溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python3爬蟲中Splash有什么用,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
Splash是一個JavaScript渲染服務,是一個帶有HTTP API的輕量級瀏覽器,同時它對接了Python中的Twisted和QT庫。利用它,我們同樣可以實現動態渲染頁面的抓取。
1. 功能介紹
·利用Splash,我們可以實現如下功能:
·異步方式處理多個網頁渲染過程;
·獲取渲染后的頁面的源代碼或截圖;
·通過關閉圖片渲染或者使用Adblock規則來加快頁面渲染速度;
·可執行特定的JavaScript腳本;
·可通過Lua腳本來控制頁面渲染過程;
·獲取渲染的詳細過程并通過HAR(HTTP Archive)格式呈現。
接下來,我們來了解一下它的具體用法。
2. 準備工作
在開始之前,請確保已經正確安裝好了Splash并可以正常運行服務。如果沒有安裝,可以參考第1章。
3. 實例引入
首先,通過Splash提供的Web頁面來測試其渲染過程。例如,我們在本機8050端口上運行了Splash服務,打開http://localhost:8050/即可看到其Web頁面,如圖7-6所示。
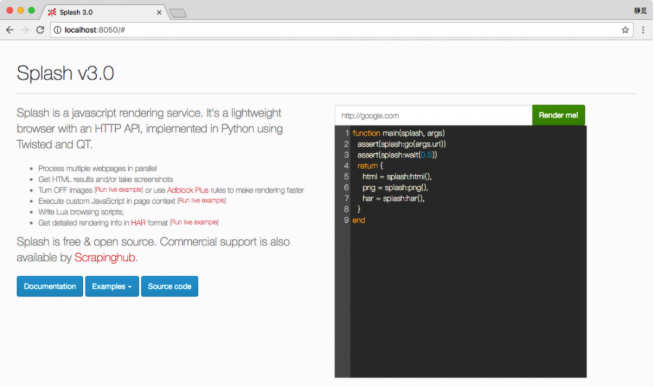
圖7-6 Web頁面
在圖7-6右側,呈現的是一個渲染示例。可以看到,上方有一個輸入框,默認是http://google.com,這里換成百度測試一下,將內容更改為https://www.baidu.com,然后點擊Render me按鈕開始渲染,結果如圖7-7所示。
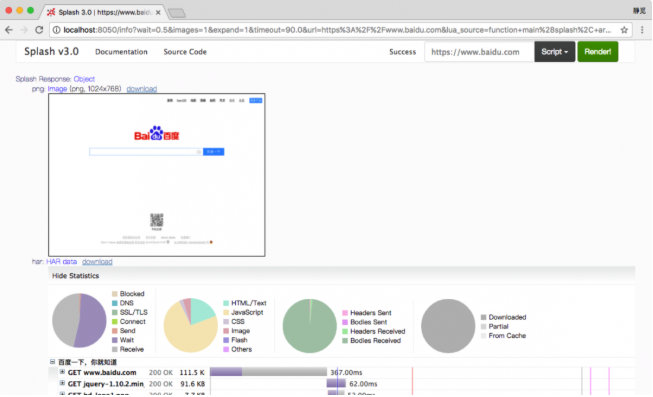
圖7-7 運行結果
可以看到,網頁的返回結果呈現了渲染截圖、HAR加載統計數據、網頁的源代碼。
通過HAR的結果可以看到,Splash執行了整個網頁的渲染過程,包括CSS、JavaScript的加載等過程,呈現的頁面和我們在瀏覽器中得到的結果完全一致。
那么,這個過程由什么來控制呢?重新返回首頁,可以看到實際上是有一段腳本,內容如下:
function main(splash, args)
assert(splash:go(args.url))
assert(splash:wait(0.5))
return {
html = splash:html(),
png = splash:png(),
har = splash:har(),
}
end這個腳本實際上是用Lua語言寫的腳本。即使不懂這個語言的語法,但從腳本的表面意思,我們也可以大致了解到它首先調用go()方法去加載頁面,然后調用wait()方法等待了一定時間,最后返回了頁面的源碼、截圖和HAR信息。
到這里,我們大體了解了Splash是通過Lua腳本來控制了頁面的加載過程的,加載過程完全模擬瀏覽器,最后可返回各種格式的結果,如網頁源碼和截圖等。
接下來,我們就來了解Lua腳本的寫法以及相關API的用法。
4. Splash Lua腳本
Splash可以通過Lua腳本執行一系列渲染操作,這樣我們就可以用Splash來模擬類似Chrome、PhantomJS的操作了。
首先,我們來了解一下Splash Lua腳本的入口和執行方式。
入口及返回值
首先,來看一個基本實例:
function main(splash, args)
splash:go("http://www.baidu.com")
splash:wait(0.5)
local title = splash:evaljs("document.title")
return {title=title}
end我們將代碼粘貼到剛才打開的http://localhost:8050/的代碼編輯區域,然后點擊Render me!按鈕來測試一下。
我們看到它返回了網頁的標題,如圖7-8所示。這里我們通過evaljs()方法傳入JavaScript腳本,而document.title的執行結果就是返回網頁標題,執行完畢后將其賦值給一個title變量,隨后將其返回。
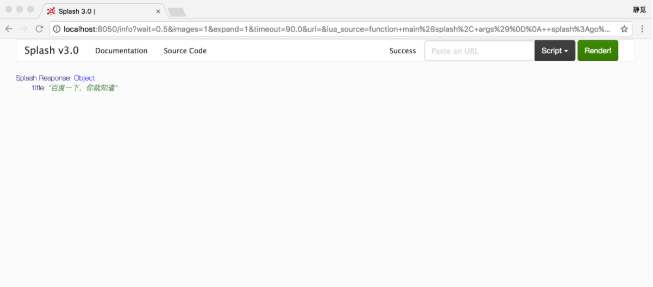
圖7-8 運行結果
注意,我們在這里定義的方法名稱叫作main()。這個名稱必須是固定的,Splash會默認調用這個方法。
該方法的返回值既可以是字典形式,也可以是字符串形式,最后都會轉化為Splash HTTP Response,例如:
function main(splash)
return {hello="world!"}
end返回了一個字典形式的內容。例如:
function main(splash) return 'hello' end
返回了一個字符串形式的內容。
異步處理
Splash支持異步處理,但是這里并沒有顯式指明回調方法,其回調的跳轉是在Splash內部完成的。示例如下:
function main(splash, args)
local example_urls = {"www.baidu.com", "www.taobao.com", "www.zhihu.com"}
local urls = args.urls or example_urls
local results = {}
for index, url in ipairs(urls) do
local ok, reason = splash:go("http://" .. url)
if ok then
splash:wait(2)
results[url] = splash:png()
end
end
return results
end運行結果是3個站點的截圖,如圖7-9所示。
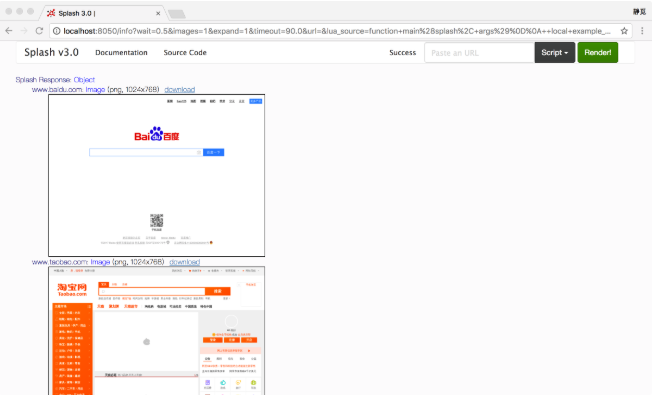
圖7-9 運行結果
在腳本內調用的wait()方法類似于Python中的sleep(),其參數為等待的秒數。當Splash執行到此方法時,它會轉而去處理其他任務,然后在指定的時間過后再回來繼續處理。
這里值得注意的是,Lua腳本中的字符串拼接和Python不同,它使用的是..操作符,而不是+。如果有必要,可以簡單了解一下Lua腳本的語法,詳見http://www.runoob.com/lua/lua-basic-syntax.html。
