溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何使用Keras建立模型并訓練等一系列操作,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
由于Keras是一種建立在已有深度學習框架上的二次框架,其使用起來非常方便,其后端實現有兩種方法,theano和tensorflow。由于自己平時用tensorflow,所以選擇后端用tensorflow的Keras,代碼寫起來更加方便。
1、建立模型
Keras分為兩種不同的建模方式,
Sequential models:這種方法用于實現一些簡單的模型。你只需要向一些存在的模型中添加層就行了。
Functional API:Keras的API是非常強大的,你可以利用這些API來構造更加復雜的模型,比如多輸出模型,有向無環圖等等。
這里采用sequential models方法。
構建序列模型。
def define_model():
model = Sequential()
# setup first conv layer
model.add(Conv2D(32, (3, 3), activation="relu",
input_shape=(120, 120, 3), padding='same')) # [10, 120, 120, 32]
# setup first maxpooling layer
model.add(MaxPooling2D(pool_size=(2, 2))) # [10, 60, 60, 32]
# setup second conv layer
model.add(Conv2D(8, kernel_size=(3, 3), activation="relu",
padding='same')) # [10, 60, 60, 8]
# setup second maxpooling layer
model.add(MaxPooling2D(pool_size=(3, 3))) # [10, 20, 20, 8]
# add bianping layer, 3200 = 20 * 20 * 8
model.add(Flatten()) # [10, 3200]
# add first full connection layer
model.add(Dense(512, activation='sigmoid')) # [10, 512]
# add dropout layer
model.add(Dropout(0.5))
# add second full connection layer
model.add(Dense(4, activation='softmax')) # [10, 4]
return model可以看到定義模型時輸出的網絡結構。
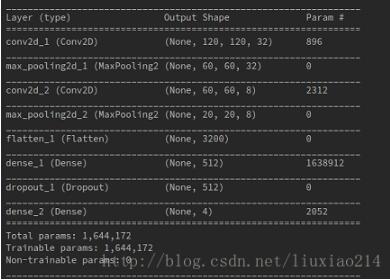
2、準備數據
def load_data(resultpath):
datapath = os.path.join(resultpath, "data10_4.npz")
if os.path.exists(datapath):
data = np.load(datapath)
X, Y = data["X"], data["Y"]
else:
X = np.array(np.arange(432000)).reshape(10, 120, 120, 3)
Y = [0, 0, 1, 1, 2, 2, 3, 3, 2, 0]
X = X.astype('float32')
Y = np_utils.to_categorical(Y, 4)
np.savez(datapath, X=X, Y=Y)
print('Saved dataset to dataset.npz.')
print('X_shape:{}\nY_shape:{}'.format(X.shape, Y.shape))
return X, Y
3、訓練模型
def train_model(resultpath):
model = define_model()
# if want to use SGD, first define sgd, then set optimizer=sgd
sgd = SGD(lr=0.001, decay=1e-6, momentum=0, nesterov=True)
# select loss\optimizer\
model.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
model.summary()
# draw the model structure
plot_model(model, show_shapes=True,
to_file=os.path.join(resultpath, 'model.png'))
# load data
X, Y = load_data(resultpath)
# split train and test data
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.2, random_state=2)
# input data to model and train
history = model.fit(X_train, Y_train, batch_size=2, epochs=10,
validation_data=(X_test, Y_test), verbose=1, shuffle=True)
# evaluate the model
loss, acc = model.evaluate(X_test, Y_test, verbose=0)
print('Test loss:', loss)
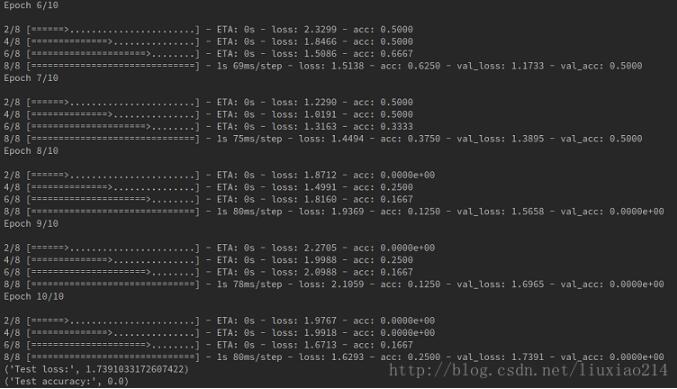
print('Test accuracy:', acc)可以看到訓練時輸出的日志。因為是隨機數據,沒有意義,這里訓練的結果不必計較,只是練習而已。
保存下來的模型結構:

4、保存與加載模型并測試
有兩種保存方式
4.1 直接保存模型h6
保存:
def my_save_model(resultpath): model = train_model(resultpath) # the first way to save model model.save(os.path.join(resultpath, 'my_model.h6'))
加載:
def my_load_model(resultpath):
# test data
X = np.array(np.arange(86400)).reshape(2, 120, 120, 3)
Y = [0, 1]
X = X.astype('float32')
Y = np_utils.to_categorical(Y, 4)
# the first way of load model
model2 = load_model(os.path.join(resultpath, 'my_model.h6'))
model2.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
test_loss, test_acc = model2.evaluate(X, Y, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
y = model2.predict_classes(X)
print("predicct is: ", y)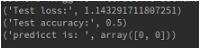
4.2 分別保存網絡結構和權重
保存:
def my_save_model(resultpath): model = train_model(resultpath) # the secon way : save trained network structure and weights model_json = model.to_json() open(os.path.join(resultpath, 'my_model_structure.json'), 'w').write(model_json) model.save_weights(os.path.join(resultpath, 'my_model_weights.hd5'))
加載:
def my_load_model(resultpath):
# test data
X = np.array(np.arange(86400)).reshape(2, 120, 120, 3)
Y = [0, 1]
X = X.astype('float32')
Y = np_utils.to_categorical(Y, 4)
# the second way : load model structure and weights
model = model_from_json(open(os.path.join(resultpath, 'my_model_structure.json')).read())
model.load_weights(os.path.join(resultpath, 'my_model_weights.hd5'))
model.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
