溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
正則表達式又稱正規表達式、常規表達式。正則表達式是由普通字符與元字符組成的文字模式。模式用于描述在搜索文本時要匹配的一個或多個字符串。正則表達式一般用于腳本編程與文本編輯器中。很多文本處理器與程序設計語言均支持正則表達式,在Linux 系統中常見的文本處理器如grep、egrep、sed、awk。正則表達式具備很強大的文本匹配功能,能夠在文本海洋中快速高效地處理文本。
正則表達式對于系統管理員來說是非常重要的,系統運行過程中會產生大量的信息,這些信息有些是非常重要的,有些則僅是告知的信息。身為系統管理員如果直接看這么多的信息數據,無法快速定位到重要的信息,如“用戶賬號登錄失敗”“服務啟動失敗”等信息。這時可以通過正則表達式快速提取“有問題”的信息。如此一來,可以將運維工作變得更加簡單、方便。
正則表達式的字符串表達方法根據不同的嚴謹程度與功能分為基本正則表達式與擴展正則表達式。基礎正則表達式是常用的正則表達式的最基礎的部分。
1.查找特定字符
-n 表示顯示行號
-i 表示不區分大小寫
(符合匹配標準的字符,字體顏色會變為紅色)
(1)查找出特定字符“the” 所在位置
[root@localhost ~]# grep -n 'the' /opt/httpd.conf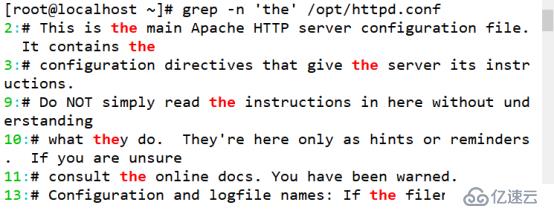
(2)反向查找不包含“the”字符的行
[root@localhost~]# grep -vn 'the' /opt/httpd.conf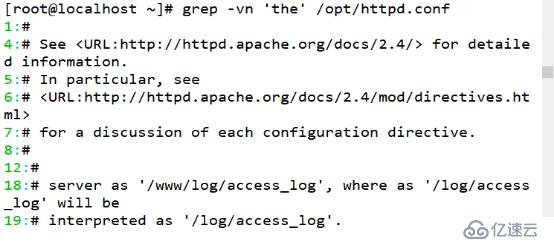
2.利用中括號“[ ]”來查找集合字符
(1)查找“shirt”與“short”這兩個字符串,“[]”中無論有幾個字符,都僅代表一個字符,也就是說“[io]”表示匹配“i”或者“o”。
[root@localhost ~]# grep -n 'sh[io]rt' /opt/httpd.conf
(2)查找重復單個單詞字符
[root@localhost ~]# grep -n 'oo' /opt/httpd.conf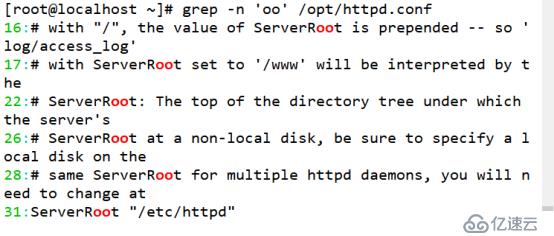
(3)通過集合字符的反向選擇“[^]”來實現查找“oo”前面不是“R”的字符串
[root@localhost ~]# grep -n '[^R]oo' /opt/httpd.conf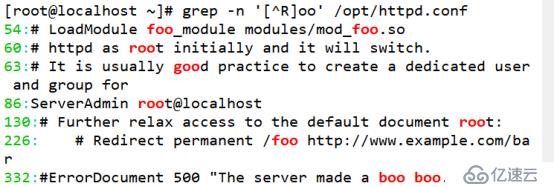
(4)查找“oo”前面存在小寫或大寫字母,其中“a-z”表示小寫字母,“A-Z”表示大寫字母
[root@localhost ~]# grep -n '[^a-z]oo' /opt/httpd.conf //小寫字母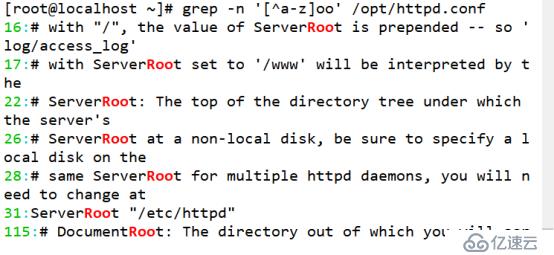
