溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python3爬蟲中Redis數據庫的基本操作有哪些,具有一定借鑒價值,需要的朋友可以參考下。希望大家閱讀完這篇文章后大有收獲。下面讓小編帶著大家一起了解一下。
Redis是一個基于內存的高效的鍵值型非關系型數據庫,存取效率極高,而且支持多種存儲數據結構,使用也非常簡單。
1. 準備工作
在開始之前,請確保已經安裝好了Redis及RedisPy庫。如果要做數據導入/導出操作的話,還需要安裝RedisDump。如果沒有安裝,可以參考第1章。
2. Redis和StrictRedis
RedisPy庫提供兩個類Redis和StrictRedis來實現Redis的命令操作。
StrictRedis實現了絕大部分官方的命令,參數也一一對應,比如set()方法就對應Redis命令的set方法。而Redis是StrictRedis的子類,它的主要功能是用于向后兼容舊版本庫里的幾個方法。為了做兼容,它將方法做了改寫,比如lrem()方法就將value和num參數的位置互換,這和Redis命令行的命令參數不一致。
官方推薦使用StrictRedis,所以本節中我們也用StrictRedis類的相關方法作演示。
3. 連接Redis
現在我們已經在本地安裝了Redis并運行在6379端口,密碼設置為foobared。那么,可以用如下示例連接Redis并測試:
from redis import StrictRedis
redis = StrictRedis(host='localhost', port=6379, db=0, password='foobared')
redis.set('name', 'Bob')
print(redis.get('name'))這里我們傳入了Redis的地址、運行端口、使用的數據庫和密碼信息。在默認不傳的情況下,這4個參數分別為localhost、6379、0和None。首先聲明了一個StrictRedis對象,接下來調用set()方法,設置一個鍵值對,然后將其獲取并打印。
運行結果如下:
b'Bob'
這說明我們連接成功,并可以執行set()和get()操作了。
當然,我們還可以使用ConnectionPool來連接,示例如下:
