溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
ambda即lambda表達式,簡稱lambda。本質上是可以傳遞給其它函數的一小段代碼。有了lambda,可以輕松地把通用代碼結構抽取成庫函數。lambda最常見的用途是和集合一起配合。kotlin甚至還擁有帶接收者的lambda,這是一種特殊的lambda。
本文是對<<kotlin實戰>>中 “lambda編程”一章的總結,主要記錄了一些我認為比較重要的點
在kotlin中常見的lambda用法主要由以下幾種:
lambda表達式的基本語法
下面是一個lambda表達式的基本語法:
{ x:Int, y:Int -> x + y }
lambda表達式始終用花括號包圍,實參并沒有用括號括起來。箭頭把實參列表和lambda的函數體隔開
lambda作為函數的參數傳遞
可以把lambda表達式存儲在一個變量中,把這個變量當做普通函數對待,也可以直接寫作函數參數,比如有一個intOperator函數, 這個函數接收兩個int參數,和一個函數。
fun intOperator(o1: Int, o2: Int, run: (a: Int, b: Int) -> Int) {
run(o1, o2)
}
val sumLambda = { x: Int, y: Int -> x + y }
intOperator(1, 2, sumLambda)
intOperator(1, 2, {x:Int, y:Int -> x + y})
上面可以看到,我們直接把lambda當做一個函數傳遞個intOperator()作為參數。
如果lambda表達式是函數調用的最后一個實參,它可以放到括號外邊:
intOperator(1, 2) { x: Int, y: Int -> x + y }
如果lambda表達式是函數的唯一實參時,還可以去掉調用代碼中的空括號對
比如下面這個例子
fun myPrint(lambda: () -> Unit) {
lambda()
}
myPrint{
print("a")
}
省略lambda參數類型并使用默認參數名稱
在kotlin中如果lambda參數的類型可以被推導出來,我們就不需要顯示聲明它,比如我們常用的庫函數 map:
listOf("1", "2", "3").map{
//
}
在這個代碼中使用了默認參數使用it代替。在kotlin中,如果當前上下文期望的是只有一個參數的lambda且這個參數的類型可以推斷出來,就會生成這個名稱。
允許在lambda內部訪問非final變量甚至修改他們
在java中我們是知道的:匿名內部類不能訪問非final變量,但在kotlin中可以:
fun main(args: Array<String>) {
var count = 0
listOf("1", "2", "3").forEach{
count++
}
print(count)
}
其實對于kotlin來說,如果在lambad中引用非final變量,它的值會被封裝起來,并且會和lambda代碼一塊存儲。
當然對于異步代碼或者事件響應回調這個是無效的。
成員引用
在上面我們知道可以直接把lambda當做函數的參數傳遞給一個函數,但是如果當做參數傳遞的代碼已經被定義成了函數那怎么辦呢?