另外,這里做了加載時的異常檢測。go()方法會返回加載頁面的結果狀態,如果頁面出現4xx或5xx狀態碼,ok變量就為空,就不會返回加載后的圖片。
5. Splash對象屬性
我們注意到,前面例子中main()方法的第一個參數是splash,這個對象非常重要,它類似于Selenium中的WebDriver對象,我們可以調用它的一些屬性和方法來控制加載過程。接下來,先看下它的屬性。
args
該屬性可以獲取加載時配置的參數,比如URL,如果為GET請求,它還可以獲取GET請求參數;如果為POST請求,它可以獲取表單提交的數據。Splash也支持使用第二個參數直接作為args,例如:
function main(splash, args) local url = args.url end
這里第二個參數args就相當于splash.args屬性,以上代碼等價于:
function main(splash) local url = splash.args.url end
js_enabled
這個屬性是Splash的JavaScript執行開關,可以將其配置為true或false來控制是否執行JavaScript代碼,默認為true。例如,這里禁止執行JavaScript代碼:
function main(splash, args)
splash:go("https://www.baidu.com")
splash.js_enabled = false
local title = splash:evaljs("document.title")
return {title=title}
end接著我們重新調用了evaljs()方法執行JavaScript代碼,此時運行結果就會拋出異常:
{
"error": 400,
"type": "ScriptError",
"info": {
"type": "JS_ERROR",
"js_error_message": null,
"source": "[string \"function main(splash, args)\r...\"]",
"message": "[string \"function main(splash, args)\r...\"]:4: unknown JS error: None",
"line_number": 4,
"error": "unknown JS error: None",
"splash_method": "evaljs"
},
"description": "Error happened while executing Lua script"
}不過一般來說,不用設置此屬性,默認開啟即可。
resource_timeout
此屬性可以設置加載的超時時間,單位是秒。如果設置為0或nil(類似Python中的None),代表不檢測超時。示例如下:
function main(splash)
splash.resource_timeout = 0.1
assert(splash:go('https://www.taobao.com'))
return splash:png()
end例如,這里將超時時間設置為0.1秒。如果在0.1秒之內沒有得到響應,就會拋出異常,錯誤如下:
{
"error": 400,
"type": "ScriptError",
"info": {
"error": "network5",
"type": "LUA_ERROR",
"line_number": 3,
"source": "[string \"function main(splash)\r...\"]",
"message": "Lua error: [string \"function main(splash)\r...\"]:3: network5"
},
"description": "Error happened while executing Lua script"
}此屬性適合在網頁加載速度較慢的情況下設置。如果超過了某個時間無響應,則直接拋出異常并忽略即可。
images_enabled
此屬性可以設置圖片是否加載,默認情況下是加載的。禁用該屬性后,可以節省網絡流量并提高網頁加載速度。但是需要注意的是,禁用圖片加載可能會影響JavaScript渲染。因為禁用圖片之后,它的外層DOM節點的高度會受影響,進而影響DOM節點的位置。因此,如果JavaScript對圖片節點有操作的話,其執行就會受到影響。
另外值得注意的是,Splash使用了緩存。如果一開始加載出來了網頁圖片,然后禁用了圖片加載,再重新加載頁面,之前加載好的圖片可能還會顯示出來,這時直接重啟Splash即可。
禁用圖片加載的示例如下:
function main(splash, args)
splash.images_enabled = false
assert(splash:go('https://www.jd.com'))
return {png=splash:png()}
end這樣返回的頁面截圖就不會帶有任何圖片,加載速度也會快很多。
plugins_enabled
此屬性可以控制瀏覽器插件(如Flash插件)是否開啟。默認情況下,此屬性是false,表示不開啟。可以使用如下代碼控制其開啟和關閉:
splash.plugins_enabled = true/false
scroll_position
通過設置此屬性,我們可以控制頁面上下或左右滾動。這是一個比較常用的屬性,示例如下:
function main(splash, args)
assert(splash:go('https://www.taobao.com'))
splash.scroll_position = {y=400}
return {png=splash:png()}
end這樣我們就可以控制頁面向下滾動400像素值,結果如圖7-10所示。
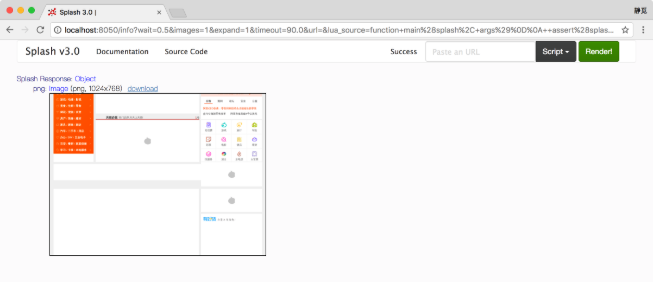
圖7-10 運行結果
如果要讓頁面左右滾動,可以傳入x參數,代碼如下:
splash.scroll_position = {x=100, y=200}6. Splash對象的方法
