溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文實例講述了Python機器學習k-近鄰算法。分享給大家供大家參考,具體如下:
存在一份訓練樣本集,并且每個樣本都有屬于自己的標簽,即我們知道每個樣本集中所屬于的類別。輸入沒有標簽的新數據后,將新數據的每個特征與樣本集中數據對應的特征進行比較,然后提取樣本集中與之最相近的k個樣本。觀察并統計這k個樣本的標簽,選擇數量最大的標簽作為這個新數據的標簽。
用以下這幅圖可以很好的解釋kNN算法:
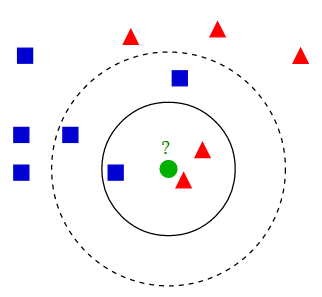
不同形狀的點,為不同標簽的點。其中綠色點為未知標簽的數據點。現在要對綠色點進行預測。由圖不難得出:
偽代碼
對未知屬性的數據集中的每個點執行以下操作
1. 計算已知類型類別數據集中的點與當前點之間的距離
2. 按照距離遞增次序排序
3. 選取與當前點距離最小的k個點
4. 確定前k個點所在類別的出現頻率
5. 返回前k個點出現頻率最高的類別作為當前點的預測分類
歐式距離(計算兩點之間的距離公式)
計算點x與點y之間歐式距離
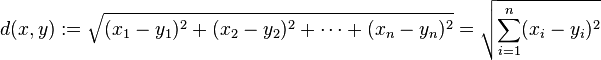
python代碼實現
# -*- coding:utf-8 -*-
#! python2
import numpy as np
import operator
# 訓練集
data_set = np.array([[1., 1.1],
[1.0, 1.0],
[0., 0.],
[0, 0.1]])
labels = ['A', 'A', 'B', 'B']
def classify_knn(in_vector, training_data, training_label, k):
"""
:param in_vector: 待分類向量
:param training_data: 訓練集向量
:param training_label: 訓練集標簽
:param k: 選擇最近鄰居的數目
:return: 分類器對 in_vector 分類的類別
"""
data_size = training_data.shape[0] # .shape[0] 返回二維數組的行數
diff_mat = np.tile(in_vector, (data_size, 1)) - data_set # np.tile(array, (3, 2)) 對 array 進行 3×2 擴展為二維數組
sq_diff_mat = diff_mat ** 2
sq_distances = sq_diff_mat.sum(axis=1) # .sum(axis=1) 矩陣以列求和
# distances = sq_distances ** 0.5 # 主要是通過比較求最近點,所以沒有必要求平方根
distances_sorted_index = sq_distances.argsort() # .argsort() 對array進行排序 返回排序后對應的索引
class_count_dict = {} # 用于統計類別的個數
for i in range(k):
label = training_label[distances_sorted_index[i]]
try:
class_count_dict[label] += 1
except KeyError:
class_count_dict[label] = 1
class_count_dict = sorted(class_count_dict.iteritems(), key=operator.itemgetter(1), reverse=True) # 根據字典的value值對字典進行逆序排序
return class_count_dict[0][0]
if __name__ == '__main__':
vector = [0, 0] # 待分類數據集
print classify_knn(in_vector=vector, training_data=data_set, training_label=labels, k=3)
運行結果:B
更多關于Python相關內容感興趣的讀者可查看本站專題:《Python數學運算技巧總結》、《Python數據結構與算法教程》、《Python函數使用技巧總結》、《Python字符串操作技巧匯總》、《Python入門與進階經典教程》及《Python文件與目錄操作技巧匯總》
希望本文所述對大家Python程序設計有所幫助。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





