溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
EhCache 是一個純 Java 的進程內緩存框架,具有快速、精干等特點,是 Hibernate 中默認的 CacheProvider。
下圖是 EhCache 在應用程序中的位置:
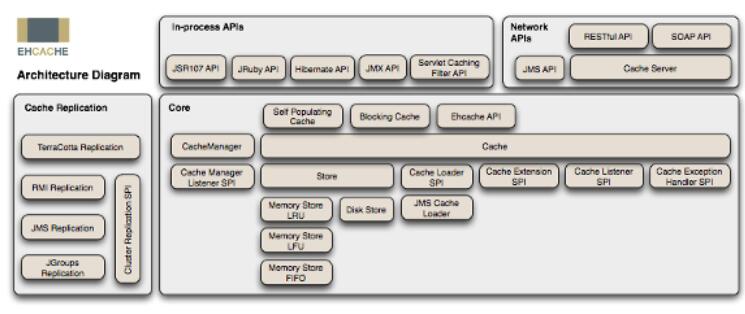
EhCache 的主要特性有:
1.快速;
2.簡單;
3.多種緩存策略;
4.緩存數據有兩級:內存和磁盤,因此無需擔心容量問題;
5.緩存數據會在虛擬機重啟的過程中寫入磁盤;
6.可以通過 RMI、可插入 API 等方式進行分布式緩存;
7.具有緩存和緩存管理器的偵聽接口;
8.支持多緩存管理器實例,以及一個實例的多個緩存區域;
9.提供 Hibernate 的緩存實現;
10.等等 …
由于 EhCache 是進程中的緩存系統,一旦將應用部署在集群環境中,每一個節點維護各自的緩存數據,當某節點對緩存數據進行更新,這些更新的數據無法在其它節點中共享,這不僅會降低節點運行的效率,而且會導致數據不同步的情況發生。例如某個網站采用 A、B 兩個節點作為集群部署,當 A 節點的緩存更新后,而 B 節點緩存尚未更新就可能出現用戶在瀏覽頁面的時候,一會是更新后的數據,一會是尚未更新的數據,盡管我們也可以通過 Session Sticky 技術來將用戶鎖定在某個節點上,但對于一些交互性比較強或者是非 Web 方式的系統來說,Session Sticky 顯然不太適合。所以就需要用到 EhCache 的集群解決方案。
EhCache 從 1.7 版本開始,支持五種集群方案,分別是:
• Terracotta
• RMI
• JMS
• JGroups
• EhCache Server
本文主要介紹其中的三種最為常用集群方式,分別是 RMI、JGroups 以及 EhCache Server 。
RMI 集群模式:
RMI 是 Java 的一種遠程方法調用技術,是一種點對點的基于 Java 對象的通訊方式。EhCache 從 1.2 版本開始就支持 RMI 方式的緩存集群。在集群環境中 EhCache 所有緩存對象的鍵和值都必須是可序列化的,也就是必須實現 java.io.Serializable 接口,這點在其它集群方式下也是需要遵守的。
下圖是 RMI 集群模式的結構圖:
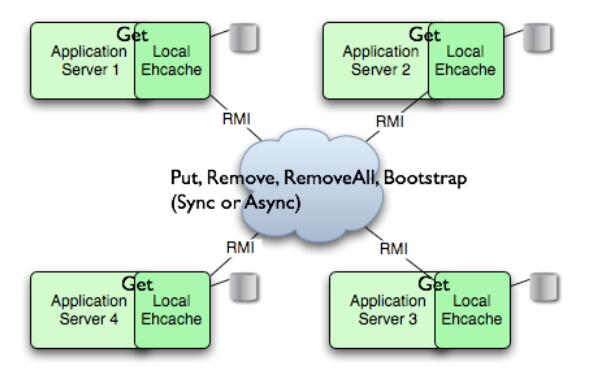
圖 2. RMI 集群模式結構圖:
采用 RMI 集群模式時,集群中的每個節點都是對等關系,并不存在主節點或者從節點的概念,因此節點間必須有一個機制能夠互相認識對方,必須知道其它節點的信息,包括主機地址、端口號等。EhCache 提供兩種節點的發現方式:手工配置和自動發現。手工配置方式要求在每個節點中配置其它所有節點的連接信息,一旦集群中的節點發生變化時,需要對緩存進行重新配置。
由于 RMI 是 Java 中內置支持的技術,因此使用 RMI 集群模式時,無需引入其它的 Jar 包,EhCache 本身就帶有支持 RMI 集群的功能。使用 RMI 集群模式需要在 ehcache.xml 配置文件中定義cacheManagerPeerProviderFactory 節點。假設集群中有兩個節點,分別對應的 RMI 綁定信息是:
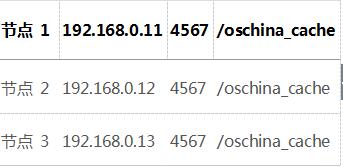
那么對應的手工配置信息如下:
<cacheManagerPeerProviderFactory class="net.sf.ehcache.distribution.RMICacheManagerPeerProviderFactory" properties="hostName=localhost, port=4567, socketTimeoutMillis=2000, peerDiscovery=manual, rmiUrls=//192.168.0.12:4567/oschina_cache|//192.168.0.13:4567/oschina_cache" />
其它節點配置類似,只需把 rmiUrls 中的兩個 IP 地址換成另外兩個節點對應的 IP 地址即可。
接下來在需要進行緩存數據復制的區域(Region)上配置如下即可:
<cache name="sampleCache2" maxElementsInMemory="10" eternal="false" timeToIdleSeconds="100" timeToLiveSeconds="100" overflowToDisk="false"> <cacheEventListenerFactory class="net.sf.ehcache.distribution.RMICacheReplicatorFactory" properties="replicateAsynchronously=true, replicatePuts=true, replicateUpdates=true, replicateUpdatesViaCopy=false, replicateRemovals=true "/> </cache>
具體每個參數代表的意義請參考 EhCache 的手冊,此處不再詳細說明。
