溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Docker Swarm 和 Docker Compose 一樣,都是 Docker 官方容器編排項目,但不同的是,Docker Compose 是一個在單個服務器或主機上創建多個容器的工具,而 Docker Swarm 則可以在多個服務器或主機上創建容器集群服務,對于微服務的部署,顯然 Docker Swarm 會更加適合。
從 Docker 1.12.0 版本開始,Docker Swarm 已經包含在 Docker 引擎中(docker swarm),并且已經內置了服務發現工具,我們就不需要像之前一樣,再配置 Etcd 或者 Consul 來進行服務發現配置了。
Docker Swarm集群中有三個角色:manager(管理者);worker(實際工作者)以及service(服務)。
在上面的三個角色中,其本質上與我們公司的組織架構類似,有領導(manager),有搬磚的(worker),而領導下發給搬磚者的任務,就是Docker Swarm中的service(服務)。
需要注意的是,在一個Docker Swarm群集中,每臺docker服務器的角色可以都是manager,但是,不可以都是worker,也就是說,不可以群龍無首,并且,參與群集的所有主機名,千萬不可以沖突。
這里通過一個案例來展示Docker Swarm集群的配置。
博文大綱:
一、環境準備
二、配置主機docker01
三、配置docker02及docker03加入Swarm群集
四、搭建registry私有倉庫
五、docker01部署docker Swarm群集的web UI界面
六、docker Swarm群集的service服務配置
七、實現docker容器的擴容及縮容
八、附加——docker Swarm群集常用命令
九、docker Swarm總結
在上述主機中,將指定主機docker01為manager的角色,其他主機的角色為worker。
以下操作,將初始化一個Swarm群集,并指定docker01的角色為manager。
#由于需要在三臺主機間復制一些配置文件,所以在docker01上配置免密登錄
[root@docker01 ~]# ssh-keygen #生成密鑰對,一路按回車即可生成
[root@docker01 ~]# tail -3 /etc/hosts #配置/etc/hosts文件
#三臺主機之間要互相解析(Swarm群集也需要此配置)
192.168.20.6 docker01
192.168.20.7 docker02
192.168.20.8 docker03