from redis import StrictRedis, ConnectionPool pool = ConnectionPool(host='localhost', port=6379, db=0, password='foobared') redis = StrictRedis(connection_pool=pool)
這樣的連接效果是一樣的。觀察源碼可以發現,StrictRedis內其實就是用host和port等參數又構造了一個ConnectionPool,所以直接將ConnectionPool當作參數傳給StrictRedis也一樣。
另外,ConnectionPool還支持通過URL來構建。URL的格式支持有如下3種:
redis://[:password]@host:port/db rediss://[:password]@host:port/db unix://[:password]@/path/to/socket.sock?db=db
這3種URL分別表示創建Redis TCP連接、Redis TCP+SSL連接、Redis UNIX socket連接。我們只需要構造上面任意一種URL即可,其中password部分如果有則可以寫,沒有則可以省略。下面再用URL連接演示一下:
url = 'redis://:foobared@localhost:6379/0' pool = ConnectionPool.from_url(url) redis = StrictRedis(connection_pool=pool)
這里我們使用第一種連接字符串進行連接。首先,聲明一個Redis連接字符串,然后調用from_url()方法創建ConnectionPool,接著將其傳給StrictRedis即可完成連接,所以使用URL的連接方式還是比較方便的。
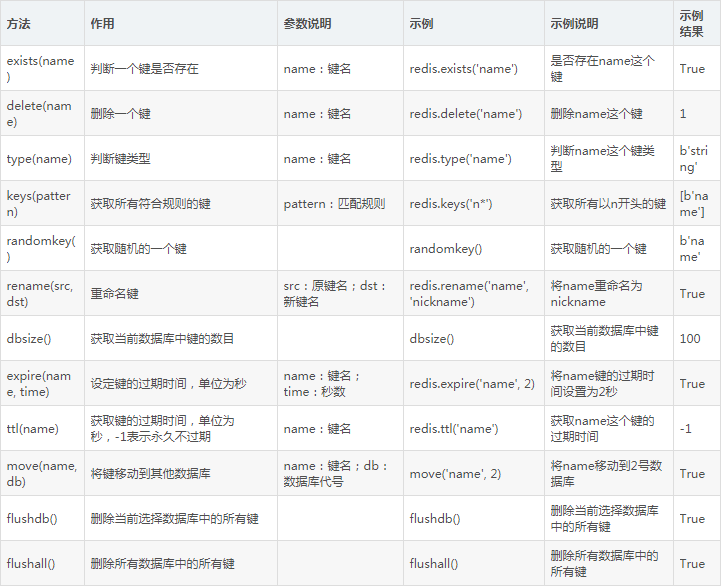
4. 鍵操作
表5-5總結了鍵的一些判斷和操作方法。
表5-5 鍵的一些判斷和操作方法
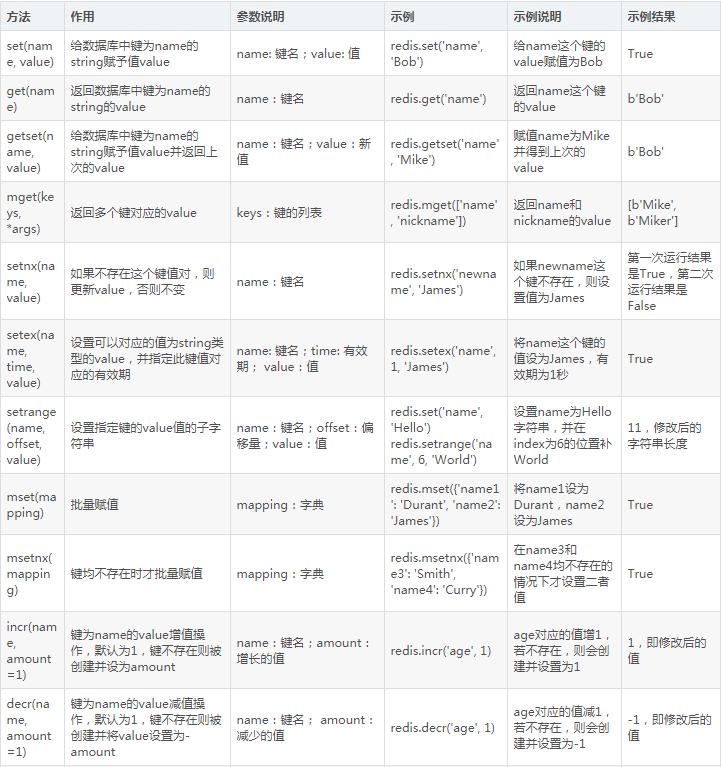
5. 字符串操作
Redis支持最基本的鍵值對形式存儲,用法總結如表5-6所示。
表5-6 鍵值對形式存儲

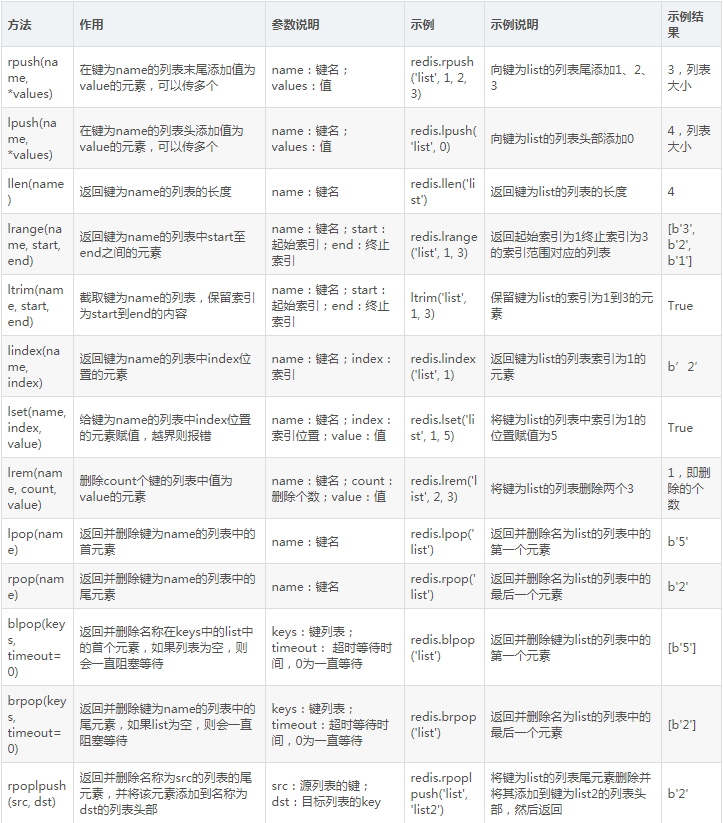
6. 列表操作
Redis還提供了列表存儲,列表內的元素可以重復,而且可以從兩端存儲,用法如表5-7所示。