test_loss, test_acc = model.evaluate(X, Y, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
y = model.predict_classes(X)
print("predicct is: ", y)
可以看到,兩次的結果是一樣的。
5、完整代碼
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from keras.losses import categorical_crossentropy
from keras.optimizers import Adam
from keras.utils.vis_utils import plot_model
from keras.optimizers import SGD
from keras.models import model_from_json
from keras.models import load_model
from keras.utils import np_utils
import numpy as np
import os
from sklearn.model_selection import train_test_split
def load_data(resultpath):
datapath = os.path.join(resultpath, "data10_4.npz")
if os.path.exists(datapath):
data = np.load(datapath)
X, Y = data["X"], data["Y"]
else:
X = np.array(np.arange(432000)).reshape(10, 120, 120, 3)
Y = [0, 0, 1, 1, 2, 2, 3, 3, 2, 0]
X = X.astype('float32')
Y = np_utils.to_categorical(Y, 4)
np.savez(datapath, X=X, Y=Y)
print('Saved dataset to dataset.npz.')
print('X_shape:{}\nY_shape:{}'.format(X.shape, Y.shape))
return X, Y
def define_model():
model = Sequential()
# setup first conv layer
model.add(Conv2D(32, (3, 3), activation="relu",
input_shape=(120, 120, 3), padding='same')) # [10, 120, 120, 32]
# setup first maxpooling layer
model.add(MaxPooling2D(pool_size=(2, 2))) # [10, 60, 60, 32]
# setup second conv layer
model.add(Conv2D(8, kernel_size=(3, 3), activation="relu",
padding='same')) # [10, 60, 60, 8]
# setup second maxpooling layer
model.add(MaxPooling2D(pool_size=(3, 3))) # [10, 20, 20, 8]
# add bianping layer, 3200 = 20 * 20 * 8
model.add(Flatten()) # [10, 3200]
# add first full connection layer
model.add(Dense(512, activation='sigmoid')) # [10, 512]
# add dropout layer
model.add(Dropout(0.5))
# add second full connection layer
model.add(Dense(4, activation='softmax')) # [10, 4]
return model
def train_model(resultpath):
model = define_model()
# if want to use SGD, first define sgd, then set optimizer=sgd
sgd = SGD(lr=0.001, decay=1e-6, momentum=0, nesterov=True)
# select loss\optimizer\
model.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
model.summary()
# draw the model structure
plot_model(model, show_shapes=True,
to_file=os.path.join(resultpath, 'model.png'))
# load data
X, Y = load_data(resultpath)
# split train and test data
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.2, random_state=2)
# input data to model and train
history = model.fit(X_train, Y_train, batch_size=2, epochs=10,
validation_data=(X_test, Y_test), verbose=1, shuffle=True)
# evaluate the model
loss, acc = model.evaluate(X_test, Y_test, verbose=0)
print('Test loss:', loss)
print('Test accuracy:', acc)
return model
def my_save_model(resultpath):
model = train_model(resultpath)
# the first way to save model
model.save(os.path.join(resultpath, 'my_model.h6'))
# the secon way : save trained network structure and weights
model_json = model.to_json()
open(os.path.join(resultpath, 'my_model_structure.json'), 'w').write(model_json)
model.save_weights(os.path.join(resultpath, 'my_model_weights.hd5'))
def my_load_model(resultpath):
# test data
X = np.array(np.arange(86400)).reshape(2, 120, 120, 3)
Y = [0, 1]
X = X.astype('float32')
Y = np_utils.to_categorical(Y, 4)
# the first way of load model
model2 = load_model(os.path.join(resultpath, 'my_model.h6'))
model2.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
test_loss, test_acc = model2.evaluate(X, Y, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
y = model2.predict_classes(X)
print("predicct is: ", y)
# the second way : load model structure and weights
model = model_from_json(open(os.path.join(resultpath, 'my_model_structure.json')).read())
model.load_weights(os.path.join(resultpath, 'my_model_weights.hd5'))
model.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
test_loss, test_acc = model.evaluate(X, Y, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
y = model.predict_classes(X)
print("predicct is: ", y)
def main():
resultpath = "result"
#train_model(resultpath)
#my_save_model(resultpath)
my_load_model(resultpath)
if __name__ == "__main__":
main()關于如何使用Keras建立模型并訓練等一系列操作就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