[root@docker01 ~]# ssh-copy-id docker02 #將生成的秘鑰發送到docker02
root@docker02 s password: #要輸入docker02的root密碼
[root@docker01 ~]# ssh-copy-id docker03 #將秘鑰發送到docker03,同樣需要輸入docker03的root密碼
[root@docker01 ~]# scp /etc/hosts docker02:/etc/ #將hosts文件發送到docker02
[root@docker01 ~]# scp /etc/hosts docker03:/etc/ #將hosts文件發送到docker03
[root@docker01 ~]# docker swarm init --advertise-addr 192.168.20.6 #初始化一個集群,并指定自己為manager當執行上述操作,指定自己為manager初始化一個群組后,則會隨著命令的執行成功而返回一系列的提示信息,這些提示信息給出的是,如果其他節點需要加入此節點,需要執行的命令,直接對其進行復制,然后,在需要加入此群集的主機上執行,即可成功加入群集。
返回的提示信息如下:
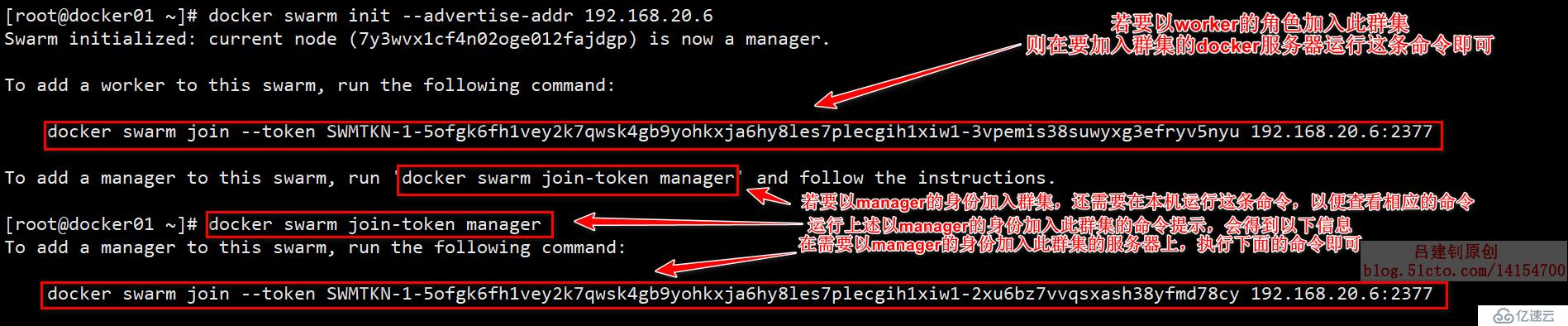
在上述中,既然給出了相應的命令,那么,現在開始配置需要加入群集的docker服務器。
#docker02執行以下命令:
[root@docker02 ~]# docker swarm join --token SWMTKN-1-5ofgk6fh2vey2k7qwsk4gb9yohkxja6hy8les7plecgih2xiw1-3vpemis38suwyxg3efryv5nyu 192.168.20.6:2377
#docker03也執行以下命令
[root@docker03 ~]# docker swarm join --token SWMTKN-1-5ofgk6fh2vey2k7qwsk4gb9yohkxja6hy8les7plecgih2xiw1-3vpemis38suwyxg3efryv5nyu 192.168.20.6:2377
[root@docker01 ~]# docker node promote docker02 #將docker02從worker升級為manager。至此,docker02及03便以worker的角色加入到了群集當中。
若docker02或者docker03要脫離這個群集,那么需要以下配置(這里以docker03為例):
#將docker03脫離這個群集
