溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何基于TensorFlow實現CNN-RNN中文文本分類,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
基于TensorFlow在中文數據集上的簡化實現,使用了字符級CNN和RNN對中文文本進行分類,達到了較好的效果。
使用THUCNews的一個子集進行訓練與測試,數據集請自行到THUCTC:一個高效的中文文本分類工具包
本次訓練使用了其中的10個分類,每個分類6500條數據。
類別如下:
體育, 財經, 房產, 家居, 教育, 科技, 時尚, 時政, 游戲, 娛樂
數據集劃分如下:
訓練集: 5000*10
驗證集: 500*10
測試集: 1000*10
從原數據集生成子集的過程請參看helper下的兩個腳本。其中,copy_data.sh用于從每個分類拷貝6500個文件,cnews_group.py用于將多個文件整合到一個文件中。執行該文件后,得到三個數據文件:
cnews.train.txt: 訓練集(50000條)
cnews.val.txt: 驗證集(5000條)
cnews.test.txt: 測試集(10000條)
data/cnews_loader.py為數據的預處理文件。
read_file(): 讀取文件數據;
build_vocab(): 構建詞匯表,使用字符級的表示,這一函數會將詞匯表存儲下來,避免每一次重復處理;
read_vocab(): 讀取上一步存儲的詞匯表,轉換為{詞:id}表示;
read_category(): 將分類目錄固定,轉換為{類別: id}表示;
to_words(): 將一條由id表示的數據重新轉換為文字;
process_file(): 將數據集從文字轉換為固定長度的id序列表示;
batch_iter(): 為神經網絡的訓練準備經過shuffle的批次的數據。
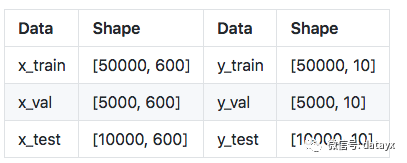
經過數據預處理,數據的格式如下:
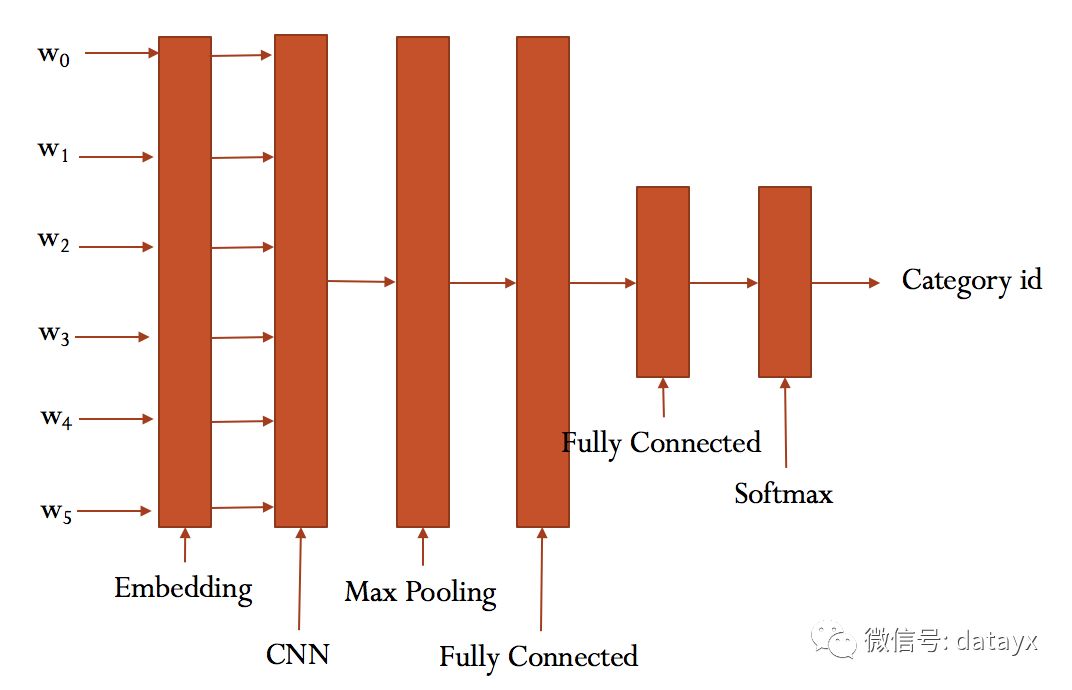
具體參看cnn_model.py的實現。
大致結構如下:
運行 python run_cnn.py train,可以開始訓練。
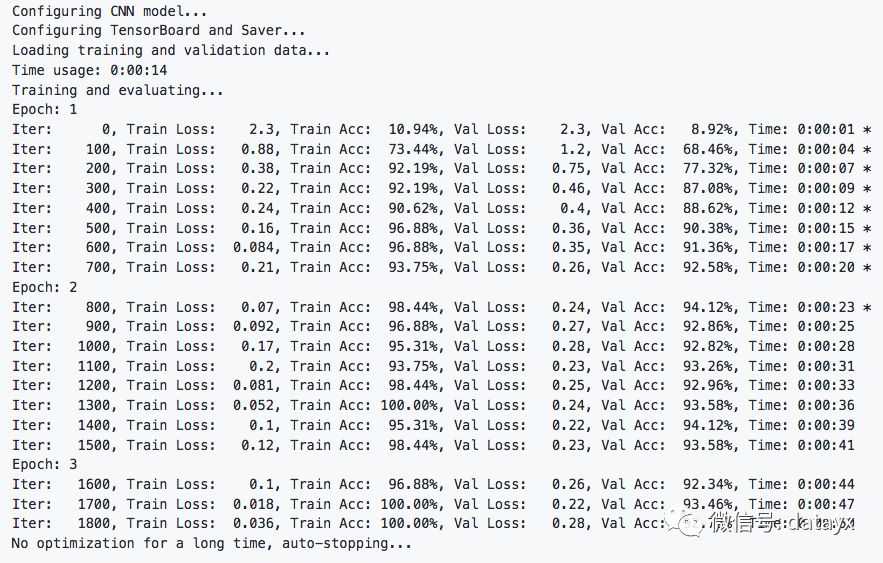
在驗證集上的最佳效果為94.12%,且只經過了3輪迭代就已經停止。
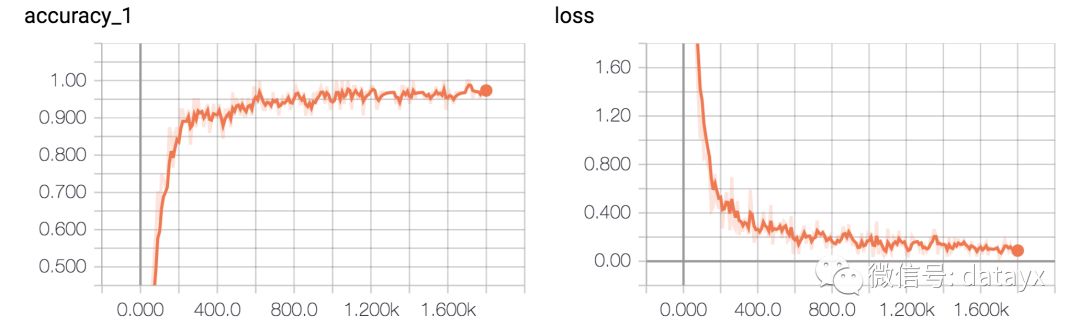
準確率和誤差如圖所示:
運行 python run_cnn.py test 在測試集上進行測試。
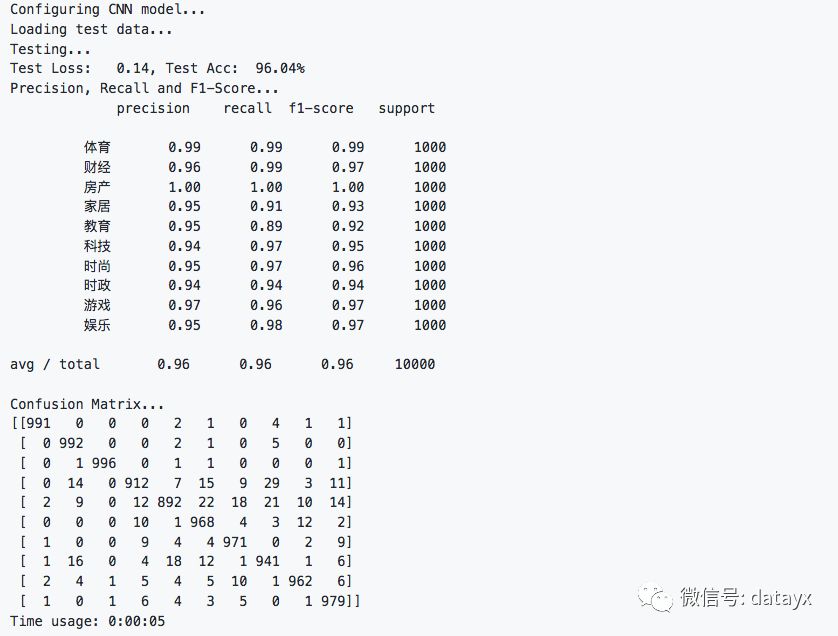
在測試集上的準確率達到了96.04%,且各類的precision, recall和f1-score都超過了0.9。
從混淆矩陣也可以看出分類效果非常優秀。
RNN可配置的參數如下所示,在rnn_model.py中。

具體參看rnn_model.py的實現。
大致結構如下:
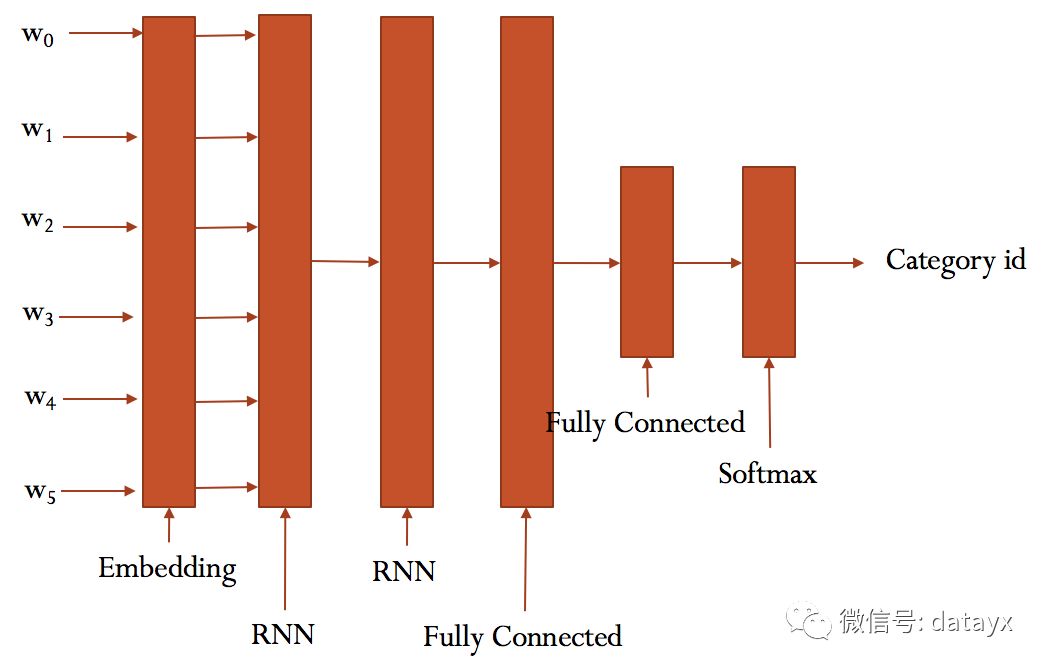
這部分的代碼與 run_cnn.py極為相似,只需要將模型和部分目錄稍微修改。
運行 python run_rnn.py train,可以開始訓練。