[root@localhost ~]# grep -n '[^A-Z]oo' /opt/httpd.conf //大寫字母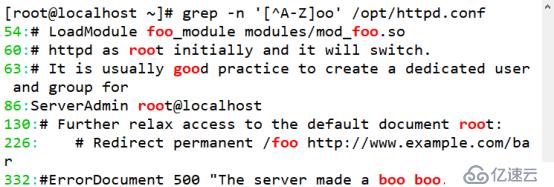
(5)查找包含數字的行
[root@localhost ~]# grep -n '[0-9]' /opt/httpd.conf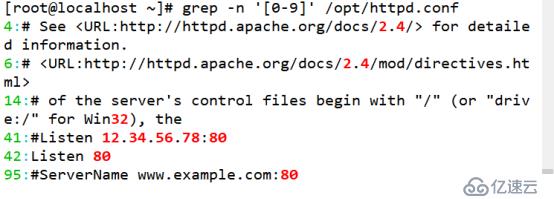
3.查找行首“^”與行尾字符“$”
(1)查找以root開頭的行
[root@localhost ~]# grep -n '^root' /etc/passwd
(2)查找以bash結尾的行
[root@localhost ~]# grep -n 'bash$' /etc/passwd
(3)查詢以小寫或大寫字母開頭的行
小寫字母開頭的行可以通過“^[a-z]”規則來過濾,查詢大寫字母開頭的行使用“^[A-Z]”規則,查詢不以字母開頭的行使用“^[^a-zA-Z]”規則。
[root@localhost ~]# grep -n '^[a-z]' /etc/passwd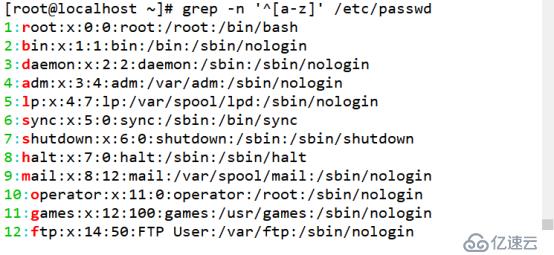
(4)查詢以問號?結尾的行,需要使用轉義字符“\”將具有特 殊意義的字符轉化成普通字符
[root@localhost ~]# grep -n '\?$' /opt/httpd.conf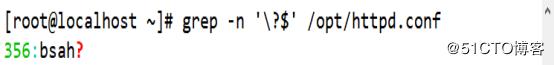
(5)查詢一空白行,使用^$
[root@localhost ~]# grep -n '^$' /opt/httpd.conf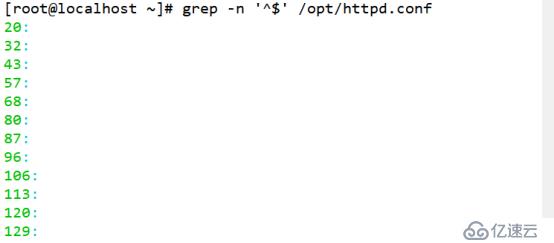
4.查找任意一個字符“.”與重復字符“*”
(1)查找以w開頭d結尾的字符串
[root@localhost ~]# grep -n 'w..d' /opt/httpd.conf
(2)查詢包含至少兩個 o 以上的字符串,可用星號元字符. 代表的是重復零個或多個前面的單字符,所以凡是包含 o、oo、ooo、ooo,等的資料都符合標準。
[root@localhost ~]# grep -n 'ooo*' test.txt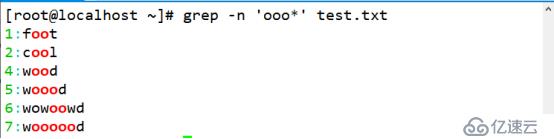
(3)查詢以 w 開頭 d 結尾,其中間包含至少一個 o 的字符串
[root@localhost ~]# grep -n 'woo*d' test.txt
(4)查詢以 w 開頭 d 結尾,中間的字符可有可無的字符串。
[root@localhost ~]# grep -n 'w.*d' test.txt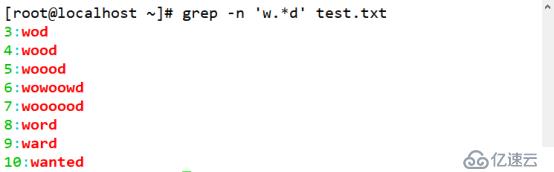
