溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了如何利用Tensorflow的隊列多線程讀取數據,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
在tensorflow中,有三種方式輸入數據
1. 利用feed_dict送入numpy數組
2. 利用隊列從文件中直接讀取數據
3. 預加載數據
其中第一種方式很常用,在tensorflow的MNIST訓練源碼中可以看到,通過feed_dict={},可以將任意數據送入tensor中。
第二種方式相比于第一種,速度更快,可以利用多線程的優勢把數據送入隊列,再以batch的方式出隊,并且在這個過程中可以很方便地對圖像進行隨機裁剪、翻轉、改變對比度等預處理,同時可以選擇是否對數據隨機打亂,可以說是非常方便。該部分的源碼在tensorflow官方的CIFAR-10訓練源碼中可以看到,但是對于剛學習tensorflow的人來說,比較難以理解,本篇博客就當成我調試完成后寫的一篇總結,以防自己再忘記具體細節。
讀取CIFAR-10數據集
按照第一種方式的話,CIFAR-10的讀取只需要寫一段非常簡單的代碼即可將測試集與訓練集中的圖像分別讀取:
path = 'E:\Dataset\cifar-10\cifar-10-batches-py' # extract train examples num_train_examples = 50000 x_train = np.empty((num_train_examples, 32, 32, 3), dtype='uint8') y_train = np.empty((num_train_examples), dtype='uint8') for i in range(1, 6): fpath = os.path.join(path, 'data_batch_' + str(i)) (x_train[(i - 1) * 10000: i * 10000, :, :, :], y_train[(i - 1) * 10000: i * 10000]) = load_and_decode(fpath) # extract test examples fpath = os.path.join(path, 'test_batch') x_test, y_test = load_and_decode(fpath) return x_train, y_train, x_test, np.array(y_test)
其中load_and_decode函數只需要按照CIFAR-10官網給出的方式decode就行,最終返回的x_train是一個[50000, 32, 32, 3]的ndarray,但對于ndarray來說,進行預處理就要麻煩很多,為了取mini-SGD的batch,還自己寫了一個類,通過調用train_set.next_batch()函數來取,總而言之就是什么都要自己動手,效率確實不高
但對于第二種方式,讀取起來就要麻煩很多,但使用起來,又快又方便
首先,把CIFAR-10的測試集文件讀取出來,生成文件名列表
path = 'E:\Dataset\cifar-10\cifar-10-batches-py' filenames = [os.path.join(path, 'data_batch_%d' % i) for i in range(1, 6)]
有了列表以后,利用tf.train.string_input_producer函數生成一個讀取隊列
filename_queue = tf.train.string_input_producer(filenames)
接下來,我們調用read_cifar10函數,得到一幅一幅的圖像,該函數的代碼如下:
def read_cifar10(filename_queue): label_bytes = 1 IMAGE_SIZE = 32 CHANNELS = 3 image_bytes = IMAGE_SIZE*IMAGE_SIZE*3 record_bytes = label_bytes+image_bytes # define a reader reader = tf.FixedLengthRecordReader(record_bytes) key, value = reader.read(filename_queue) record_bytes = tf.decode_raw(value, tf.uint8) label = tf.strided_slice(record_bytes, [0], [label_bytes]) depth_major = tf.reshape(tf.strided_slice(record_bytes, [label_bytes], [label_bytes + image_bytes]), [CHANNELS, IMAGE_SIZE, IMAGE_SIZE]) image = tf.transpose(depth_major, [1, 2, 0]) return image, label
第9行,定義一個reader,來讀取固定長度的數據,這個固定長度是由CIFAR-10數據集圖片的存儲格式決定的,1byte的標簽加上32 *32 *3長度的圖像,3代表RGB三通道,由于圖片的是按[channel, height, width]的格式存儲的,為了變為常用的[height, width, channel]維度,需要在17行reshape一次圖像,最終我們提取出了一副完整的圖像與對應的標簽
對圖像進行預處理
我們取出的image與label均為tensor格式,因此預處理將變得非常簡單
if not distortion: IMAGE_SIZE = 32 else: IMAGE_SIZE = 24 # 隨機裁剪為24*24大小 distorted_image = tf.random_crop(tf.cast(image, tf.float32), [IMAGE_SIZE, IMAGE_SIZE, 3]) # 隨機水平翻轉 distorted_image = tf.image.random_flip_left_right(distorted_image) # 隨機調整亮度 distorted_image = tf.image.random_brightness(distorted_image, max_delta=63) # 隨機調整對比度 distorted_image = tf.image.random_contrast(distorted_image, lower=0.2, upper=1.8) # 對圖像進行白化操作,即像素值轉為零均值單位方差 float_image = tf.image.per_image_standardization(distorted_image)
distortion是定義的一個輸入布爾型變量,默認為True,表示是否對圖像進行處理
填充隊列與隨機打亂