[root@docker03 ~]# docker swarm leave #在docker03上執行此命令
[root@docker01 ~]# docker node rm docker03 #然后在manager角色的服務器上移除docker03
[root@docker01 ~]# docker swarm leave -f #若是最后一個manager上進行刪除群集,則需要加“-f”選項
#最后一個刪除后,這個群集也就不存在了在docker Swarm群集中,私有倉庫并不影響其群集的正常運行,只是公司的生產環境多數都是自己的私有倉庫,所以這里模擬一下。
[root@docker01 ~]# docker run -d --name registry --restart always -p 5000:5000 registry #運行一個registry倉庫容器
[root@docker01 ~]# vim /usr/lib/systemd/system/docker.service #修改docker配置文件,以便指定私有倉庫
ExecStart=/usr/bin/dockerd -H unix:// --insecure-registry 192.168.20.6:5000 #定位到改行,指定私有倉庫IP及端口
#編輯完成后,保存退出即可
[root@docker01 ~]# systemctl daemon-reload #重新加載配置文件
[root@docker01 ~]# systemctl restart docker #重啟docker服務
#docker02及docker03也需要指定私有倉庫的位置,所以執行下面的命令將更改后的docker配置文件復制過去
[root@docker01 ~]# scp /usr/lib/systemd/system/docker.service docker02:/usr/lib/systemd/system/
[root@docker01 ~]# scp /usr/lib/systemd/system/docker.service docker03:/usr/lib/systemd/system/
#將docker的配置文件復制過去以后,需要重啟docker02及03的docker服務
#下面的命令需要在docker02及03的服務器上分別運行一次:
[root@docker02 ~]# systemctl daemon-reload
[root@docker02 ~]# systemctl restart docker在私有倉庫完成后,最好測試一下是否可以正常使用,如下:
#docker01將httpd鏡像上傳到私有倉庫