表5-7 列表操作
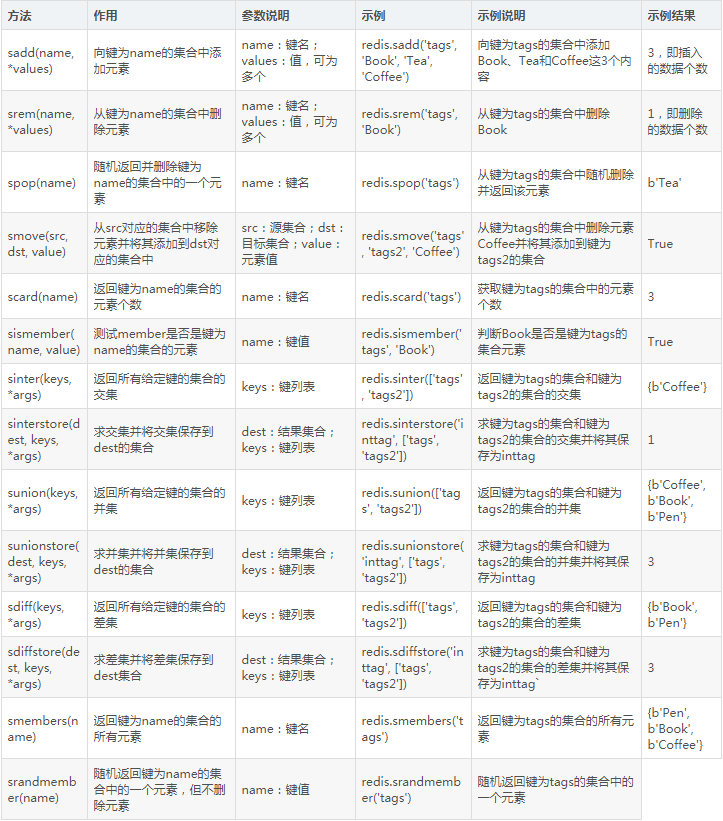
7. 集合操作
Redis還提供了集合存儲,集合中的元素都是不重復的,用法如表5-8所示。
表5-8 集合操作
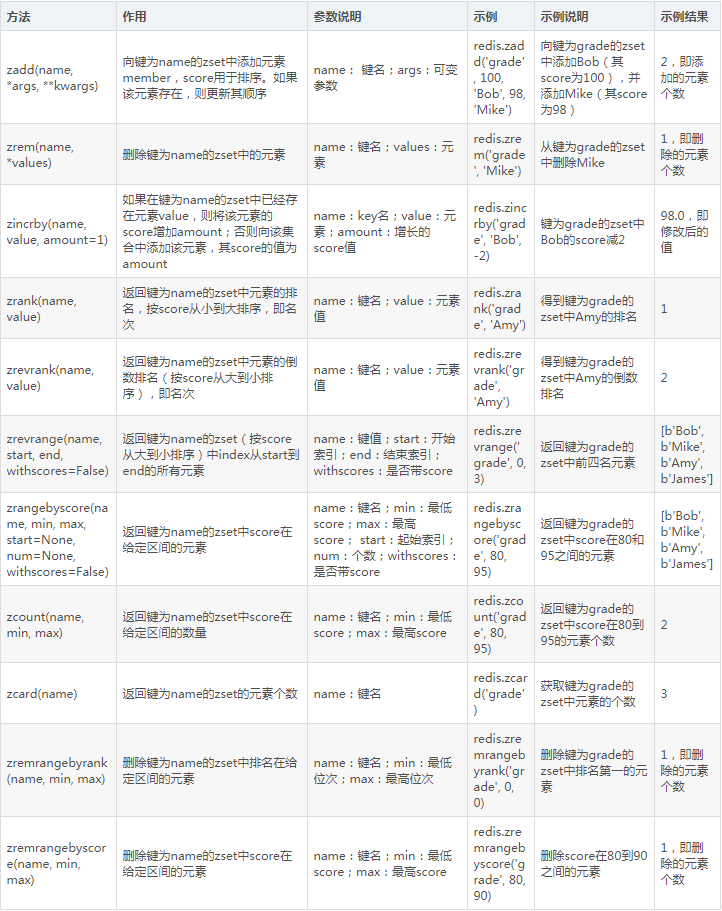
8. 有序集合操作
有序集合比集合多了一個分數字段,利用它可以對集合中的數據進行排序,其用法總結如表5-9所示。
表5-9 有序集合操作
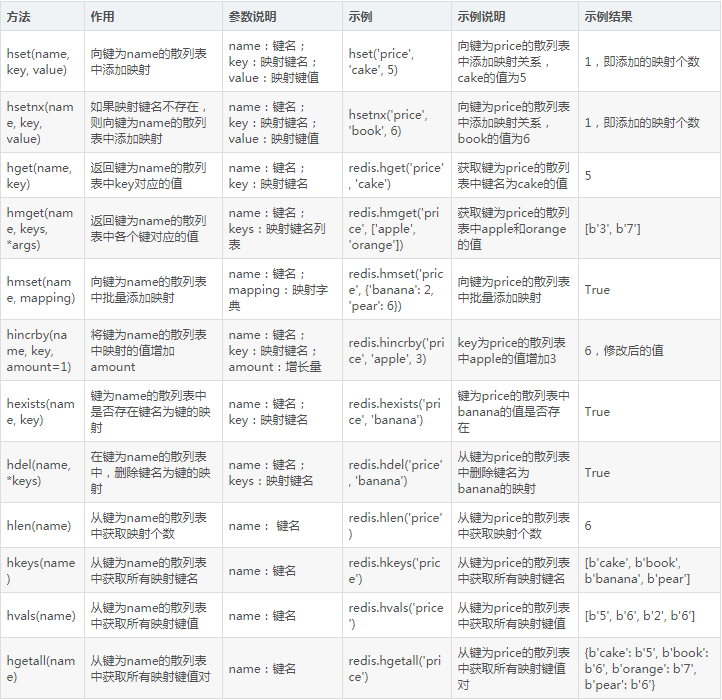
9. 散列操作
Redis還提供了散列表的數據結構,我們可以用name指定一個散列表的名稱,表內存儲了各個鍵值對,用法總結如表5-10所示。
表5-10 散列操作
10. RedisDump
RedisDump提供了強大的Redis數據的導入和導出功能,現在就來看下它的具體用法。
首先,確保已經安裝好了RedisDump。
RedisDump提供了兩個可執行命令:redis-dump用于導出數據,redis-load用于導入數據。
redis-dump
首先,可以輸入如下命令查看所有可選項:
redis-dump -h
運行結果如下:
Usage: redis-dump [global options] COMMAND [command options] -u, --uri=S Redis URI (e.g. redis://hostname[:port]) -d, --database=S Redis database (e.g. -d 15) -s, --sleep=S Sleep for S seconds after dumping (for debugging) -c, --count=S Chunk size (default: 10000) -f, --filter=S Filter selected keys (passed directly to redis' KEYS command) -O, --without_optimizations Disable run time optimizations -V, --version Display version -D, --debug --nosafe