除了前面介紹的屬性外,Splash對象還有如下方法。
go()
該方法用來請求某個鏈接,而且它可以模擬GET和POST請求,同時支持傳入請求頭、表單等數據,其用法如下:
ok, reason = splash:go{url, baseurl=nil, headers=nil, http_method="GET", body=nil, formdata=nil}其參數說明如下。
url:請求的URL。
baseurl:可選參數,默認為空,表示資源加載相對路徑。
headers:可選參數,默認為空,表示請求頭。
http_method:可選參數,默認為GET,同時支持POST。
body:可選參數,默認為空,發POST請求時的表單數據,使用的Content-type為application/json。
formdata:可選參數,默認為空,POST的時候的表單數據,使用的Content-type為application/x-www-form-urlencoded。
該方法的返回結果是結果ok和原因reason的組合,如果ok為空,代表網頁加載出現了錯誤,此時reason變量中包含了錯誤的原因,否則證明頁面加載成功。示例如下:
function main(splash, args)
local ok, reason = splash:go{"http://httpbin.org/post", http_method="POST", body="name=Germey"}
if ok then
return splash:html()
end
end這里我們模擬了一個POST請求,并傳入了POST的表單數據,如果成功,則返回頁面的源代碼。
運行結果如下:
<html><head></head><body><pre >{
"args": {},
"data": "",
"files": {},
"form": {
"name": "Germey"
},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"Origin": "null",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0
Safari/602.1"
},
"json": null,
"origin": "60.207.237.85",
"url": "http://httpbin.org/post"
}
</pre></body></html>可以看到,我們成功實現了POST請求并發送了表單數據。
wait()
此方法可以控制頁面的等待時間,使用方法如下:
ok, reason = splash:wait{time, cancel_on_redirect=false, cancel_on_error=true}參數說明如下。
time:等待的秒數。
cancel_on_redirect:可選參數,默認為false,表示如果發生了重定向就停止等待,并返回重定向結果。
cancel_on_error:可選參數,默認為false,表示如果發生了加載錯誤,就停止等待。
返回結果同樣是結果ok和原因reason的組合。
我們用一個實例感受一下:
function main(splash)
splash:go("https://www.taobao.com")
splash:wait(2)
return {html=splash:html()}
end這可以實現訪問淘寶并等待2秒,隨后返回頁面源代碼的功能。
jsfunc()
此方法可以直接調用JavaScript定義的方法,但是所調用的方法需要用雙中括號包圍,這相當于實現了JavaScript方法到Lua腳本的轉換。示例如下:
function main(splash, args)
local get_div_count = splash:jsfunc([[
function () {
var body = document.body;
var divs = body.getElementsByTagName('div');
return divs.length;
}
]])
splash:go("https://www.baidu.com")
return ("There are %s DIVs"):format(
get_div_count())
end運行結果如下:
There are 21 DIVs
首先,我們聲明了一個JavaScript定義的方法,然后在頁面加載成功后調用了此方法計算出了頁面中div節點的個數。
關于JavaScript到Lua腳本的更多轉換細節,可以參考官方文檔:https://splash.readthedocs.io/en/stable/scripting-ref.html#splash-jsfunc。
evaljs()
此方法可以執行JavaScript代碼并返回最后一條JavaScript語句的返回結果,使用方法如下:
result = splash:evaljs(js)
比如,可以用下面的代碼來獲取頁面標題:
local title = splash:evaljs("document.title")runjs()
此方法可以執行JavaScript代碼,它與evaljs()的功能類似,但是更偏向于執行某些動作或聲明某些方法。例如:
function main(splash, args)
splash:go("https://www.baidu.com")
splash:runjs("foo = function() { return 'bar' }")
local result = splash:evaljs("foo()")
return result
end這里我們用runjs()先聲明了一個JavaScript定義的方法,然后通過evaljs()來調用得到的結果。
運行結果如下:
bar
autoload()
此方法可以設置每個頁面訪問時自動加載的對象,使用方法如下:
ok, reason = splash:autoload{source_or_url, source=nil, url=nil}參數說明如下。
source_or_url:JavaScript代碼或者JavaScript庫鏈接。