[root@docker01 ~]# docker tag httpd:latest 192.168.20.6:5000/lvjianzhao:latest
[root@docker01 ~]# docker push 192.168.20.6:5000/lvjianzhao:latest
#在dokcer02上進行下載,測試是否可以正常下載
[root@docker02 ~]# docker pull 192.168.20.6:5000/lvjianzhao:latest
#可以正常下載,說明私有倉庫可用在上面搭建私有倉庫的過程,并沒有實現數據的持久化,若需要基于數據持久化搭建私有倉庫,可以參考博文:Docker之Registry私有倉庫+Harbor私有倉庫的搭建。
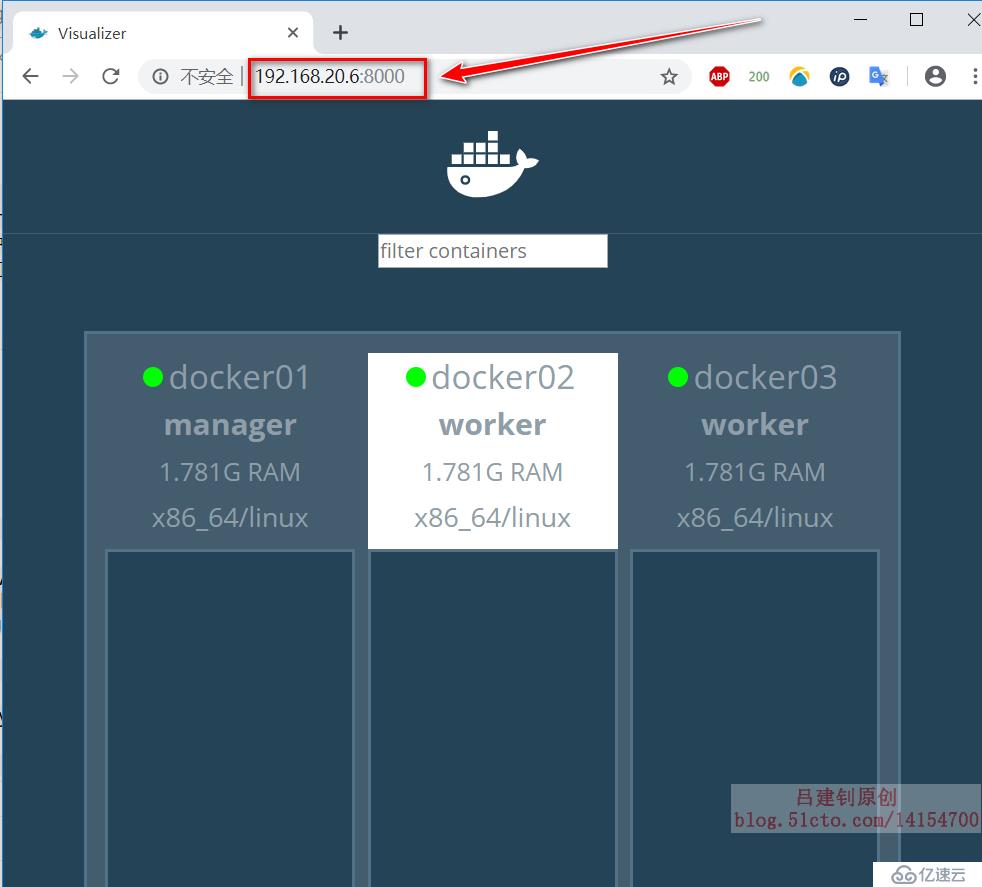
[root@docker01 ~]# docker run -d -p 8000:8080 -e HOST=172.16.20.6 -e PORT=8080 -v /var/run/docker.sock:/var/run/docker.sock --name visualizer dockersamples/visualizer
#執行上述命令后,即可客戶端訪問其8000訪問,可以看到群集內的節點信息
#若節點發生故障,則會立即檢測到訪問docker01的8000端口,即可看到以下界面(該界面只能看,不能進行任何配置):
配置至此,docker Swarm的群集基本完善了,接下來,開始展示該群集,究竟可以做些什么?也就是到了配置其service服務階段。
1、在docker01(必須在manager角色的主機)上,發布一個任務,使用剛剛測試時上傳的httpd鏡像,運行六個容器,命令如下:
[root@docker01 ~]# docker service create --replicas 6 --name lvjianzhao -p 80 192.168.20.6:5000/lvjianzhao:latest
#上述命令中,“--replicas”選項就是用來指定要運行的容器數量當運行六個容器副本后,可以查看群集的web UI界面,顯示如下:
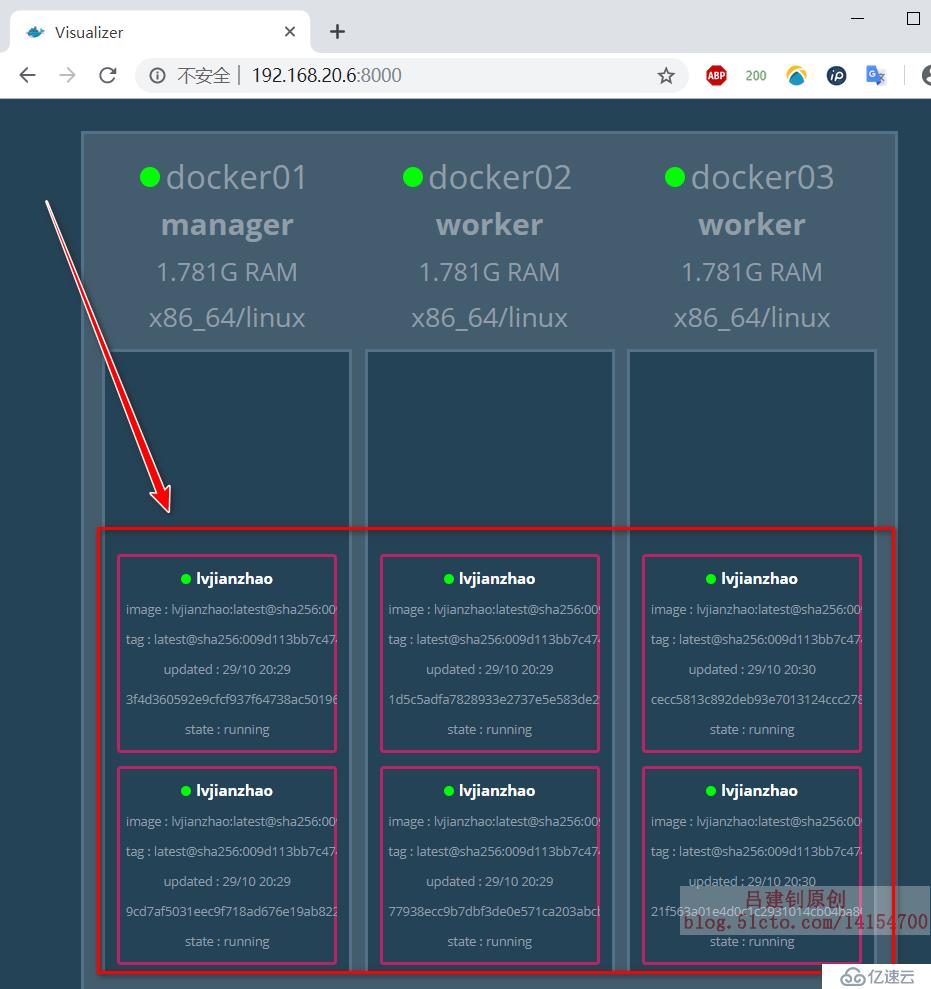
注意:docker03并沒有下載相應的鏡像,但是也會運行httpd服務,那么就可以得出一個結論:若docker主機沒有指定的鏡像,那么它將會自動去下載相應的鏡像。
可以看到,在進行上述配置后,群集中的三臺服務器基于httpd鏡像運行了兩個容器。共六個:
[root@docker01 ~]# docker service ls #查看service的狀態
ID NAME MODE REPLICAS IMAGE PORTS
13zjbf5s02f8 lvjianzhao replicated 6/6 192.168.20.6:5000/lvjianzhao:latest *:30000->80/tcp何為擴容?何為縮容?無非就是在容器無法承擔當前負載壓力的情況下,擴增幾個一樣的容器,縮容呢?也就是在大量容器資源閑置的情況下,減少幾個一樣的容器而已。
1)容器的擴容:
[root@docker01 ~]# docker service scale lvjianzhao=9 #將運行的httpd容器擴容到9個擴容后,其web UI界面顯示如下:
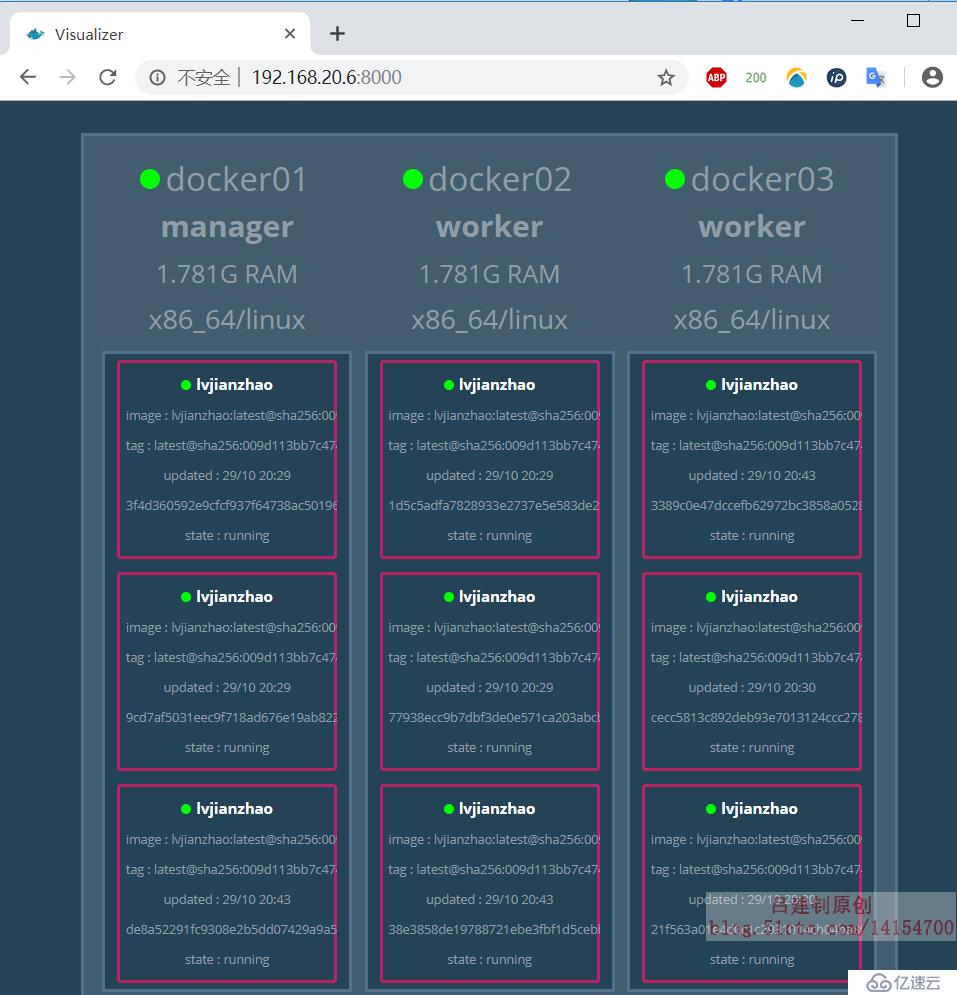
2)容器的縮容
[root@docker01 ~]# docker service scale lvjianzhao=3
將9個httpd服務的容器縮減到3個縮容后,其UI界面顯示如下: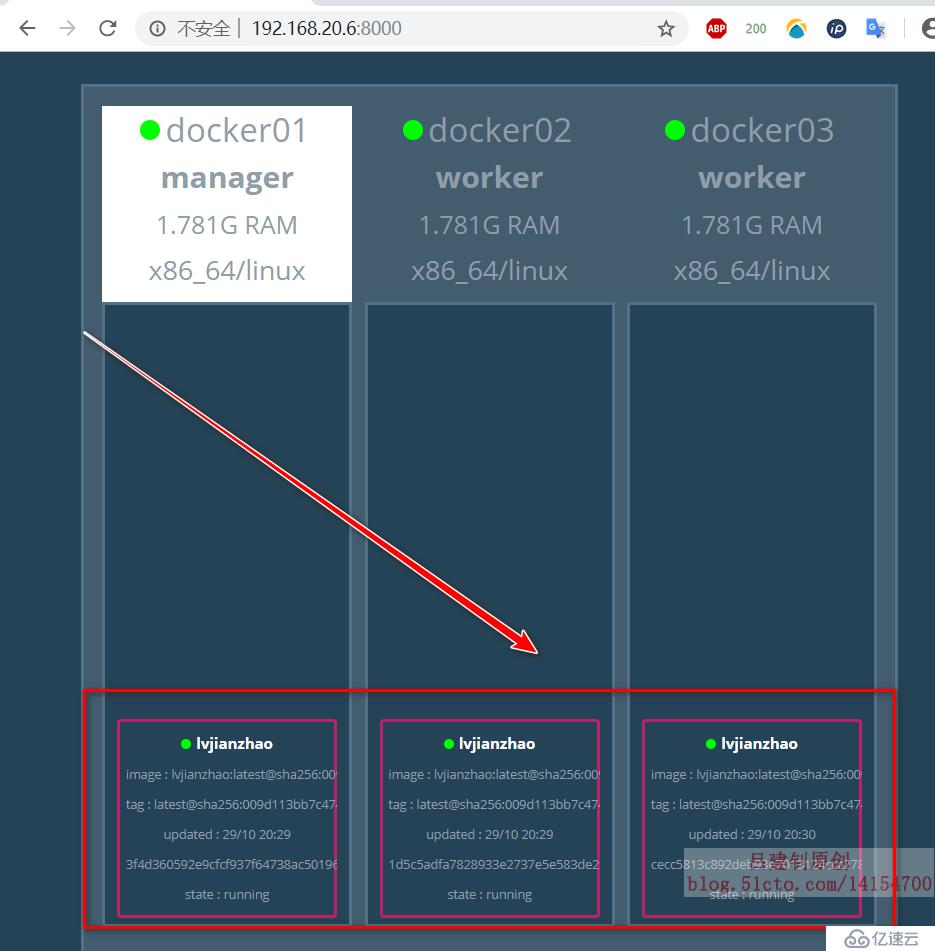
在上述的配置中,若運行指定數量的容器,那么將是群集中的所有docker主機進行輪詢的方式運行,直到運行夠指定的容器數量,那么,如果不想讓docker01這個manager角色運行容器呢?(公司領導也不會去一線搬磚的嘛),可以進行以下配置:
[root@docker01 ~]# docker node update --availability drain docker01
#設置主機docker01以后不運行容器,但已經運行的容器并不會停止
# “--availability”選項后面共有三個選項可配置,如下:
# “active”:工作;“pause”:暫時不工作;“drain”:永久性的不工作[root@docker01 ~]# docker node ls #查看群集的信息(只可以在manager角色的主機上查看)
[root@docker01 ~]# docker swarm join-token worker #如果后期需要加入worker端,可以執行此命令查看令牌(也就是加入時需要執行的命令)
[root@docker01 ~]# docker swarm join-token manager #同上,若要加入manager端,則可以執行這條命令查看令牌。
[root@docker01 ~]# docker service scale web05=6 #容器的動態擴容及縮容
[root@docker01 ~]# docker service ps web01 #查看創建的容器運行在哪些節點
