溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關TensorFlow如何實現RNN循環的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
RNN(recurrent neural Network)循環神經網絡
主要用于自然語言處理(nature language processing,NLP)
RNN主要用途是處理和預測序列數據
RNN廣泛的用于 語音識別、語言模型、機器翻譯
RNN的來源就是為了刻畫一個序列當前的輸出與之前的信息影響后面節點的輸出
RNN 是包含循環的網絡,允許信息的持久化。
RNN會記憶之前的信息,并利用之前的信息影響后面節點的輸出。
RNN的隱藏層之間的節點是有相連的,隱藏層的輸入不僅僅包括輸入層的輸出,還包括上一時刻隱藏層的輸出。
RNN會對于每一個時刻的輸入結合當前模型的狀態給出一個輸出。
RNN理論上被看作同一個神經網絡結構被無限復制的結果,目前RNN無法做到真正的無限循環,一般以循環體展開。
RNN圖:
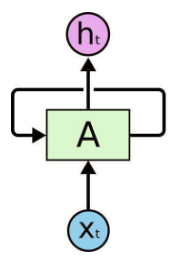
RNN最擅長的問題是與時間序列相關的。
RNN對于一個序列數據,可以將序列上不同時刻的數據依次輸入循環神經網絡的輸入層,而輸出可以是對序列中下一個時刻的預測,也可以是對當前時刻信息的處理結果。
RNN 的關鍵點之一就是他們可以用來連接先前的信息到當前的任務上
展開后的RNN:
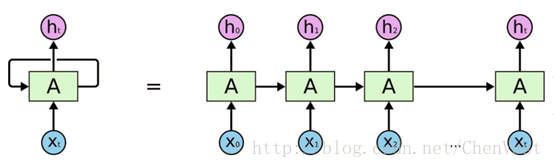
循環體網絡中的參數在不同的時刻也是共享的。
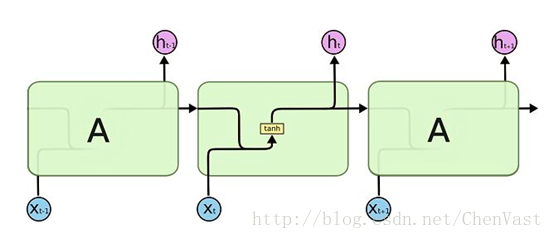
RNN的狀態是通過一個向量來表示,這個向量的維度也稱為RNN隱藏層的大小。
假如該向量為h,輸入為x,激活函數為tanh,則有如圖:
前向傳播的計算過程:
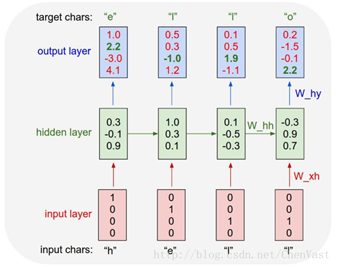
理論上RNN可以支持任意長度的序列,但是如果序列太長會導致優化時實現梯度消失的問題,一般會設置最大長度,超長會對其截斷。
代碼實現簡單的RNN:
import numpy as np
# 定義RNN的參數。
X = [1,2]
state = [0.0, 0.0]
w_cell_state = np.asarray([[0.1, 0.2], [0.3, 0.4]])
w_cell_input = np.asarray([0.5, 0.6])
b_cell = np.asarray([0.1, -0.1])
w_output = np.asarray([[1.0], [2.0]])
b_output = 0.1
# 執行前向傳播過程。
for i in range(len(X)):
before_activation = np.dot(state, w_cell_state) + X[i] * w_cell_input + b_cell
state = np.tanh(before_activation)
final_output = np.dot(state, w_output) + b_output
print ("before activation: ", before_activation)
print ("state: ", state)
print ("output: ", final_output)LSTM(long short-term memory)長短時記憶網絡:
LSTM解決了RNN不支持長期依賴的問題,使其大幅度提升記憶時長。
RNN被成功應用的關鍵就是LSTM。
LSTM是一種擁有三個“門”結構的特殊網絡結構。
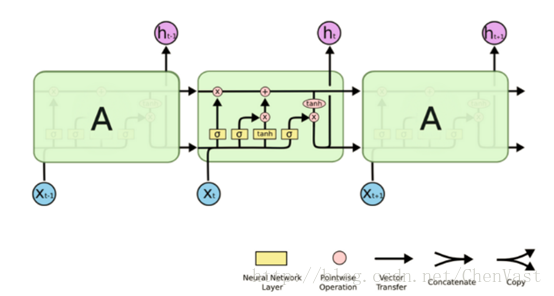
粉色的圈代表 pointwise 的操作,諸如向量的和,而黃色的矩陣就是學習到的神經網絡層。合在一起的線表示向量的連接,分開的線表示內容被復制,然后分發到不同的位置。
LSTM核心思想:
LSTM 的關鍵就是細胞狀態,水平線在圖上方貫穿運行。
細胞狀態類似于傳送帶。直接在整個鏈上運行,只有一些少量的線性交互,信息在上面流傳保持不變會很容易。
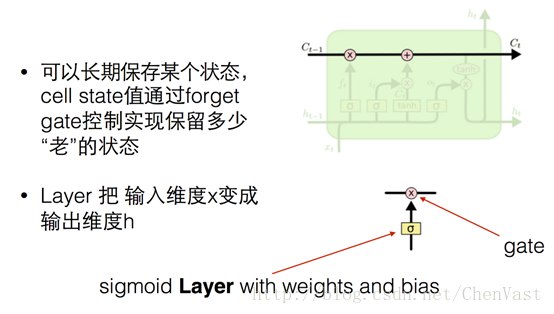
LSTM 有通過精心設計的稱作為“門”的結構來去除或者增加信息到細胞狀態的能力。
“門”是一種讓信息選擇式通過的方法,包含一個sigmoid 神經網絡層和一個 pointwise (按位做乘法)的操作。
之所以稱之為“門”,因為使用Sigmoid 作為激活函數的層會輸出 0 到 1 之間的數值,描述每個部分有多少信息量可以通過這個結構。
0 代表“不許任何量通過”,1 就指“允許任意量通過”!