source:JavaScript代碼。
url:JavaScript庫鏈接
但是此方法只負責加載JavaScript代碼或庫,不執行任何操作。如果要執行操作,可以調用evaljs()或runjs()方法。示例如下:
function main(splash, args)
splash:autoload([[
function get_document_title(){
return document.title;
}
]])
splash:go("https://www.baidu.com")
return splash:evaljs("get_document_title()")
end這里我們調用autoload()方法聲明了一個JavaScript方法,然后通過evaljs()方法來執行此JavaScript方法。
運行結果如下:
百度一下,你就知道
另外,我們也可以使用autoload()方法加載某些方法庫,如jQuery,示例如下:
function main(splash, args)
assert(splash:autoload("https://code.jquery.com/jquery-2.1.3.min.js"))
assert(splash:go("https://www.taobao.com"))
local version = splash:evaljs("$.fn.jquery")
return 'JQuery version: ' .. version
end運行結果如下:
JQuery version: 2.1.3
call_later()
此方法可以通過設置定時任務和延遲時間來實現任務延時執行,并且可以在執行前通過cancel()方法重新執行定時任務。示例如下:
function main(splash, args)
local snapshots = {}
local timer = splash:call_later(function()
snapshots["a"] = splash:png()
splash:wait(1.0)
snapshots["b"] = splash:png()
end, 0.2)
splash:go("https://www.taobao.com")
splash:wait(3.0)
return snapshots
end這里我們設置了一個定時任務,0.2秒的時候獲取網頁截圖,然后等待1秒,1.2秒時再次獲取網頁截圖,訪問的頁面是淘寶,最后將截圖結果返回。運行結果如圖7-11所示。

圖7-11 運行結果
可以發現,第一次截圖時網頁還沒有加載出來,截圖為空,第二次網頁便加載成功了。
http_get()
此方法可以模擬發送HTTP的GET請求,使用方法如下:
response = splash:http_get{url, headers=nil, follow_redirects=true}參數說明如下。
url:請求URL。
headers:可選參數,默認為空,請求頭。
follow_redirects:可選參數,表示是否啟動自動重定向,默認為true。
示例如下:
function main(splash, args)
local treat = require("treat")
local response = splash:http_get("http://httpbin.org/get")
return {
html=treat.as_string(response.body),
url=response.url,
status=response.status
}
end運行結果如下:
Splash Response: Object
html: String (length 355)
{
"args": {},
"headers": {
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0
Safari/602.1"
},
"origin": "60.207.237.85",
"url": "http://httpbin.org/get"
}
status: 200
url: "http://httpbin.org/get"和http_get()方法類似,此方法用來模擬發送POST請求,不過多了一個參數body,使用方法如下:
response = splash:http_post{url, headers=nil, follow_redirects=true, body=nil}參數說明如下。
url:請求URL。
headers:可選參數,默認為空,請求頭。
follow_redirects:可選參數,表示是否啟動自動重定向,默認為true。
body:可選參數,即表單數據,默認為空。
我們用實例感受一下:
function main(splash, args)
local treat = require("treat")
local json = require("json")
local response = splash:http_post{"http://httpbin.org/post",
body=json.encode({name="Germey"}),
headers={["content-type"]="application/json"}
}
return {
html=treat.as_string(response.body),
url=response.url,
status=response.status
}
end運行結果如下:
Splash Response: Object
html: String (length 533)
{
"args": {},
"data": "{\"name\": \"Germey\"}",
"files": {},
"form": {},
"headers": {
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Content-Length": "18",
"Content-Type": "application/json",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0