[root@docker01 ~]# docker service ls #查看創建的服務
#將docker03脫離這個群集
[root@docker03 ~]# docker swarm leave #docker03脫離這個群集
[root@docker01 ~]# docker node rm docker03 #然后在manager角色的服務器上移除docker03
[root@docker01 ~]# docker node promote docker02 #將docker02從worker升級為manager。
#升級后docker02狀態會為Reachable
[root@docker01 ~]# docker node demote docker02 #將docker02從manager角色降級為worker
[root@docker01 ~]# docker node update --availability drain docker01
#設置主機docker01以后不運行容器,但已經運行的容器并不會停止
[root@docker01 ~]# docker node update --label-add mem=max docker03
#更改docker03主機的標簽為mem=max
[root@docker01 ~]# docker service update --replicas 8 --image 192.168.20.6:5000/lvjianzhao:v2.0 --container-label-add 'node.labels.mem==max' lvjianzhao05
#將服務升級為8個容器,并且指定在mem=max標簽的主機上運行在我對docker Swarm群集進行一定了解后,得出的結論如下:
- 參與群集的主機名一定不能沖突,并且可以互相解析對方的主機名;
- 集群內的所有節點可以都是manager角色,但是不可以都是worker角色;
- 當指定運行的鏡像時,如果群集中的節點本地沒有該鏡像,那么它將會自動下載對應的鏡像;
- 當群集正常工作時,若一個運行著容器的docker服務器發生宕機,那么,其所運行的所有容器,都將轉移到其他正常運行的節點之上,而且,就算發生宕機的服務器恢復正常運行,也不會再接管之前運行的容器;
關于docker Swarm群集的更多功能,可以閱讀博文:Docker Swarm群集配置實戰(2)
———————— 本文至此結束,感謝閱讀 ————————
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