(5)查詢任意數字所在行
[root@localhost ~]# grep -n '[0-9][0-9]*' /opt/httpd.conf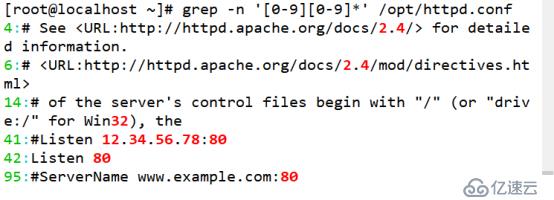
5.查找連續字符范圍{ }
在使用“{}”字符時,需要利用轉義字符“\”,將“{}”字符轉換成普通字符。
(1)查詢兩個o的字符
[root@localhost ~]# grep -n 'o\{2\}' test.txt
(2)查詢以 w 開頭以 d 結尾,中間包含 2~3個 o 的字符串
root@localhost ~]# grep -n 'wo\{2,\}d' test.txt
(3)查詢以 w 開頭以 d 結尾,中間包含 2 以上 o 的字符串
[root@localhost ~]# grep -n 'wo\{2,\}d' test.txt
| 元字符 | 作用 |
|---|---|
| ^ | 匹配輸入字符串的開始位置。在方括號表達式中使用,表示不包含該字符集合。 |
| $ | 匹配輸入字符串的結尾位置。 |
| . | 匹配除“\r\n”之外的任何單個字符 |
| \ | 將下一個字符標記為特殊字符、原義字符、向后引用、八進制轉義符。 |
| * | 匹配前面的子表達式零次或多次。要匹配“”字符,請使用“\” |
| [ ] | 字符集合。匹配所包含的任意一個字符。例如,“[abc]”可以匹配“plain”中的“a” |
| ^ ] | 賦值字符集合。匹配未包含的一個任意字符。 |
| [n1-n2] | 字符范圍。匹配指定范圍內的任意一個字符。 |
| {n} | n 是一個非負整數,匹配確定的 n 次 |
| {n,} | n 是一個非負整數,至少匹配 n 次。 |
| n,m | m 和n 均為非負整數,其中 n<=m,最少匹配 n 次且最多匹配 m 次 |
通常情況下會使用基礎正則表達式就已經足夠了,但有時為了簡化整個指令,需要使用范圍更廣的擴展正則表達式。此外grep 命令僅支持基礎正則表達式,如果使用擴展正則表達式,需要使用 egrep 命令。egrep 命令與 grep 命令的用法基本相似。egrep 命令是一個搜索文件獲得模式,使用該命令可以搜索文件中的任意字符串和符號,也可以搜索一個或多個文件的字符串,一個提示符可以是單個字符、一個字符串、一個字或一個句子。
| 元字符 | 作用 |
|---|---|
| + | 重復一個或者一個以上的前一個字符 |
| ? | 零個或者一個的前一個字符 |
| l | 使用或者(or)的方式找出多個字符 |
| () | 查找“組”字符串 |
| ()+ | 辨別多個重復的組 |
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