Safari/602.1"
},
"json": {
"name": "Germey"
},
"origin": "60.207.237.85",
"url": "http://httpbin.org/post"
}
status: 200
url: "http://httpbin.org/post"可以看到,這里我們成功模擬提交了POST請求并發送了表單數據。
set_content()
此方法用來設置頁面的內容,示例如下:
function main(splash)
assert(splash:set_content("<html><body><h2>hello</h2></body></html>"))
return splash:png()
end運行結果如圖7-12所示。
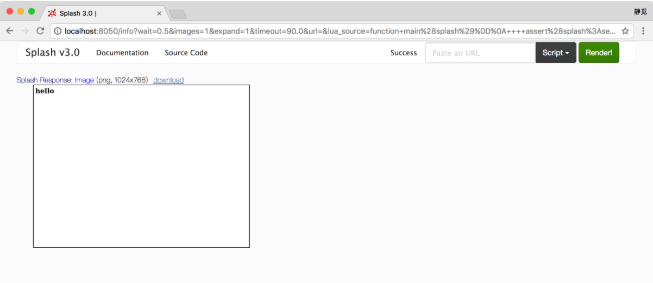
圖7-12 運行結果
html()
此方法用來獲取網頁的源代碼,它是非常簡單又常用的方法。示例如下:
function main(splash, args)
splash:go("https://httpbin.org/get")
return splash:html()
end運行結果如下:
<html><head></head><body><pre >{
"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0
Safari/602.1"
},
"origin": "60.207.237.85",
"url": "https://httpbin.org/get"
}
</pre></body></html>png()
此方法用來獲取PNG格式的網頁截圖,示例如下:
function main(splash, args)
splash:go("https://www.taobao.com")
return splash:png()
endjpeg()
此方法用來獲取JPEG格式的網頁截圖,示例如下:
function main(splash, args)
splash:go("https://www.taobao.com")
return splash:jpeg()
endhar()
此方法用來獲取頁面加載過程描述,示例如下:
function main(splash, args)
splash:go("https://www.baidu.com")
return splash:har()
end運行結果如圖7-13所示,其中顯示了頁面加載過程中每個請求記錄的詳情。
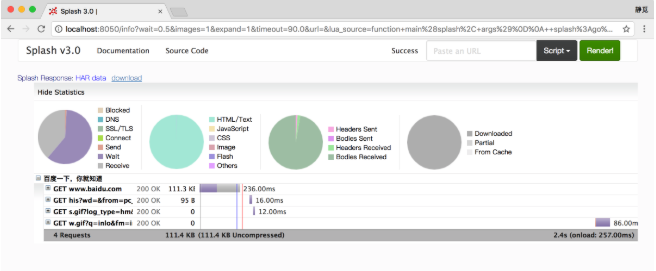
圖7-13 運行結果
url()
此方法可以獲取當前正在訪問的URL,示例如下:
function main(splash, args)
splash:go("https://www.baidu.com")
return splash:url()
end運行結果如下:
https://www.baidu.com/
get_cookies()
此方法可以獲取當前頁面的Cookies,示例如下:
function main(splash, args)
splash:go("https://www.baidu.com")
return splash:get_cookies()
end運行結果如下:
Splash Response: Array[2] 0: Object domain: ".baidu.com" expires: "2085-08-21T20:13:23Z" httpOnly: false name: "BAIDUID" path: "/" secure: false value: "C1263A470B02DEF45593B062451C9722:FG=1" 1: Object domain: ".baidu.com" expires: "2085-08-21T20:13:23Z" httpOnly: false name: "BIDUPSID" path: "/" secure: false value: "C1263A470B02DEF45593B062451C9722"
此方法可以為當前頁面添加Cookie,用法如下:
cookies = splash:add_cookie{name, value, path=nil, domain=nil, expires=nil, httpOnly=nil, secure=nil}該方法的各個參數代表Cookie的各個屬性。
示例如下:
function main(splash)
splash:add_cookie{"sessionid", "237465ghgfsd", "/", domain="http://example.com"}
splash:go("http://example.com/")
return splash:html()
endclear_cookies()
此方法可以清除所有的Cookies,示例如下:
function main(splash)
splash:go("https://www.baidu.com/")
splash:clear_cookies()
return splash:get_cookies()
end這里我們清除了所有的Cookies,然后調用get_cookies()將結果返回。
運行結果如下:
Splash Response: Array[0]
可以看到,Cookies被全部清空,沒有任何結果。
get_viewport_size()
此方法可以獲取當前瀏覽器頁面的大小,即寬高,示例如下:
function main(splash)
splash:go("https://www.baidu.com/")
return splash:get_viewport_size()
end運行結果如下:
Splash Response: Array[2] 0: 1024 1: 768
set_viewport_size()
此方法可以設置當前瀏覽器頁面的大小,即寬高,用法如下:
splash:set_viewport_size(width, height)
例如,這里訪問一個寬度自適應的頁面:
function main(splash)
splash:set_viewport_size(400, 700)
assert(splash:go("http://cuiqingcai.com"))
return splash:png()
end運行結果如圖7-14所示。
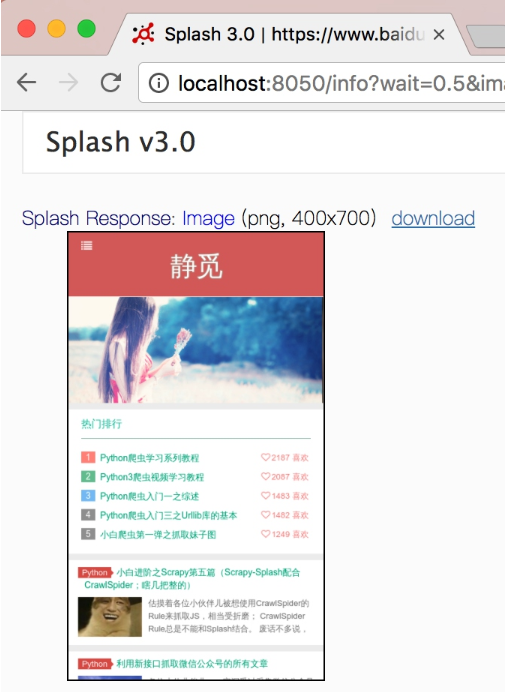
圖7-14 運行結果
set_viewport_full()
此方法可以設置瀏覽器全屏顯示,示例如下:
function main(splash)
splash:set_viewport_full()
assert(splash:go("http://cuiqingcai.com"))
return splash:png()
end此方法可以設置瀏覽器的User-Agent,示例如下:
function main(splash)
splash:set_user_agent('Splash')
splash:go("http://httpbin.org/get")
return splash:html()
end這里我們將瀏覽器的User-Agent設置為Splash,運行結果如下:
<html><head></head><body><pre >{
"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Splash"
},
"origin": "60.207.237.85",
"url": "http://httpbin.org/get"
}
</pre></body></html>可以看到,此處User-Agent被成功設置。
set_custom_headers()
此方法可以設置請求頭,示例如下:
function main(splash)
splash:set_custom_headers({
["User-Agent"] = "Splash",
["Site"] = "Splash",
})
splash:go("http://httpbin.org/get")
return splash:html()
end這里我們設置了請求頭中的User-Agent和Site屬性,運行結果如下:
<html><head></head><body><pre >{
"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Host": "httpbin.org",
"Site": "Splash",
"User-Agent": "Splash"
},
"origin": "60.207.237.85",
"url": "http://httpbin.org/get"
}
</pre></body></html>該方法可以選中符合條件的第一個節點,如果有多個節點符合條件,則只會返回一個,其參數是CSS選擇器。示例如下:
function main(splash)
splash:go("https://www.baidu.com/")
input = splash:select("#kw")
input:send_text('Splash')
splash:wait(3)
return splash:png()
end這里我們首先訪問了百度,然后選中了搜索框,隨后調用了send_text()方法填寫了文本,然后返回網頁截圖。
結果如圖7-15所示,可以看到,我們成功填寫了輸入框。
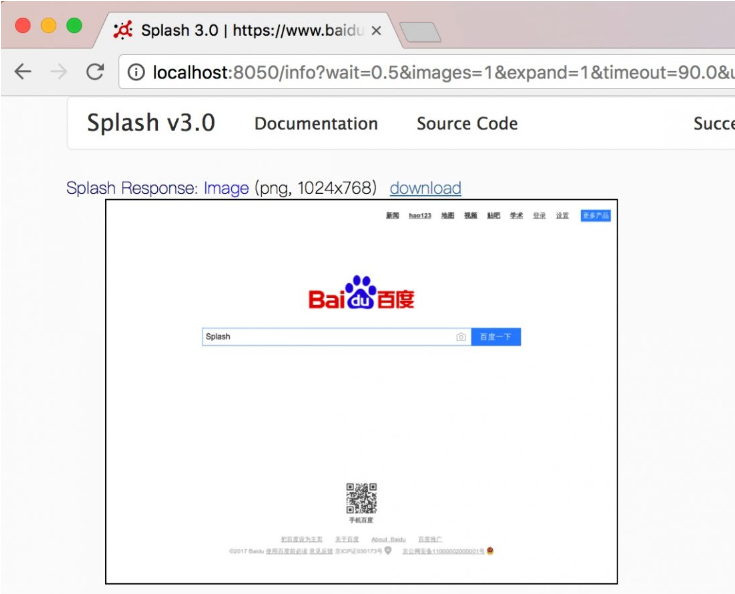
圖7-15 運行結果
select_all()
此方法可以選中所有符合條件的節點,其參數是CSS選擇器。示例如下:
function main(splash)
local treat = require('treat')
assert(splash:go("http://quotes.toscrape.com/"))
assert(splash:wait(0.5))
local texts = splash:select_all('.quote .text')
local results = {}
for index, text in ipairs(texts) do
results[index] = text.node.innerHTML
end
return treat.as_array(results)
end這里我們通過CSS選擇器選中了節點的正文內容,隨后遍歷了所有節點,將其中的文本獲取下來。
運行結果如下:
Splash Response: Array[10] 0: "“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”" 1: "“It is our choices, Harry, that show what we truly are, far more than our abilities.”" 2: “There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.” 3: "“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”" 4: "“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”" 5: "“Try not to become a man of success. Rather become a man of value.”" 6: "“It is better to be hated for what you are than to be loved for what you are not.”" 7: "“I have not failed. I've just found 10,000 ways that won't work.”" 8: "“A woman is like a tea bag; you never know how strong it is until it's in hot water.”" 9: "“A day without sunshine is like, you know, night.”"
