溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python畫P-R曲線的方法,相信大部分人都還不怎么了解,因此分享這邊文章給大家學習,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去學習方法吧!
Python如何畫P-R曲線
Python生成P-R圖需要安裝第三方庫matplotlib、numpy及sklearn。
推薦學習《Python教程》。
P-R曲線的生成方法:
根據學習器的預測結果對樣本進行排序,排在前面的是學習器認為最可能是正例的樣本,排在最后的是最不可能是正例的樣本,按此順序逐個將樣本作為正例預測,則每次可以計算出當前的查全率、查準率,以查全率為橫軸、查準率為縱軸做圖,得到的查準率-查全率曲線即為P-R曲線。
也就是說對每個樣本預測其為正例的概率,然后將所有樣本按預測的概率進行排序,然后依次將排序后的樣本做為正例進行預測,從而得到每次預測的查全率與查準率。這個依次將樣本做為正例的過程實際上就是逐步降低樣本為正例的概率的域值,通過降低域值,更多的樣本會被預測為正例,從而會提高查全率,相對的查準率可能降低,而隨著后面負樣本的增加,查全率提高緩慢甚至沒有提升,精度降低會更快。
sklearn的計算過程與定義相反是按概率從小到大遞增的順序來計算查準率與查全率的,并且分別為查準率和查全率添加了1和0。
#coding:utf-8
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
from sklearn.utils.fixes import signature
plt.figure("P-R Curve")
plt.title('Precision/Recall Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
#y_true為樣本實際的類別,y_scores為樣本為正例的概率
y_true = np.array([1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0])
y_scores = np.array([0.9, 0.75, 0.86, 0.47, 0.55, 0.56, 0.74, 0.62, 0.5, 0.86, 0.8, 0.47, 0.44, 0.67, 0.43, 0.4, 0.52, 0.4, 0.35, 0.1])
precision, recall, thresholds = precision_recall_curve(y_true, y_scores)
#print(precision)
#print(recall)
#print(thresholds)
plt.plot(recall,precision)
plt.show()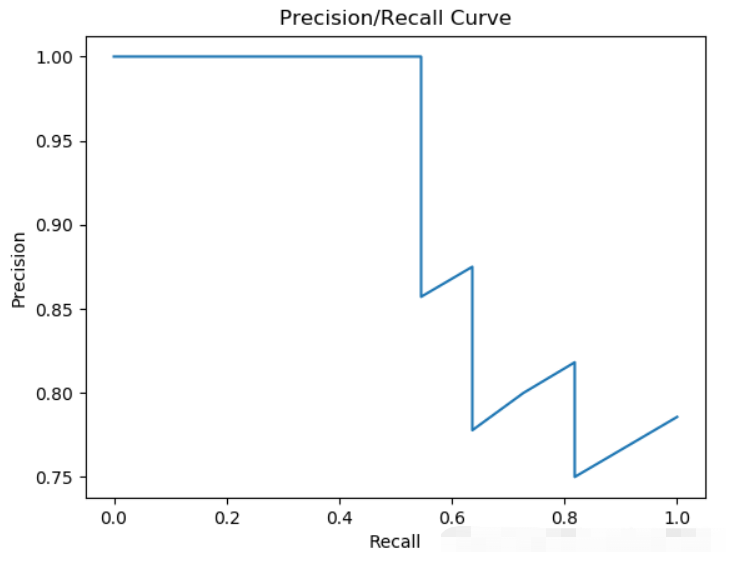
以上是Python畫P-R曲線的方法的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