LSTM的公式:
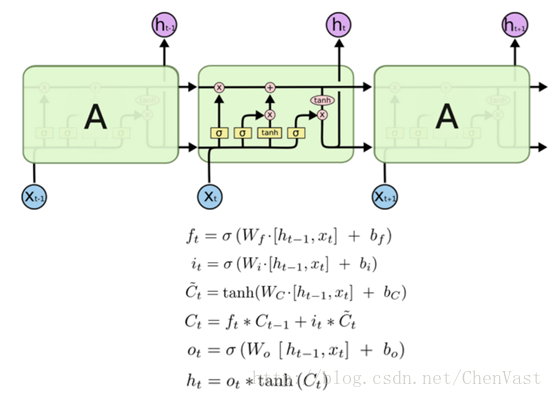
代碼實現:
import tensorflow as tf # 定義一個LSTM結構 lstm = rnn_cell.BasicLSTMCell(lstm_hidden_size) # 將LSTM中的狀態初始化為全0數組,每次使用一個batch的訓練樣本 state = lstm.zero_state(batch_size,tf.float32) # 定義損失函數 loss = 0.0 # 規定一個最大序列長度 for i in range(num_steps): # 復用之前定義的變量 if i > 0: tf.get_variable_scope().reuse_variables() # 將當前輸入和前一時刻的狀態傳入定義的LSTM結構,得到輸出和更新后的狀態 lstm_output, state = lstm(current_input,state) # 將當前時刻的LSTM結構的輸出傳入一個全連接層得到最后的輸出。 final_output = fully_connectd(lstm_output) # 計算當前時刻輸出的損失 loss += calc_loss(final_output,expected_output)
雙向循環神經網絡
經典的循環神經網絡中的狀態傳輸是從前往后單向的,然而當前時刻的輸出不僅和之前的狀態有關系,也和之后的狀態相關。
雙向循環神經網絡能解決狀態單向傳輸的問題。
雙向循環神經網絡是由兩個循環神經網絡反向上下疊加在一起組成,兩個循環神經網絡的狀態共同決定輸出。
也就是時間t時的輸出不僅僅取決于過去的記憶,也同樣取決于后面發生的事情。
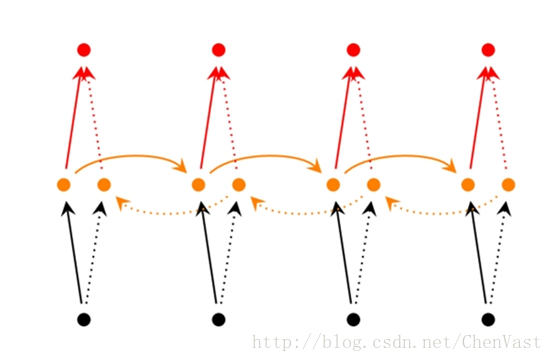
深層(雙向)循環神經網絡
深層循環神經網絡似于雙向循環神經網絡,只不過是每個時長內都有多層。
深層循環神經網絡有更強的學習能力。
深層循環神經網絡在每個時刻上將循環體結構復制多次,和卷積神經網絡類似,每一層循環體中的參數是一致的,不同層的參數可以不同。
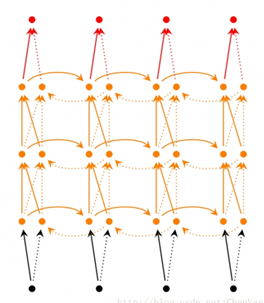
TensorFlow中使用MultiRNNCell實現深層循環神經網絡中每一個時刻的前向傳播過程。剩下的步驟和RNN的構建步驟相同。
RNN中的dropout
通過dropout方法可以上卷積神經網絡更加健壯,類似的用在RNN上也能取得同樣的效果。
類似卷積神經網絡,RNN只在最后的全連接層使用dropout。
RNN一般只在不同層循環體結構中使用dropout,不在同層循環體使用。
同一時刻t中,不同循環體之間會使用dropout。
在TensorFlow中,使用DropoutWrapper類實現dropout功能。
通過input_keep_prob參數控制輸入的dropout概率
通過output_keep_prob參數控制輸出的dropout概率
TensorFlow樣例實現RNN語言模型
代碼:
import numpy as np
import tensorflow as tf
import reader
DATA_PATH = "../datasets/PTB/data"
HIDDEN_SIZE = 200 # 隱藏層規模
NUM_LAYERS = 2 # 深層RNN中的LSTM結構的層數
VOCAB_SIZE = 10000 # 單詞標識符個數
LEARNING_RATE = 1.0 # 學習速率
TRAIN_BATCH_SIZE = 20 # 訓練數據大小
TRAIN_NUM_STEP = 35 # 訓練數據截斷長度
# 測試時不需要截斷
EVAL_BATCH_SIZE = 1 # 測試數據大小
EVAL_NUM_STEP = 1 # 測試數據截斷長度
NUM_EPOCH = 2 # 使用訓練數據輪數
KEEP_PROB = 0.5 # 節點不被dropout
MAX_GRAD_NORM = 5 # 控制梯度膨脹參數
# 定義一個類來描述模型結構。
class PTBModel (object):
def __init__(self, is_training, batch_size, num_steps):
self.batch_size = batch_size
self.num_steps = num_steps
# 定義輸入層。
self.input_data = tf.placeholder (tf.int32, [batch_size, num_steps])
self.targets = tf.placeholder (tf.int32, [batch_size, num_steps])