其中-u代表Redis連接字符串,-d代表數據庫代號,-s代表導出之后的休眠時間,-c代表分塊大小,默認是10000,-f代表導出時的過濾器,-O代表禁用運行時優化,-V用于顯示版本,-D表示開啟調試。
我們拿本地的Redis做測試,運行在6379端口上,密碼為foobared,導出命令如下:
redis-dump -u :foobared@localhost:6379
如果沒有密碼的話,可以不加密碼前綴,命令如下:
redis-dump -u localhost:6379
運行之后,可以將本地0至15號數據庫的所有數據輸出出來,例如:
{"db":0,"key":"name","ttl":-1,"type":"string","value":"James","size":5}
{"db":0,"key":"name2","ttl":-1,"type":"string","value":"Durant","size":6}
{"db":0,"key":"name3","ttl":-1,"type":"string","value":"Durant","size":6}
{"db":0,"key":"name4","ttl":-1,"type":"string","value":"HelloWorld","size":10}
{"db":0,"key":"name5","ttl":-1,"type":"string","value":"James","size":5}
{"db":0,"key":"name6","ttl":-1,"type":"string","value":"James","size":5}
{"db":0,"key":"age","ttl":-1,"type":"string","value":"1","size":1}
{"db":0,"key":"age2","ttl":-1,"type":"string","value":"-5","size":2}每條數據都包含6個字段,其中db即數據庫代號,key即鍵名,ttl即該鍵值對的有效時間,type即鍵值類型,value即內容,size即占用空間。
如果想要將其輸出為JSON行文件,可以使用如下命令:
redis-dump -u :foobared@localhost:6379 > ./redis_data.jl
這樣就可以成功將Redis的所有數據庫的所有數據導出成JSON行文件了。
另外,可以使用-d參數指定某個數據庫的導出,例如只導出1號數據庫的內容:
redis-dump -u :foobared@localhost:6379 -d 1 > ./redis.data.jl
如果只想導出特定的內容,比如想導出以adsl開頭的數據,可以加入-f參數用來過濾,命令如下:
redis-dump -u :foobared@localhost:6379 -f adsl:* > ./redis.data.jl
其中-f參數即Redis的keys命令的參數,可以寫一些過濾規則。
redis-load
同樣,我們可以首先輸入如下命令查看所有可選項:
redis-load -h
運行結果如下:
redis-load --help Try: redis-load [global options] COMMAND [command options] -u, --uri=S Redis URI (e.g. redis://hostname[:port]) -d, --database=S Redis database (e.g. -d 15) -s, --sleep=S Sleep for S seconds after dumping (for debugging) -n, --no_check_utf8 -V, --version Display version -D, --debug --nosafe
其中-u代表Redis連接字符串,-d代表數據庫代號,默認是全部,-s代表導出之后的休眠時間,-n代表不檢測UTF-8編碼,-V表示顯示版本,-D表示開啟調試。
我們可以將JSON行文件導入到Redis數據庫中:
< redis_data.json redis-load -u :foobared@localhost:6379
這樣就可以成功將JSON行文件導入到數據庫中了。
另外,下面的命令同樣可以達到同樣的效果:
cat redis_data.json | redis-load -u :foobared@localhost:6379
感謝你能夠認真閱讀完這篇文章,希望小編分享Python3爬蟲中Redis數據庫的基本操作有哪些內容對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,遇到問題就找億速云,詳細的解決方法等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