若之前進行過訓練,請把tensorboard/textrnn刪除,避免TensorBoard多次訓練結果重疊。
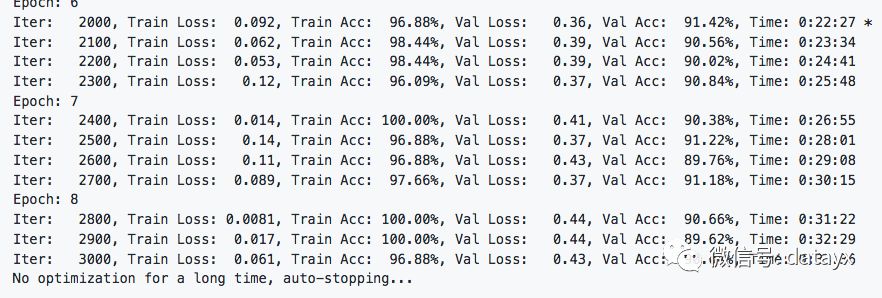
在驗證集上的最佳效果為91.42%,經過了8輪迭代停止,速度相比CNN慢很多。
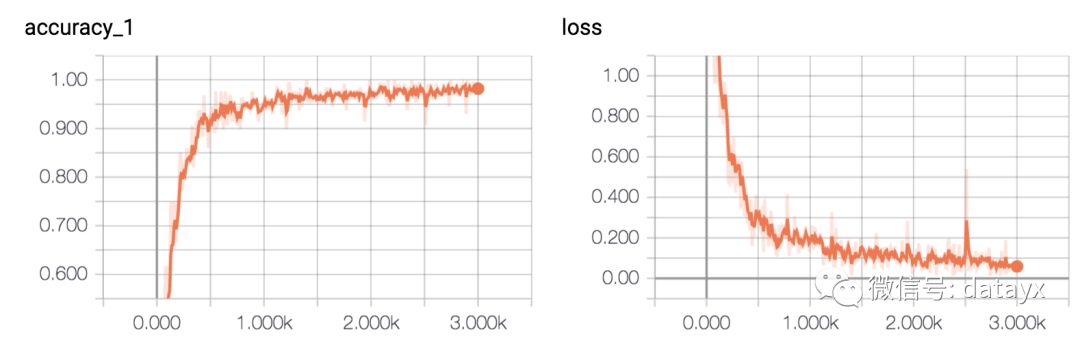
準確率和誤差如圖所示:
運行 python run_rnn.py test 在測試集上進行測試。
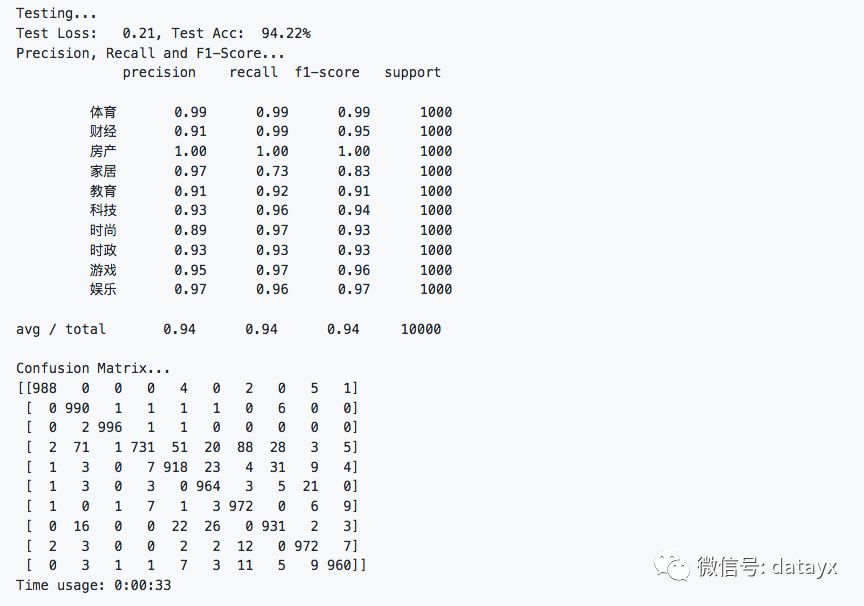
在測試集上的準確率達到了94.22%,且各類的precision, recall和f1-score,除了家居這一類別,都超過了0.9。
從混淆矩陣可以看出分類效果非常優秀。
對比兩個模型,可見RNN除了在家居分類的表現不是很理想,其他幾個類別較CNN差別不大。
還可以通過進一步的調節參數,來達到更好的效果。
為方便預測,repo 中 predict.py 提供了 CNN 模型的預測方法。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