調用tf.train.shuffle_batch或tf.train.batch函數,以tf.train.shuffle_batch為例,函數的定義如下:
def shuffle_batch(tensors, batch_size, capacity, min_after_dequeue, num_threads=1, seed=None, enqueue_many=False, shapes=None, allow_smaller_final_batch=False, shared_name=None, name=None):
tensors表示輸入的張量(tensor),batch_size表示要輸出的batch的大小,capacity表示隊列的容量,即大小,min_after_dequeue表示出隊操作后隊列中的最小元素數量,這個值是要小于隊列的capacity的,通過調整min_after_dequeue與capacity兩個變量,可以改變數據被隨機打亂的程度,num_threads表示使用的線程數,只要取大于1的數,隊列的效率就會高很多。
通常情況下,我們只需要輸入以上幾個變量即可,在CIFAR-10_input.py中,谷歌給出的代碼是這樣寫的:
if shuffle: images, label_batch = tf.train.shuffle_batch([image, label], batch_size, min_queue_examples+3*batch_size, min_queue_examples, num_preprocess_threads) else: images, label_batch = tf.train.batch([image, label], batch_size, num_preprocess_threads, min_queue_examples + 3 * batch_size)
min_queue_examples由以下方式得到:
min_fraction_of_examples_in_queue = 0.4 min_queue_examples = int(NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN *min_fraction_of_examples_in_queue)
當然,這些值均可以自己隨意設置,
最終得到的images,labels(label_batch),即為shape=[128, 32, 32, 3]的tensor,其中128為默認batch_size。
激活隊列與處理異常
得到了images和labels兩個tensor后,我們便可以把這兩個tensor送入graph中進行運算了
# input tensor img_batch, label_batch = cifar10_input.tesnsor_shuffle_input(batch_size) # build graph that computes the logits predictions from the inference model logits, predicts = train.inference(img_batch, keep_prob) # calculate loss loss = train.loss(logits, label_batch)
定義sess=tf.Session()后,運行sess.run(),然而你會發現并沒有輸出,程序直接掛起了,仿佛死掉了一樣
原因是這樣的,雖然我們在數據流圖中加入了隊列,但只有調用tf.train.start_queue_runners()函數后,數據才會動起來,被負責輸入管道的線程填入隊列,否則隊列將會掛起。
OK,我們調用函數,讓隊列運行起來
with tf.Session(config=run_config) as sess: sess.run(init_op) # intialization queue_runner = tf.train.start_queue_runners(sess) for i in range(10): b1, b2 = sess.run([img_batch, label_batch]) print(b1.shape)
在這里為了測試,我們取10次輸出,看看輸出的batch2的維度是否正確
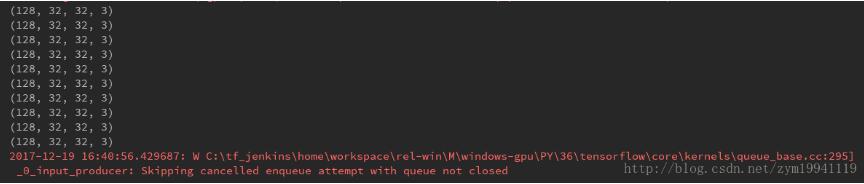
10個batch的維度均為正確的,但是tensorflow卻報了錯,錯誤的文字內容如下:
2017-12-19 16:40:56.429687: W C:\tf_jenkins\home\workspace\rel-win\M\windows-gpu\PY\36\tensorflow\core\kernels\queue_base.cc:295] _ 0 _ input_producer: Skipping cancelled enqueue attempt with queue not closed
簡單地看一下,大致意思是說我們的隊列里還有數據,但是程序結束了,拋出了異常,因此,我們還需要定義一個Coordinator,也就是協調器來處理異常
Coordinator有3個主要方法:
1. tf.train.Coordinator.should_stop() 如果線程應該停止,返回True
2. tf.train.Coordinator.request_stop() 請求停止線程
3. tf.train.Coordinator.join() 等待直到指定線程停止
首先,定義協調器
coord = tf.train.Coordinator()
將協調器應用于QueueRunner
queue_runner = tf.train.start_queue_runners(sess, coord=coord)
結束數據的訓練或測試后,關閉線程
coord.request_stop() coord.join(queue_runner)
最終的sess代碼段如下:
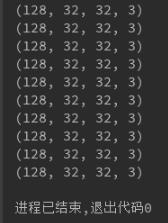
coord = tf.train.Coordinator() with tf.Session(config=run_config) as sess: sess.run(init_op) queue_runner = tf.train.start_queue_runners(sess, coord=coord) for i in range(10): b1, b2 = sess.run([img_batch, label_batch]) print(b1.shape) coord.request_stop() coord.join(queue_runner)
得到的輸出結果為:
感謝你能夠認真閱讀完這篇文章,希望小編分享的“如何利用Tensorflow的隊列多線程讀取數據”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