在kotlin中可以使用::把函數轉換成一個值,從而傳遞給函數。這里比如有一個Person類,他有一個say函數,我們可以這樣獲得這個函數的引用:
val sayQuote = Person::say
這種表達式叫做成員引用,對于頂層函數可以直接 ::say,來獲得這個函數的引用。
常用的庫函數
對于集合,kotlin提供了豐富的庫函數便于我們使用,對于這些函數這里我們只介紹一些關鍵點。
filter與map
filter函數會遍歷集合并選出應用給定lambda后會返回true的那些元素, 需要注意的是,返回的是一個新的集合
val newList = listOf(1, 2, 3, 4).filter{ it % 2 == 0}
map函數對集合中的每一個元素應用給定的函數并把結果收集到一個新集合中
val newList = listOf(1, 2, 3, 4).map{ it.toSting() }
all、any、count、find
count 與 size
在一些情況下使用count要高效于size, 比如統計集合中有多少個偶數:
listOf(1, 2, 3, 4, 5).count({it % 2 == 0})
listOf(1, 2, 3, 4, 5).filter({it % 2 == 0}).size
上面兩種做法都可以實現這個需求,不過filter會創建一個新的集合,而 count方法只會跟蹤匹配元素的數量,不關心元素本身。
其他還有 groupBy/flatMap/flatten,這里不細講了。
惰性集合操作 : 序列
在說什么是惰性集合操作之前,我們先來看一下非惰性集合操作map與filter, 以獲取姓名為A開頭的人的名字為例:
peoples.map{it.name}.filter{it.startWith("A")}
我們要知道filter和map都會返回一個列表來保存結果,如果peoples這個集合元素非常多的話,那產生的這個中間集合就非常大,并且這個鏈式調用會非常低效。
為了解決這個問題kotlin引入了 惰性集合:序列, 序列中的元素的求值是惰性的,不需要創建集合來保存中間結果,我們可以使用序列來解決上面的問題:
peoples.asSequence().map{it.name}.filter{it.startWith("A")}.toList()
序列的操作
序列的操作分為兩類:中間和末端操作, 以上面那個例子為例:
peoples.asSequence().map{it.name}.filter{it.startWith("A")}.toList()
map、filter都是中間操作,toList為末端操作。一次中間操作返回的是另一個序列,這個新序列知道如何變換原始序列中的元素,而一次末端操作返回的是一個結果,這個結果可能是集合、元素、數字等。
序列中中間操作的計算都是由末端操作觸發的。
我們可以使用擴展函數asSequence把任意集合轉換成序列,調用toList來做反向轉換
我們來對比一下上面兩種方法:
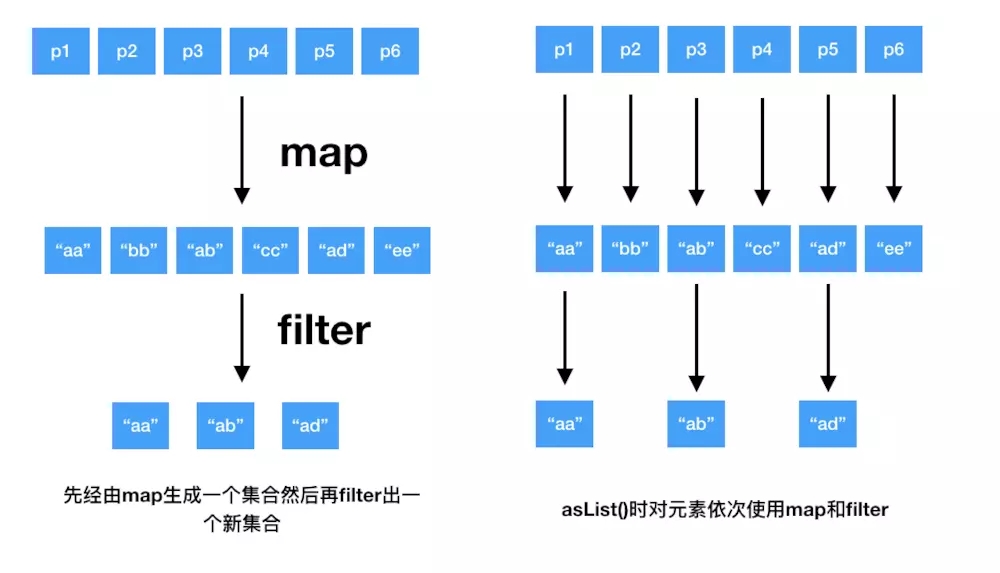
惰性集合.png
可以看到,使用序列會明顯比直接使用map和filter來完成這個任務效率更高
注意對于混合map/filter,這種操作時,如果被操作集合比較小,是不需要使用序列的。至于序列如何手動創建,這里不做細究
kotlin與Java函數式接口
函數式接口是指帶有一個抽象方法的接口,在java api中比如Runnable、Callable等
我們在實際使用kotlin時,可能大部分API還是java API,但是kotlin的lambda可以無縫地和javaAPI互操作,比如給一個button設置onclick事件:
button.setOnClickListener{ //... }
這個操作在java8之前我們不得不通過創建一個匿名內部類來實現。
lambda表達式的可重用性
比如有一個函數postponeComputation(),接收一個函數,并循環執行這個函數指定次數:
postponeComputation(1000, object:Runnable{
override fun run(){
print(42)
}
})
當你顯示聲明這個參數對象時,每次調用都會創建一個新的實例,而使用lambda情況不同:如果lambda沒有訪問任何來自自定義它的函數的變量,相應的匿名類實例可以在多次調用中重用:
postponeComputation(1000, { print(42) })
但是如果lambda從包圍它的作用域中捕捉了變量,每次調用就不再可能重用同一個實例了。 至于為什么將會在 Lambda的實現細節的講到。
Lambda的實現細節
在kotlin中,每個函數式接口的lambda都會被編譯成一個匿名類(除內聯lambda)。如果lambda捕捉了變量,每個被捕捉的變量會在匿名內部類中有對應的字段,而且每次調用這個lambda都會創建一個這個匿名內部類的實例。如果沒有捕捉變量,就會創建一個單例的類。
編譯后的匿名內部類的名稱由lambda聲明所在的函數名稱加上后綴衍生出來的,比如下面這個lambda:
class Person{
fun test(){
a.setRunnable({
print("a")
})
}
}
這個lambda會被編譯成:
class Person$1:Runnable{
override fun run(){
print("a")
}
}
lambda與函數式接口的轉換
有些時候我們需要函數式接口的實例,比如一個方法返回的是一個函數式接口,這時候就不能直接返回一個lambda了:
fun getRunnable():Runnable{}
這時候如果直接這樣寫就會報錯 : fun getRunnable() = { } ,這是因為編譯器不會智能轉換,不過kotlin提供了 函數式接口構造方法來使操作更方便:
fun getRunnable() = Runnable{ }
Runnable{}是編譯器生成的方法,等同于使用匿名對象的方式。
帶接收者的lambda: with 與 apply
這兩個函數式kotlin標準庫中的函數。帶接受者是指:在lambda函數體可以調用一個不同對象的方法,而且無須借助任何額外限定符。
with
with是一個接收兩個參數的函數,一個參數是 被接收者, 它會被傳給第二個參數 lambda表達式 , 在lambda表達式著呢個我們可以不用任何限定符直接訪問這個值的方法和屬性
fun alphabet():String{
val stringBuilder = StringBuilder()
return with(stringBuilder){
for(letter in 'A'..'Z'){
append(letter) //也可以使用this.append()
}
toString()
}
}
with的返回值是執行了lambda代碼的結果
apply
apply與with的唯一區別是它始終返回接收者對象。上面的函數我們可以這樣改寫:
fun alphabet() = StringBuilder().apply{
for(letter in 'A'..'Z'){
append(letter) //也可以使用this.append()
}
}.toString()
內聯函數:消除Lambda帶來的運行時開銷
上面我們已經知道,lambda表達式會被正常地編譯成匿名類,這表示每調用一次lambda表達式,一個額外的類就會被創建,為了解決這個運行時性能的開銷,kotlin提供了inline修飾符,如果使用inline
修飾符標記一個函數,在函數被使用的時候編譯器并不會生成函數調用的代碼,而是使用函數實現的真實代碼替換每一次的函數調用。
先來舉一個例子:
inline fun test(action:()->T){
action()
}
fun foo(){
test{
print("a")
}
}
foo()實際會被編譯為下面的代碼:
fun foo_(){
print("a")
}
從上面這個例子可以看出,作為參數的lambda表達式會被直接替換到最終生成的代碼中,而不是被包含在一個實現了函數接口的匿名類中。
注意如果lambda參數在某個地方被保存起來,以便后面可以繼續使用,這種lambda表達式將不會被內聯,因為必須要有一個包含這些代碼的對象存在
內聯的集合操作
kotlin標準庫中的map、filter等大部分函數都是內聯函數,因此使用標準庫函數不需要擔心性能開銷。
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,如果有疑問大家可以留言交流,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