# 定義使用LSTM結構及訓練時使用dropout。
lstm_cell = tf.contrib.rnn.BasicLSTMCell (HIDDEN_SIZE)
if is_training:
lstm_cell = tf.contrib.rnn.DropoutWrapper (lstm_cell, output_keep_prob=KEEP_PROB)
cell = tf.contrib.rnn.MultiRNNCell ([lstm_cell] * NUM_LAYERS)
# 初始化最初的狀態。
self.initial_state = cell.zero_state (batch_size, tf.float32)
embedding = tf.get_variable ("embedding", [VOCAB_SIZE, HIDDEN_SIZE])
# 將原本單詞ID轉為單詞向量。
inputs = tf.nn.embedding_lookup (embedding, self.input_data)
if is_training:
inputs = tf.nn.dropout (inputs, KEEP_PROB)
# 定義輸出列表。
outputs = []
state = self.initial_state
with tf.variable_scope ("RNN"):
for time_step in range (num_steps):
if time_step > 0: tf.get_variable_scope ().reuse_variables ()
cell_output, state = cell (inputs[:, time_step, :], state)
outputs.append (cell_output)
output = tf.reshape (tf.concat (outputs, 1), [-1, HIDDEN_SIZE])
weight = tf.get_variable ("weight", [HIDDEN_SIZE, VOCAB_SIZE])
bias = tf.get_variable ("bias", [VOCAB_SIZE])
logits = tf.matmul (output, weight) + bias
# 定義交叉熵損失函數和平均損失。
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example (
[logits],
[tf.reshape (self.targets, [-1])],
[tf.ones ([batch_size * num_steps], dtype=tf.float32)])
self.cost = tf.reduce_sum (loss) / batch_size
self.final_state = state
# 只在訓練模型時定義反向傳播操作。
if not is_training: return
trainable_variables = tf.trainable_variables ()
# 控制梯度大小,定義優化方法和訓練步驟。
grads, _ = tf.clip_by_global_norm (tf.gradients (self.cost, trainable_variables), MAX_GRAD_NORM)
optimizer = tf.train.GradientDescentOptimizer (LEARNING_RATE)
self.train_op = optimizer.apply_gradients (zip (grads, trainable_variables))
# 使用給定的模型model在數據data上運行train_op并返回在全部數據上的perplexity值
def run_epoch(session, model, data, train_op, output_log, epoch_size):
total_costs = 0.0
iters = 0
state = session.run(model.initial_state)
# 訓練一個epoch。
for step in range(epoch_size):
x, y = session.run(data)
cost, state, _ = session.run([model.cost, model.final_state, train_op],
{model.input_data: x, model.targets: y, model.initial_state: state})
total_costs += cost
iters += model.num_steps
if output_log and step % 100 == 0:
print("After %d steps, perplexity is %.3f" % (step, np.exp(total_costs / iters)))
return np.exp(total_costs / iters)
# 定義主函數并執行
def main():
train_data, valid_data, test_data, _ = reader.ptb_raw_data(DATA_PATH)
# 計算一個epoch需要訓練的次數
train_data_len = len(train_data)
train_batch_len = train_data_len // TRAIN_BATCH_SIZE
train_epoch_size = (train_batch_len - 1) // TRAIN_NUM_STEP
valid_data_len = len(valid_data)
valid_batch_len = valid_data_len // EVAL_BATCH_SIZE
valid_epoch_size = (valid_batch_len - 1) // EVAL_NUM_STEP
test_data_len = len(test_data)
test_batch_len = test_data_len // EVAL_BATCH_SIZE
test_epoch_size = (test_batch_len - 1) // EVAL_NUM_STEP
initializer = tf.random_uniform_initializer(-0.05, 0.05)
with tf.variable_scope("language_model", reuse=None, initializer=initializer):
train_model = PTBModel(True, TRAIN_BATCH_SIZE, TRAIN_NUM_STEP)
with tf.variable_scope("language_model", reuse=True, initializer=initializer):
eval_model = PTBModel(False, EVAL_BATCH_SIZE, EVAL_NUM_STEP)
# 訓練模型。
with tf.Session() as session:
tf.global_variables_initializer().run()
train_queue = reader.ptb_producer(train_data, train_model.batch_size, train_model.num_steps)
eval_queue = reader.ptb_producer(valid_data, eval_model.batch_size, eval_model.num_steps)
test_queue = reader.ptb_producer(test_data, eval_model.batch_size, eval_model.num_steps)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=session, coord=coord)
for i in range(NUM_EPOCH):
print("In iteration: %d" % (i + 1))
run_epoch(session, train_model, train_queue, train_model.train_op, True, train_epoch_size)
valid_perplexity = run_epoch(session, eval_model, eval_queue, tf.no_op(), False, valid_epoch_size)
print("Epoch: %d Validation Perplexity: %.3f" % (i + 1, valid_perplexity))
test_perplexity = run_epoch(session, eval_model, test_queue, tf.no_op(), False, test_epoch_size)
print("Test Perplexity: %.3f" % test_perplexity)
coord.request_stop()
coord.join(threads)
if __name__ == "__main__":
main()感謝各位的閱讀!關于“TensorFlow如何實現RNN循環”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





