溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關怎么在Python中實現一個K最近鄰從,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
Python是一種跨平臺的、具有解釋性、編譯性、互動性和面向對象的腳本語言,其最初的設計是用于編寫自動化腳本,隨著版本的不斷更新和新功能的添加,常用于用于開發獨立的項目和大型項目。
1.K最近鄰分類器原理
首先給出一張圖,根據這張圖來理解最近鄰分類器,如下:
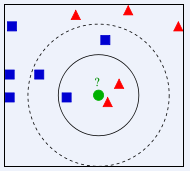
根據上圖所示,有兩類不同的樣本數據,分別用藍色的小正方形和紅色的小三角形表示,而圖正中間的那個綠色的圓所標示的數據則是待分類的數據。也就是說,現在, 我們不知道中間那個綠色的數據是從屬于哪一類(藍色小正方形or紅色小三角形),下面,我們就要解決這個問題:給這個綠色的圓分類。
我們常說,物以類聚,人以群分,判別一個人是一個什么樣品質特征的人,常常可以從他or她身邊的朋友入手,所謂觀其友,而識其人。我們不是要判別上圖中那個綠色的圓是屬于哪一類數據么,好說,從它的鄰居下手。但一次性看多少個鄰居呢?從上圖中,你還能看到:
如果K=3,綠色圓點的最近的3個鄰居是2個紅色小三角形和1個藍色小正方形,少數從屬于多數,基于統計的方法,判定綠色的這個待分類點屬于紅色的三角形一類。
如果K=5,綠色圓點的最近的5個鄰居是2個紅色三角形和3個藍色的正方形,還是少數從屬于多數,基于統計的方法,判定綠色的這個待分類點屬于藍色的正方形一類。
于此我們看到,當無法判定當前待分類點是從屬于已知分類中的哪一類時,我們可以依據統計學的理論看它所處的位置特征,衡量它周圍鄰居的權重,而把它歸為(或分配)到權重更大的那一類。這就是K近鄰算法的核心思想。其關鍵還在于K值的選取,所以應當謹慎。
KNN算法中,所選擇的鄰居都是已經正確分類的對象。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
KNN 算法本身簡單有效,它是一種 lazy-learning 算法,分類器不需要使用訓練集進行訓練,訓練時間復雜度為0。KNN 分類的計算復雜度和訓練集中的文檔數目成正比,也就是說,如果訓練集中文檔總數為 n,那么 KNN 的分類時間復雜度為O(n)。
前面的例子中強調了選擇合適的K值的重要性。如果太小,則最近鄰分類器容易受到訓練數據的噪聲而產生的過分擬合的影響;相反,如果K太大,最近分類器可能會誤會分類測試樣例,因為最近鄰列表中可能包含遠離其近鄰的數據點。(如下圖所示)
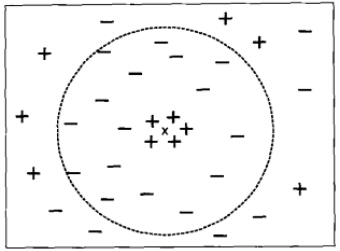
K較大時的最近鄰分類
可見,K值的選取還是非常關鍵。
2.算法算法描述
k近鄰算法簡單、直觀:給定一個訓練數據集(包括類別標簽),對新的輸入實例,在訓練數據集中找到與該實例最鄰近的k個實例,這k個實例的多數屬于某個類,就把該輸入實例分為這個類。下面是knn的算法步驟。
算法步驟如下所示:
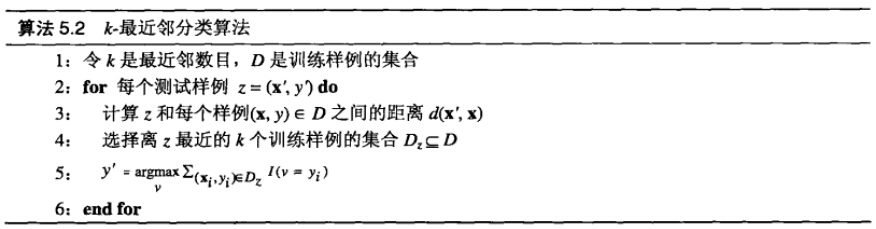
對每個測試樣例
特征空間中兩個實例點的距離是兩個實例相似程度的反映。
一旦得到最近鄰列表,測試樣例就可以根據最近鄰的多數類進行分類,使用多數表決方法。
K值選擇
k值對模型的預測有著直接的影響,如果k值過小,預測結果對鄰近的實例點非常敏感。如果鄰近的實例恰巧是噪聲數據,預測就會出錯。也就是說,k值越小就意味著整個模型就變得越復雜,越容易發生過擬合。
相反,如果k值越大,有點是可以減少模型的預測誤差,缺點是學習的近似誤差會增大。會使得距離實例點較遠的點也起作用,致使預測發生錯誤。同時,k值的增大意味著模型變得越來越簡單。如果k=N,那么無論輸入實例是什么,都將簡單的把它預測為樣本中最多的一類。這顯然實不可取的。
在實際建模應用中,k值一般取一個較小的數值,通常采用cross-validation的方法來選擇最優的k值。
3.K最鄰近算法實現(Python)
KNN.py(代碼來源《機器學習實戰》一書)
from numpy import *
import operator
class KNN:
def createDataset(self):
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
def KnnClassify(self,testX,trainX,labels,K):
[N,M]=trainX.shape
#calculate the distance between testX and other training samples
difference = tile(testX,(N,1)) - trainX # tile for array and repeat for matrix in Python, == repmat in Matlab
difference = difference ** 2 # take pow(difference,2)
distance = difference.sum(1) # take the sum of difference from all dimensions
distance = distance ** 0.5
sortdiffidx = distance.argsort()
# find the k nearest neighbours
vote = {} #create the dictionary
for i in range(K):
ith_label = labels[sortdiffidx[i]];
vote[ith_label] = vote.get(ith_label,0)+1 #get(ith_label,0) : if dictionary 'vote' exist key 'ith_label', return vote[ith_label]; else return 0
sortedvote = sorted(vote.iteritems(),key = lambda x:x[1], reverse = True)
# 'key = lambda x: x[1]' can be substituted by operator.itemgetter(1)
return sortedvote[0][0]
k = KNN() #create KNN object
group,labels = k.createDataset()
cls = k.KnnClassify([0,0],group,labels,3)
print cls運行:
1. 在Python Shell 中可以運行KNN.py
>>>import os
>>>os.chdir("/home/liudiwei/code/data_miningKNN/")
>>>execfile("KNN.py")輸出:B
(B表示類別)
2.或者terminal中直接運行
$ python KNN.py
3.也可以不在KNN.py中寫輸出,而選擇在Shell中獲得結果,i.e.,
>>>import KNN >>> KNN.k.KnnClassify([0,0],KNN.group,KNN.labels,3)
附件(兩張自己的計算過程圖):
 圖
圖
1 KNN算法核心部分

關于怎么在Python中實現一個K最近鄰從就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





