溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關怎么在Tensorflow中通過tfrecord方式讀取數據,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
1. tfrecord格式簡介
這部分主要參考了另一篇博文,Tensorflow 訓練自己的數據集(二)(TFRecord)
tfecord文件中的數據是通過tf.train.Example Protocol Buffer的格式存儲的,下面是tf.train.Example的定義
message Example {
Features features = 1;
};
message Features{
map<string,Feature> featrue = 1;
};
message Feature{
oneof kind{
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};從上述代碼可以看出,tf.train.Example 的數據結構很簡單。tf.train.Example中包含了一個從屬性名稱到取值的字典,其中屬性名稱為一個字符串,屬性的取值可以為字符串(BytesList ),浮點數列表(FloatList )或整數列表(Int64List )。例如我們可以將圖片轉換為字符串進行存儲,圖像對應的類別標號作為整數存儲,而用于回歸任務的ground-truth可以作為浮點數存儲。通過后面的代碼我們會對tfrecord的這種字典形式有更直觀的認識。
2. 利用自己的數據生成tfrecord文件
先上一段代碼,然后我再針對代碼進行相關介紹。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from scipy import misc
import scipy.io as sio
def _bytes_feature(value):
return tf.train.Feature(bytes_list = tf.train.BytesList(value=[value]))
def _int64_feature(value):
return tf.train.Feature(int64_list = tf.train.Int64List(value=[value]))
root_path = '/mount/temp/WZG/Multitask/Data/'
tfrecords_filename = root_path + 'tfrecords/train.tfrecords'
writer = tf.python_io.TFRecordWriter(tfrecords_filename)
height = 300
width = 300
meanfile = sio.loadmat(root_path + 'mats/mean300.mat')
meanvalue = meanfile['mean']
txtfile = root_path + 'txt/train.txt'
fr = open(txtfile)
for i in fr.readlines():
item = i.split()
img = np.float64(misc.imread(root_path + '/images/train_images/' + item[0]))
img = img - meanvalue
maskmat = sio.loadmat(root_path + '/mats/train_mats/' + item[1])
mask = np.float64(maskmat['seg_mask'])
label = int(item[2])
img_raw = img.tostring()
mask_raw = mask.tostring()
example = tf.train.Example(features=tf.train.Features(feature={
'height': _int64_feature(height),
'width': _int64_feature(width),
'name': _bytes_feature(item[0]),
'image_raw': _bytes_feature(img_raw),
'mask_raw': _bytes_feature(mask_raw),
'label': _int64_feature(label)}))
writer.write(example.SerializeToString())
writer.close()
fr.close()代碼中前兩個函數(_bytes_feature和_int64_feature)是將我們的原生數據進行轉換用的,尤其是圖片要轉換成字符串再進行存儲。這兩個函數的定義來自官方的示例。
接下來,我定義了數據的(路徑-label文件)txtfile,它大概長這個樣子:
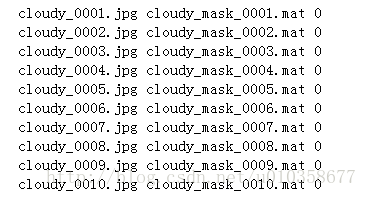
這里稍微啰嗦下,介紹一下我的實驗內容。我做的是一個multi-task的實驗,一支task做分割,一支task做分類。所以txtfile中每一行是一個樣本,每個樣本又包含3項,第一項為圖片名稱,第二項為相應的ground-truth segmentation mask的名稱,第三項是圖片的標簽。(txtfile中內容形式無所謂,只要能讀到想讀的數據就可以)
接著回到主題繼續講代碼,之后我又定義了即將生成的tfrecord的文件路徑和名稱,即tfrecord_filename,還有一個writer,這個writer是進行寫操作用的。
接下來是圖片的高度、寬度以及我事先在整個數據集上計算好的圖像均值文件。高度、寬度其實完全沒必要引入,這里只是為了說明tfrecord的生成而寫的。而均值文件是為了對圖像進行事先的去均值化操作而引入的,在大多數機器學習任務中,圖像去均值化對提高算法的性能還是很有幫助的。