可以發現,我們成功地將10個節點的正文內容獲取了下來。
mouse_click()
此方法可以模擬鼠標點擊操作,傳入的參數為坐標值x和y。此外,也可以直接選中某個節點,然后調用此方法,示例如下:
function main(splash)
splash:go("https://www.baidu.com/")
input = splash:select("#kw")
input:send_text('Splash')
submit = splash:select('#su')
submit:mouse_click()
splash:wait(3)
return splash:png()
end這里我們首先選中頁面的輸入框,輸入了文本,然后選中“提交”按鈕,調用了mouse_click()方法提交查詢,然后頁面等待三秒,返回截圖,結果如圖7-16所示。
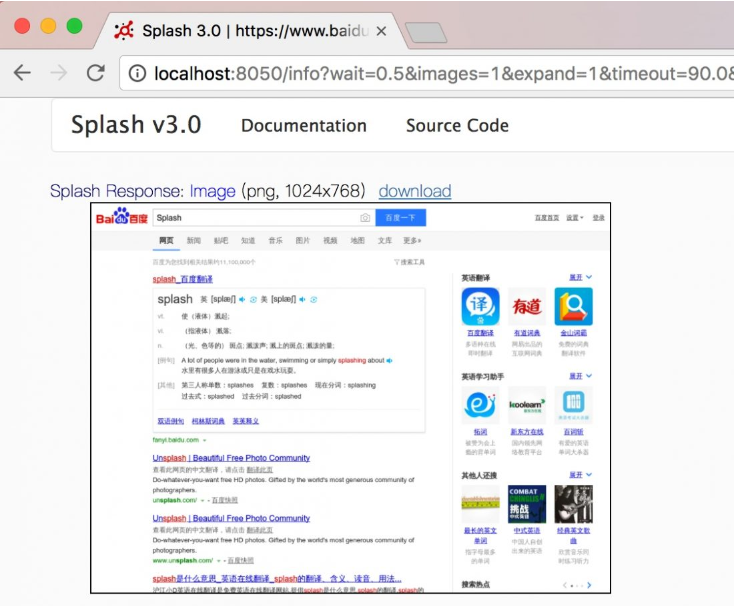
圖7-16 運行結果
可以看到,這里我們成功獲取了查詢后的頁面內容,模擬了百度搜索操作。
前面介紹了Splash的常用API操作,還有一些API在這不再一一介紹,更加詳細和權威的說明可以參見官方文檔https://splash.readthedocs.io/en/stable/scripting-ref.html,此頁面介紹了Splash對象的所有API操作。另外,還有針對頁面元素的API操作,鏈接為https://splash.readthedocs.io/en/stable/scripting-element-object.html。
7. Splash API調用
前面說明了Splash Lua腳本的用法,但這些腳本是在Splash頁面中測試運行的,如何才能利用Splash渲染頁面呢?怎樣才能和Python程序結合使用并抓取JavaScript渲染的頁面呢?
其實Splash給我們提供了一些HTTP API接口,我們只需要請求這些接口并傳遞相應的參數即可,下面簡要介紹這些接口。
render.html
此接口用于獲取JavaScript渲染的頁面的HTML代碼,接口地址就是Splash的運行地址加此接口名稱,例如http://localhost:8050/render.html。可以用curl來測試一下:
curl http://localhost:8050/render.html?url=https://www.baidu.com
我們給此接口傳遞了一個url參數來指定渲染的URL,返回結果即頁面渲染后的源代碼。
如果用Python實現的話,代碼如下:
import requests url = 'http://localhost:8050/render.html?url=https://www.baidu.com' response = requests.get(url) print(response.text)
這樣就可以成功輸出百度頁面渲染后的源代碼了。
另外,此接口還可以指定其他參數,比如通過wait指定等待秒數。如果要確保頁面完全加載出來,可以增加等待時間,例如:
import requests url = 'http://localhost:8050/render.html?url=https://www.taobao.com&wait=5' response = requests.get(url) print(response.text)
此時得到響應的時間就會相應變長,比如這里會等待5秒多鐘才能獲取淘寶頁面的源代碼。
另外,此接口還支持代理設置、圖片加載設置、Headers設置、請求方法設置,具體的用法可以參見官方文檔https://splash.readthedocs.io/en/stable/api.html#render-html。
render.png
此接口可以獲取網頁截圖,其參數比render.html多了幾個,比如通過width和height來控制寬高,它返回的是PNG格式的圖片二進制數據。示例如下:
curl http://localhost:8050/render.png?url=https://www.taobao.com&wait=5&width=1000&height=700
這里我們傳入了width和height來設置頁面大小為1000×700像素。
如果用Python實現,可以將返回的二進制數據保存為PNG格式的圖片,具體如下:
import requests
url = 'http://localhost:8050/render.png?url=https://www.jd.com&wait=5&width=1000&height=700'
response = requests.get(url)
with open('taobao.png', 'wb') as f:
f.write(response.content)得到的圖片如圖7-17所示。
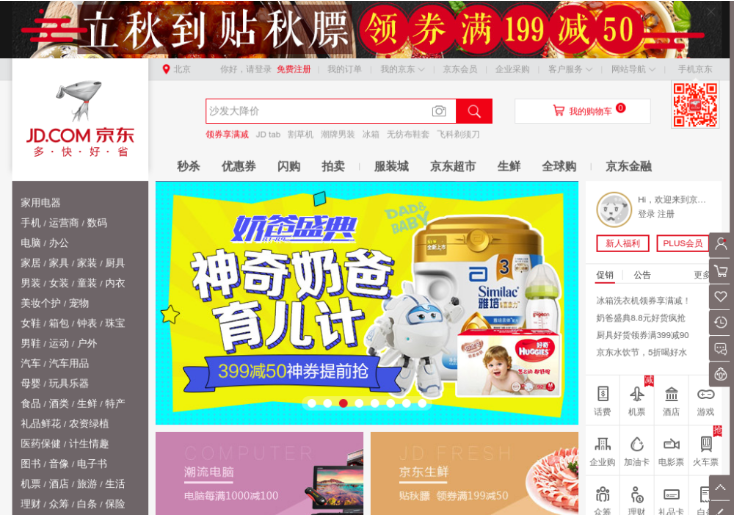
圖7-17 運行結果
這樣我們就成功獲取了京東首頁渲染完成后的頁面截圖,詳細的參數設置可以參考官網文檔https://splash.readthedocs.io/en/stable/api.html#render-png。
render.jpeg
此接口和render.png類似,不過它返回的是JPEG格式的圖片二進制數據。
另外,此接口比render.png多了參數quality,它用來設置圖片質量。
render.har
此接口用于獲取頁面加載的HAR數據,示例如下:
curl http://localhost:8050/render.har?url=https://www.jd.com&wait=5
它的返回結果(如圖7-18所示)非常多,是一個JSON格式的數據,其中包含頁面加載過程中的HAR數據。
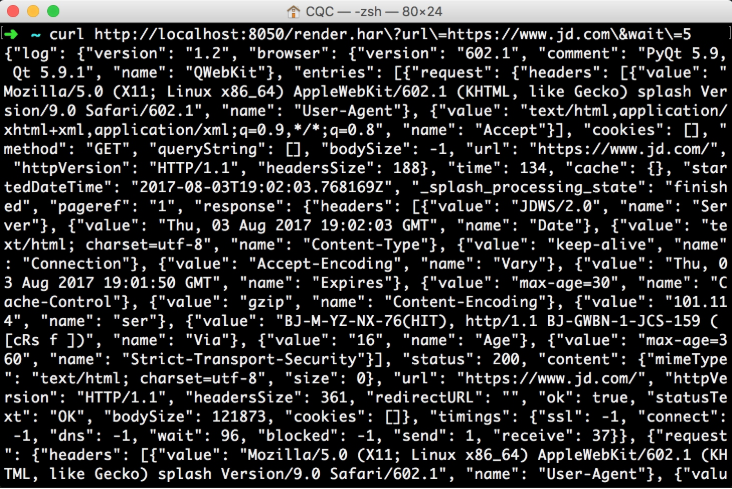
圖7-18 運行結果
render.json
