溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下ol7.7安裝部署4節點spark3.0.0分布式集群的方法,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
為學習spark,虛擬機中開4臺虛擬機安裝spark3.0.0
底層hadoop集群已經安裝好,見ol7.7安裝部署4節點hadoop 3.2.1分布式集群學習環境
首先,去http://spark.apache.org/downloads.html下載對應安裝包
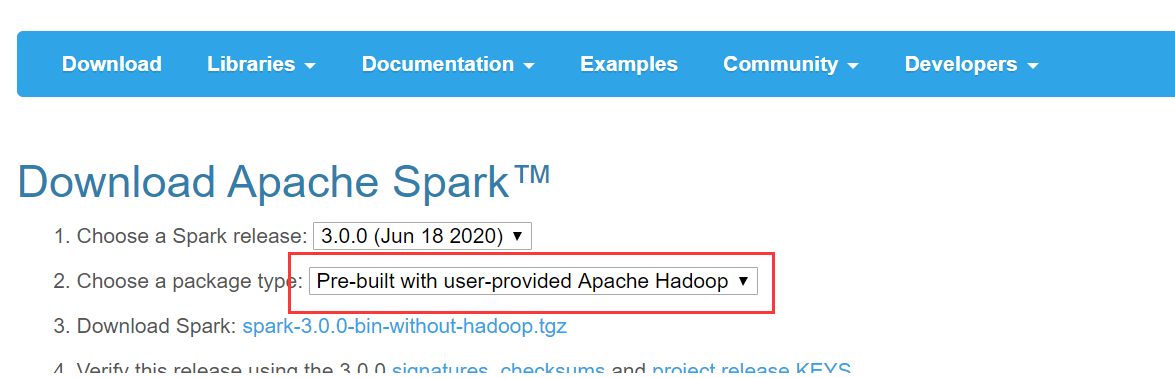
解壓
[hadoop@master ~]$ sudo tar -zxf spark-3.0.0-bin-without-hadoop.tgz -C /usr/local [hadoop@master ~]$ cd /usr/local [hadoop@master /usr/local]$ sudo mv ./spark-3.0.0-bin-without-hadoop/ spark [hadoop@master /usr/local]$ sudo chown -R hadoop: ./spark
四個節點都添加環境變量
export SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
配置spark
spark目錄中的conf目錄下cp ./conf/spark-env.sh.template ./conf/spark-env.sh后面添加
export SPARK_MASTER_IP=192.168.168.11 export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export SPARK_LOCAL_DIRS=/usr/local/hadoop export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
然后配置work節點,cp ./conf/slaves.template ./conf/slaves修改為
master
slave1
slave2
slave3
寫死JAVA_HOME,sbin/spark-config.sh最后添加
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
復制spark目錄到其他節點
sudo scp -r /usr/local/spark/ slave1:/usr/local/ sudo scp -r /usr/local/spark/ slave2:/usr/local/ sudo scp -r /usr/local/spark/ slave3:/usr/local/ sudo chown -R hadoop ./spark/
...
啟動集群
先啟動hadoop集群/usr/local/hadoop/sbin/start-all.sh
然后啟動spark集群
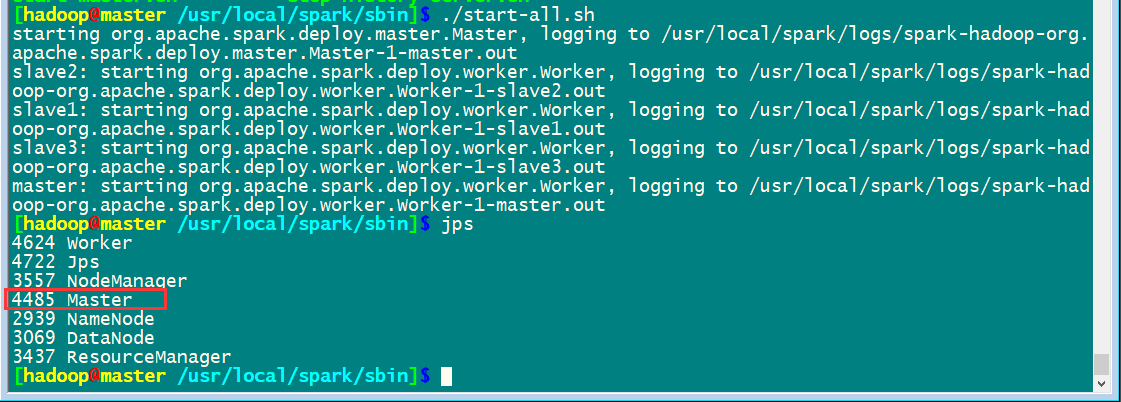
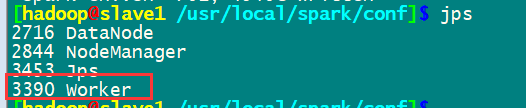
通過master8080端口監控
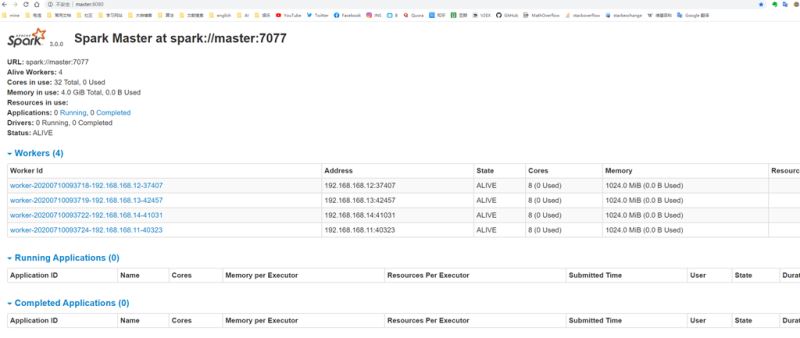
完成安裝
看完了這篇文章,相信你對ol7.7安裝部署4節點spark3.0.0分布式集群的方法有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





