溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
文件和目錄操作是很常見的功能,這里做個簡單的總結,包括注意事項和實際的實現代碼,基本日常開發都夠用了
目錄操作
判斷目錄或是文件是否存在
os.path.exists(path)
判斷是否是文件或是目錄
# 如果文件或是目錄不存在也會返回False os.path.isfile(path) os.path.isdir(path)
創建/刪除目錄
os.mkdir(path) os.rmdir(path)
得到當前的目錄名稱
os.path.split(dir_path)[1]
這個方法既簡單又實用,比如我們輸入一個目錄路徑:
os.path.split('/usr/projects/project1')[1]
# 輸出
project1
# 實際上,上面的代碼是分了2步走:
# 第1步:利用os.path.split方法分割路徑
os.path.split('/usr/projects/project1')
# 輸出
('/usr/projects', 'project1')
# 然后第2步取出第2個結果,也就是當前的目錄名字
循環遍歷目錄
循環遍歷目錄有2種方式,一種是常規的遞歸方法,類似下面這樣:
def list_file(path): for file in os.listdir(path): if os.path.isdir(os.path.join(path, file)): list_file(os.path.join(path, file)) print(file)
還有一種更好的方式就是用os.walk方法,類似下面這樣:
def list_file_by_walk(dir_path): for home, dirs, files in os.walk(dir_path): print(home) print(dirs) # files中是文件列表 for file_name in files: print(file_name)
os.walk方法的幾個參數簡單介紹一下:
所以從上面的參數中可以看出,os.walk方法會逐一地遍歷初始目錄下面的所有目錄和文件
常見的文件操作
跟上面得到目錄名類似的是得到文件的后綴
os.path.splitext(file_path)
這個方法如果輸入的是文件的路徑,比如:
a = '/usr/projects/project1/test.txt'
os.path.splitext(a)
# 輸出
('/usr/projects/project1/test', '.txt')
# 所以跟上面類似,我們可以直接拿到文件的后綴
os.path.splitext(a)[1]
文件的全路徑
# 需要文件的目錄路徑和文件名 os.path.join(dir_name, file_name)
這個方法也很有用,因為我們在打開一個文件的時候都需要知道文件的路徑
比如在上面循環遍歷目錄的例子中,我們可以這樣打開編輯文件:
def list_file_by_walk(dir_path):
for home, dirs, files in os.walk(dir_path):
print(home)
print(dirs)
# files中是文件列表
for file_name in files:
# 這個file_name只是一個文件名
print(file_name)
# 如果我們需要打開文件進行編輯讀寫操作,那就需要文件的路徑
# 用os.path.join方法就可以快速得到文件路徑
file_path = os.path.join(home, file_name)
需要注意的是,不要直接用字符串相加的方式來拼接,這樣子會有兼容問題,比如windows上可能路徑就是錯的了
讀寫文件
打開文件
with open(file, 'r') as f:
for line in f.readlines():
print line
大家只要記住上面打開文件的格式就行了,也就是這句:
with open(file_path, 打開的模式) as f # 我們就拿到了文件對象f,可以對文件進行操作了,比如讀寫等
原因是文件讀寫是IO操作,需要及時關閉打開的文件,上述with open() as f的方式會自動幫你關閉文件的,免得自己忘記關
文件的打開模式
文件的打開模式有很多種,比如只讀、只寫、追加模式等等,具體可以見下圖:
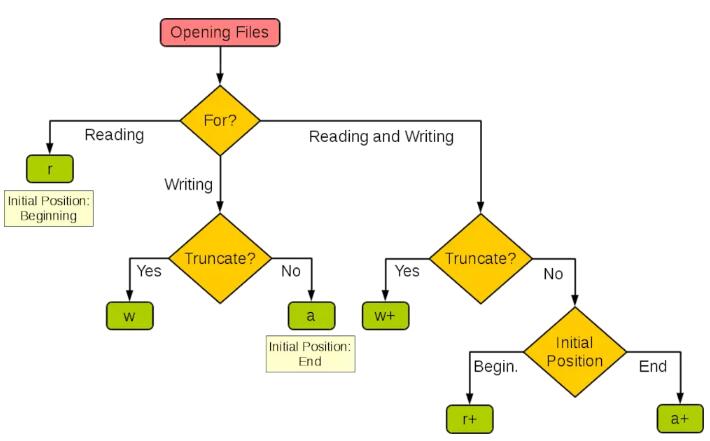
文件讀寫模式--來源于網絡
模式有這么多,掌握常見的幾種就可以了,其他的等用到了再去了解。需要注意以下幾點:
創建文件,只需要打開一個文件即可:
# 只要這樣一句就創建了一個新文件,也就是打開以后關閉文件 with open(new_file, 'w') as f:
需要特別注意的是,以w只寫模式打開一個文件后會把原文件的內容清除!所以如果在遍歷文件的時候,你想同時修改文件就不能簡單的以w只寫模式打開了。
在遍歷文件的時候想同時修改文件怎么辦呢?注意這里說的是修改,比如修改某一行。
修改文件的某一部分
這里舉例在遍歷文件的時候想修改文件,比如以上面遍歷目錄文件的例子:
def list_file_by_walk(dir_path):
for home, dirs, files in os.walk(dir_path):
print(home)
print(dirs)
# files中是文件列表
for file_name in files:
# 這個file_name只是一個文件名
print(file_name)
# 如果我們需要打開文件進行編輯讀寫操作,那就需要文件的路徑
# 用os.path.join方法就可以快速得到文件路徑
file_path = os.path.join(home, file_name)
# 這個時候我想修改這個文件的內容,要怎么做呢?
需要注意的是,讀寫模式需要管理文件指針,比較麻煩,寫讀模式,則會把原先的內容都清除,所以都不適合
一種思路是我先以只讀模式打開,然后遍歷文件的內容保存起來,比如:
with open(file, 'r') as f:
for line in f.readlines():
print line
# 這里就可以把文件的內容一行行保存起來
# 找到需要修改的行,修改以后保存
保存以后再以只讀模式打開文件,寫入即可。
另一種思路是我打開原文件的同時,再打開另一個臨時文件用于寫入,比如這樣:
with open(file, 'r') as f, open(cache_file_path, 'w') as w:
for line in f.readlines():
# 中間可以對f文件中的內容進行過濾或是修改
w.write(line)
# 完了以后需要刪除原文件,然后把臨時文件的名字修改成原來文件的名字即可
這里就順道引出了,刪除和重命名文件的方法
os.remove(file) os.rename(cache_file_path, file)
總結
以上就是Python文件和目錄操作的常用知識點和方法總結,建議大家收藏起來,以后方便隨時查看。
好了,以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





