size = get_file_size(file_path, KB=True)
file_dict[file_path] = size
else:
list_files(file_path)計算總大小和最大文件及最小文件,如下所示:
通過比較字典value的大小,返回對應的key的名稱。關鍵點如下所示:
if __name__ == '__main__':
list_files(root_dir)
# print( len(file_dict))
# 計算文件目錄大小
total_size = 0
# 遍歷字典的key
for file in file_dict:
total_size += file_dict[file]
print('total size is : %.2f' % total_size)
# 找最大最小文件
max_file = max(file_dict, key=lambda x: file_dict[x])
min_file = min(file_dict, key=lambda x: file_dict[x])
print('max file is : ', max_file, '\n file size is :', file_dict[max_file])
print('min file is : ', min_file, '\n file size is :', file_dict[min_file])實例2:將兩個文本文件中的內容進行合并,并保存到文件中
兩個文件內容,如下圖所示:
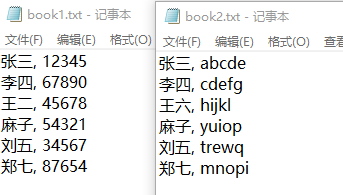
分解步驟:
核心代碼
定義一個函數read_book,用于讀取兩個文件的內容。關鍵點如下所示:
def read_book():
"""讀取內容"""
# 讀取一個文件
file1 = open('book1.txt', 'r', encoding='UTF-8')
lines1 = file1.readlines()
file1.close()
for line in lines1:
line = line.strip() # 去空白
content = line.split(',')
book1[content[0]] = content[1]
# 另一種方式,讀取另一個文件,不需要close,會自動關閉
with open('book2.txt', 'r', encoding='UTF-8') as file2:
lines2 = file2.readlines()
for line in lines2:
line = line.strip() # 去空白
content = line.split(',')
book2[content[0]] = content[1]定義一個函數,用于合并內容,并保存。關鍵點如下所示:
def merge_book():
"""合并內容"""
lines = [] # 定義一個空列表
header = '姓名\t 電話\t 文本\n'
lines.append(header)
# 遍歷第一個字典
for key in book1:
line = ''
if key in book2.keys():
line = line + '\t'.join([key, book1[key], book2[key]])
line += '\n'
else:
line = line + '\t'.join([key, book1[key], ' *****'])
line += '\n'
lines.append(line)
# 遍歷第2個,將不包含在第1個里面的寫入
for key in book2:
line = ''
if key not in book1.keys():
line = line + '\t'.join([key, ' *****', book2[key]])
line += '\n'
lines.append(line)
# 寫入book3
with open('book3.txt', 'w', encoding='UTF-8') as f:
f.writelines(lines)整體調用,如下所示:
if __name__ == '__main__': # 讀取內容 read_book() # 合并內容 merge_book() # print(book1) # print(book2)
最后拼接后生成的文件,如下所示:
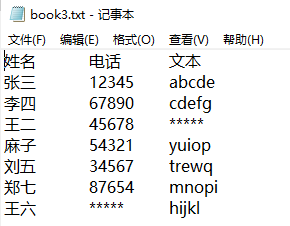
看完了這篇文章,相信你對Python 對文件目錄操作的方法有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