最后就是根據txtfile中的每一行進行相關數據的讀取、轉換以及tfrecord的生成了。首先是根據圖片路徑讀取圖片內容,然后圖像減去之前讀入的均值,接著根據segmentation mask的路徑讀取mask(如果只是圖像分類任務,那么就不會有這些額外的mask),txtfile中的label讀出來是string格式,這里要轉換成int。然后圖像和mask數據也要用相應的tosring函數轉換成string。
真正的核心是下面這一小段代碼:
example = tf.train.Example(features=tf.train.Features(feature={
'height': _int64_feature(height),
'width': _int64_feature(width),
'name': _bytes_feature(item[0]),
'image_raw': _bytes_feature(img_raw),
'mask_raw': _bytes_feature(mask_raw),
'label': _int64_feature(label)}))
writer.write(example.SerializeToString())這里很好地體現了tfrecord的字典特性,tfrecord中每一個樣本都是一個小字典,這個字典可以包含任意多個鍵值對。比如我這里就存儲了圖片的高度、寬度、圖片名稱、圖片內容、mask內容以及圖片的label。對于我的任務來說,其實height、width、name都不是必需的,這里僅僅是為了展示。鍵值對的鍵全都是字符串,鍵起什么名字都可以,只要能方便以后使用就可以。
定義好一個example后就可以用之前的writer來把它真正寫入tfrecord文件了,這其實就跟把一行內容寫入一個txt文件一樣。代碼的最后就是writer和txt文件對象的關閉了。
最后在指定文件夾下,就得到了指定名字的tfrecord文件,如下所示:
需要注意的是,生成的tfrecord文件比原生數據的大小還要大,這是正常現象。這種現象可能是因為圖片一般都存儲為jpg等壓縮格式,而tfrecord文件存儲的是解壓后的數據。
3. 從tfrecord文件讀取數據
還是代碼先行。
from scipy import misc
import tensorflow as tf
import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt
root_path = '/mount/temp/WZG/Multitask/Data/'
tfrecord_filename = root_path + 'tfrecords/test.tfrecords'
def read_and_decode(filename_queue, random_crop=False, random_clip=False, shuffle_batch=True):
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'height': tf.FixedLenFeature([], tf.int64),
'width': tf.FixedLenFeature([], tf.int64),
'name': tf.FixedLenFeature([], tf.string),
'image_raw': tf.FixedLenFeature([], tf.string),
'mask_raw': tf.FixedLenFeature([], tf.string),
'label': tf.FixedLenFeature([], tf.int64)
})
image = tf.decode_raw(features['image_raw'], tf.float64)
image = tf.reshape(image, [300,300,3])
mask = tf.decode_raw(features['mask_raw'], tf.float64)
mask = tf.reshape(mask, [300,300])
name = features['name']
label = features['label']
width = features['width']
height = features['height']
# if random_crop:
# image = tf.random_crop(image, [227, 227, 3])
# else:
# image = tf.image.resize_image_with_crop_or_pad(image, 227, 227)
# if random_clip:
# image = tf.image.random_flip_left_right(image)
if shuffle_batch:
images, masks, names, labels, widths, heights = tf.train.shuffle_batch([image, mask, name, label, width, height],
batch_size=4,
capacity=8000,
num_threads=4,
min_after_dequeue=2000)
else:
images, masks, names, labels, widths, heights = tf.train.batch([image, mask, name, label, width, height],
batch_size=4,
capacity=8000,
num_threads=4)