此接口包含了前面接口的所有功能,返回結果是JSON格式,示例如下:
curl http://localhost:8050/render.json?url=https://httpbin.org
結果如下:
{"title": "httpbin(1): HTTP Client Testing Service", "url": "https://httpbin.org/", "requestedUrl": "https:
//httpbin.org/", "geometry": [0, 0, 1024, 768]}可以看到,這里以JSON形式返回了相應的請求數據。
我們可以通過傳入不同參數控制其返回結果。比如,傳入html=1,返回結果即會增加源代碼數據;傳入png=1,返回結果即會增加頁面PNG截圖數據;傳入har=1,則會獲得頁面HAR數據。例如:
curl http://localhost:8050/render.json?url=https://httpbin.org&html=1&har=1
這樣返回的JSON結果會包含網頁源代碼和HAR數據。
此外還有更多參數設置,具體可以參考官方文檔:https://splash.readthedocs.io/en/stable/api.html#render-json。
execute
此接口才是最為強大的接口。前面說了很多Splash Lua腳本的操作,用此接口便可實現與Lua腳本的對接。
前面的render.html和render.png等接口對于一般的JavaScript渲染頁面是足夠了,但是如果要實現一些交互操作的話,它們還是無能為力,這里就需要使用execute接口了。
我們先實現一個最簡單的腳本,直接返回數據:
function main(splash) return 'hello' end
然后將此腳本轉化為URL編碼后的字符串,拼接到execute接口后面,示例如下:
curl http://localhost:8050/execute?lua_source=function+main%28splash%29%0D%0A++return+%27hello%27%0D%0Aend
運行結果如下:
hello
這里我們通過lua_source參數傳遞了轉碼后的Lua腳本,通過execute接口獲取了最終腳本的執行結果。
這里我們更加關心的肯定是如何用Python來實現,上例用Python實現的話,代碼如下:
import requests from urllib.parse import quote lua = ''' function main(splash) return 'hello' end ''' url = 'http://localhost:8050/execute?lua_source=' + quote(lua) response = requests.get(url) print(response.text)
運行結果如下:
hello
這里我們用Python中的三引號將Lua腳本包括起來,然后用urllib.parse模塊里的quote()方法將腳本進行URL轉碼,隨后構造了Splash請求URL,將其作為lua_source參數傳遞,這樣運行結果就會顯示Lua腳本執行后的結果。
我們再通過實例看一下:
import requests
from urllib.parse import quote
lua = '''
function main(splash, args)
local treat = require("treat")
local response = splash:http_get("http://httpbin.org/get")
return {
html=treat.as_string(response.body),
url=response.url,
status=response.status
}
end
'''
url = 'http://localhost:8050/execute?lua_source=' + quote(lua)
response = requests.get(url)
print(response.text)運行結果如下:
{"url": "http://httpbin.org/get", "status": 200, "html": "{\n \"args\": {}, \n \"headers\": {\n
\"Accept-Encoding\": \"gzip, deflate\", \n \"Accept-Language\": \"en,*\", \n \"Connection\":
\"close\", \n \"Host\": \"httpbin.org\", \n \"User-Agent\": \"Mozilla/5.0 (X11; Linux x86_64)
AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1\"\n }, \n \"origin\": \"60.207.237.85\",
\n \"url\": \"http://httpbin.org/get\"\n}\n"}可以看到,返回結果是JSON形式,我們成功獲取了請求的URL、狀態碼和網頁源代碼。
如此一來,我們之前所說的Lua腳本均可以用此方式與Python進行對接,所有網頁的動態渲染、模擬點擊、表單提交、頁面滑動、延時等待后的一些結果均可以自由控制,獲取頁面源碼和截圖也都不在話下。
到現在為止,我們可以用Python和Splash實現JavaScript渲染的頁面的抓取了。除了Selenium,本節所說的Splash同樣可以做到非常強大的渲染功能,同時它也不需要瀏覽器即可渲染,使用非常方便。
關于Python3爬蟲中Splash有什么用就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