EhCache 的 RMI 集群模式還有另外一種節點發現方式,就是通過多播( multicast )來維護集群中的所有有效節點。這也是最為簡單而且靈活的方式,與手工模式不同的是,每個節點上的配置信息都相同,大大方便了節點的部署,避免人為的錯漏出現。
在上述三個節點的例子中,配置如下:
<cacheManagerPeerProviderFactory class="net.sf.ehcache.distribution.RMICacheManagerPeerProviderFactory" properties="peerDiscovery=automatic, multicastGroupAddress=230.0.0.1, multicastGroupPort=4446, timeToLive=32" />
其中需要指定節點發現模式 peerDiscovery 值為 automatic 自動;同時組播地址可以指定 D 類 IP 地址空間,范圍從 224.0.1.0 到 238.255.255.255 中的任何一個地址
JGroups 集群模式
EhCache 從 1.5. 版本開始增加了 JGroups 的分布式集群模式。與 RMI 方式相比較, JGroups 提供了一個非常靈活的協議棧、可靠的單播和多播消息傳輸,主要的缺點是配置復雜以及一些協議棧對第三方包的依賴。
JGroups 也提供了基于 TCP 的單播 ( Unicast ) 和基于 UDP 的多播 ( Multicast ) ,對應 RMI 的手工配置和自動發現。使用單播方式需要指定其它節點的主機地址和端口,下面是兩個節點,并使用了單播方式的配置:
<cacheManagerPeerProviderFactory class="net.sf.ehcache.distribution.jgroups.JGroupsCacheManagerPeerProviderFactory" properties="connect=TCP(start_port=7800): TCPPING(initial_hosts=host1[7800],host2[7800];port_range=10;timeout=3000; num_initial_members=3;up_thread=true;down_thread=true): VERIFY_SUSPECT(timeout=1500;down_thread=false;up_thread=false): pbcast.NAKACK(down_thread=true;up_thread=true;gc_lag=100; retransmit_timeout=3000): pbcast.GMS(join_timeout=5000;join_retry_timeout=2000;shun=false; print_local_addr=false;down_thread=true;up_thread=true)" propertySeparator="::" />
使用多播方式配置如下:
<cacheManagerPeerProviderFactory class="net.sf.ehcache.distribution.jgroups.JGroupsCacheManagerPeerProviderFactory" properties="connect=UDP(mcast_addr=231.12.21.132;mcast_port=45566;):PING: MERGE2:FD_SOCK:VERIFY_SUSPECT:pbcast.NAKACK:UNICAST:pbcast.STABLE:FRAG:pbcast.GMS" propertySeparator="::" />
從上面的配置來看,JGroups 的配置要比 RMI 復雜得多,但也提供更多的微調參數,有助于提升緩存數據復制的性能。詳細的 JGroups 配置參數的具體意義可參考 JGroups 的配置手冊。
JGroups 方式對應緩存節點的配置信息如下:
<cache name="sampleCache2" maxElementsInMemory="10" eternal="false" timeToIdleSeconds="100" timeToLiveSeconds="100" overflowToDisk="false"> <cacheEventListenerFactory class="net.sf.ehcache.distribution.jgroups.JGroupsCacheReplicatorFactory" properties="replicateAsynchronously=true, replicatePuts=true, replicateUpdates=true, replicateUpdatesViaCopy=false, replicateRemovals=true" /> </cache>
使用組播方式的注意事項
使用 JGroups 需要引入 JGroups 的 Jar 包以及 EhCache 對 JGroups 的封裝包 ehcache-jgroupsreplication-xxx.jar 。
在一些啟用了 IPv6 的電腦中,經常啟動的時候報如下錯誤信息:
java.lang.RuntimeException: the type of the stack (IPv6) and the user supplied addresses (IPv4) don't match: /231.12.21.132.