return images, masks, names, labels, widths, heights讀取tfrecord文件中的數據主要是應用read_and_decode()這個函數,可以看到其中有個參數是filename_queue,其實我們并不是直接從tfrecord文件進行讀取,而是要先利用tfrecord文件創建一個輸入隊列,如本文開頭所述那樣。關于這點,到后面真正的測試代碼我再介紹。
在read_and_decode()中,一上來我們先定義一個reader對象,然后使用reader得到serialized_example,這是一個序列化的對象,接著使用tf.parse_single_example()函數對此對象進行初步解析。從代碼中可以看到,解析時,我們要用到之前定義的那些鍵。對于圖像、mask這種轉換成字符串的數據,要進一步使用tf.decode_raw()函數進行解析,這里要特別注意函數里的第二個參數,也就是解析后的類型。之前圖片在轉成字符串之前是什么類型的數據,那么這里的參數就要填成對應的類型,否則會報錯。對于name、label、width、height這樣的數據就不用再解析了,我們得到的features對象就是個字典,利用鍵就可以拿到對應的值,如代碼所示。
我注釋掉的部分是用來做數據增強的,比如隨機的裁剪與翻轉,除了這兩種,其他形式的數據增強也可以寫在這里,讀者可以根據自己的需要,決定是否使用各種數據增強方式。
函數最后就是使用解析出來的數據生成batch了。Tensorflow提供了兩種方式,一種是shuffle_batch,這種主要是用在訓練中,隨機選取樣本組成batch。另外一種就是按照數據在tfrecord中的先后順序生成batch。對于生成batch的函數,建議讀者去官網查看API文檔進行細致了解。這里稍微做一下介紹,batch的大小,即batch_size就需要在生成batch的函數里指定。另外,capacity參數指定數據隊列一次性能放多少個樣本,此參數設置什么值需要視硬件環境而定。num_threads參數指定可以開啟幾個線程來向數據隊列中填充數據,如果硬件性能不夠強,最好設小一點,否則容易崩。
4. 實例測試
實際使用時先指定好我們需要使用的tfrecord文件:
root_path = '/mount/temp/WZG/Multitask/Data/' tfrecord_filename = root_path + 'tfrecords/test.tfrecords'
然后用該tfrecord文件創建一個輸入隊列:
filename_queue = tf.train.string_input_producer([tfrecord_filename], num_epochs=3)
這里有個參數是num_epochs,指定好之后,Tensorflow自然知道如何讀取數據,保證在遍歷數據集的一個epoch中樣本不會重復,也知道數據讀取何時應該停止。
下面我將完整的測試代碼貼出:
def test_run(tfrecord_filename): filename_queue = tf.train.string_input_producer([tfrecord_filename], num_epochs=3) images, masks, names, labels, widths, heights = read_and_decode(filename_queue) init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) meanfile = sio.loadmat(root_path + 'mats/mean300.mat') meanvalue = meanfile['mean'] with tf.Session() as sess: sess.run(init_op) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(coord=coord) for i in range(1): imgs, msks, nms, labs, wids, heis = sess.run([images, masks, names, labels, widths, heights]) print 'batch' + str(i) + ': ' #print type(imgs[0]) for j in range(4): print nms[j] + ': ' + str(labs[j]) + ' ' + str(wids[j]) + ' ' + str(heis[j]) img = np.uint8(imgs[j] + meanvalue) msk = np.uint8(msks[j]) plt.subplot(4,2,j*2+1) plt.imshow(img) plt.subplot(4,2,j*2+2) plt.imshow(msk, vmin=0, vmax=5) plt.show() coord.request_stop() coord.join(threads)
函數中接下來就是利用之前定義的read_and_decode()來得到一個batch的數據,此后我又讀入了均值文件,這是因為之前做了去均值處理,如果要正常顯示圖片需要再把均值加回來。
再之后就是建立一個Tensorflow session,然后初始化對象。這些是Tensorflow基本操作,不再贅述。下面的這兩句代碼非常重要,是讀取數據必不可少的。
coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(coord=coord)
然后是運行sess.run()拿到實際數據,之前只是相當于定義好了,并沒有得到真實數值。
關于怎么在Tensorflow中通過tfrecord方式讀取數據就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