解決的辦法是增加 JVM 參數:-Djava.net.preferIPv4Stack=true。如果是 Tomcat 服務器,可在 catalina.bat 或者 catalina.sh 中增加如下環境變量即可:
SET CATALINA_OPTS=-Djava.net.preferIPv4Stack=true
經過實際測試發現,集群方式下的緩存數據都可以在 1 秒鐘之內完成到其節點的復制
EhCache Server
與前面介紹的兩種集群方案不同的是, EhCache Server 是一個獨立的緩存服務器,其內部使用 EhCache 做為緩存系統,可利用前面提到的兩種方式進行內部集群。對外提供編程語言無關的基于 HTTP 的 RESTful 或者是 SOAP 的數據緩存操作接口。
下面是 EhCache Server 提供的對緩存數據進行操作的方法:
OPTIONS /{cache}}
獲取某個緩存的可用操作的信息。
HEAD /{cache}/{element}
獲取緩存中某個元素的 HTTP 頭信息,例如:
curl --head http://localhost:8080/ehcache/rest/sampleCache2/2
EhCache Server 返回的信息如下:
HTTP/1.1 200 OK
X-Powered-By: Servlet/2.5
Server: GlassFish/v3
Last-Modified: Sun, 27 Jul 2008 08:08:49 GMT
ETag: "1217146129490"
Content-Type: text/plain; charset=iso-8859-1
Content-Length: 157
Date: Sun, 27 Jul 2008 08:17:09 GMT
GET /{cache}/{element}
讀取緩存中某個數據的值。
PUT /{cache}/{element}
寫緩存。
由于這些操作都是基于 HTTP 協議的,因此你可以在任何一種編程語言中使用它,例如 Perl、PHP 和 Ruby 等等。
下圖是 EhCache Server 在應用中的架構:
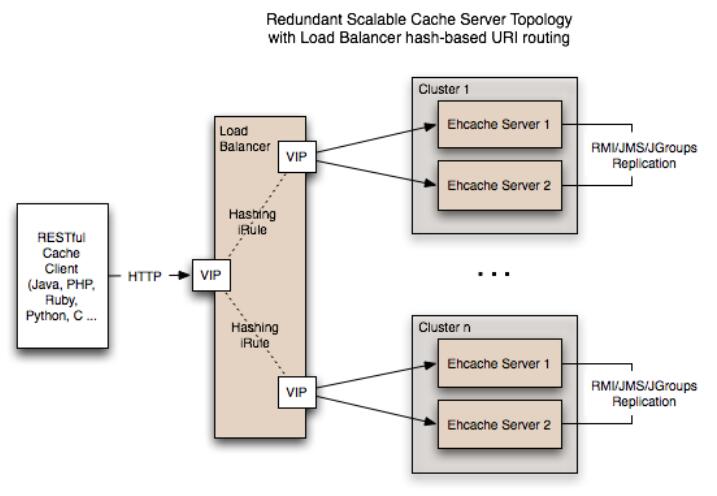
圖 3. EhCache Server 應用架構圖
EhCache Server 同時也提供強大的安全機制、監控功能。在數據存儲方面,最大的 Ehcache 單實例在內存中可以緩存 20GB。最大的磁盤可以緩存 100GB。通過將節點整合在一起,這樣緩存數據就可以跨越節點,以此獲得更大的容量。將緩存 20GB 的 50 個節點整合在一起就是 1TB 了
總結
以上我們介紹了三種 EhCache 的集群方案,除了第三種跨編程語言的方案外,EhCache 的集群對應用程序的代碼編寫都是透明的,程序人員無需考慮緩存數據是如何復制到其它節點上。既保持了代碼的輕量級,同時又支持龐大的數據集群。EhCache 可謂是深入人心。
2009 年年中,Terracotta 宣布收購 EhCache 產品。Terracotta 公司的產品 Terracotta 是一個 JVM 級的開源群集框架,提供 HTTP Session 復制、分布式緩存、POJO 群集、跨越集群的 JVM 來實現分布式應用程序協調。最近 EhCache 主要的改進都集中在跟 Terracotta 框架的集成上,這是一個真正意義上的企業級緩存解決方案。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





