溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Django代碼性能優化與使用Pycharm Profile的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Django代碼性能優化與使用Pycharm Profile的示例分析”這篇文章吧。
一段導出數據月報的腳本,原先需要十幾秒,優化后只需要1秒多。
Pycharm Profile
優化第一步就是Profile,先看看慢在哪里。Pycharm自帶Profile工具,很方便。
拿一張官方圖說明一下。
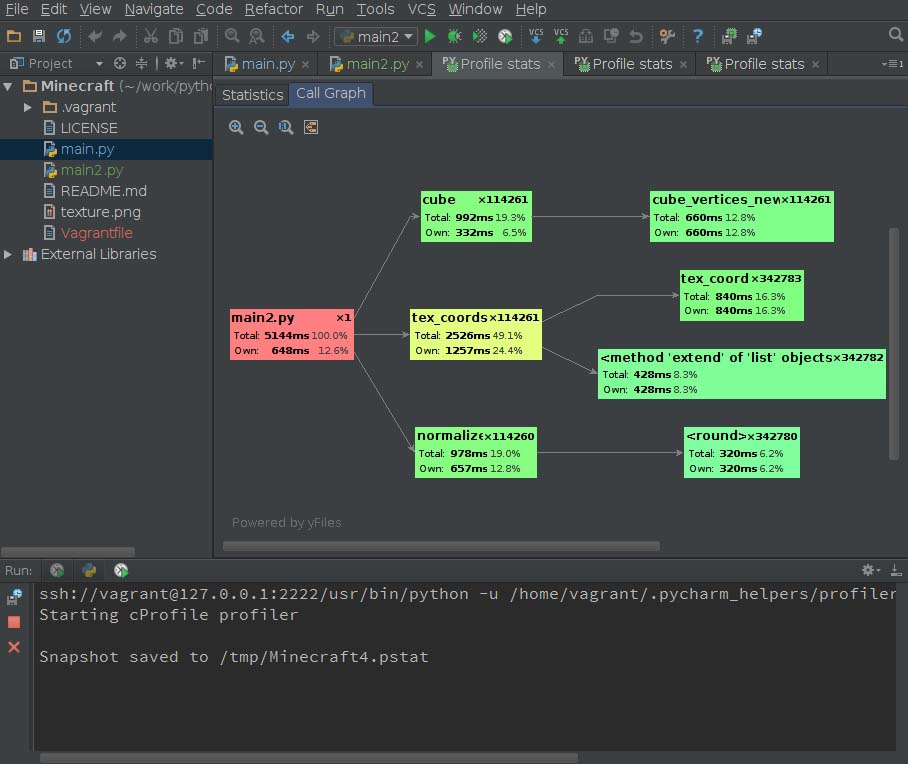
圖表說明:
給出了函數調用關系。
紅色->黃綠色->綠色,顏色越深說明耗時越多。
右上角的“x數字”代表函數調用次數。
Own代表該函數本身的耗時,不包括調用子函數;而Total包括調用子函數的耗時。還給出了耗時的百分比。
可以右鍵“jump to source”,跳到對應的源碼。
有了Profile,剩下的事情就好辦了。
首先,看到了有個工具函數調用了9千多次,這個函數用到了nametupled,花了很多時間,于是把nametupled去掉,節省了好幾秒的時間。
開啟Django logger并設置DEBUG級別
繼續Profile,看到時間主要在ORM查詢數據庫那里。
這時,開啟Django本身的logger,級別調到DEBUG,這樣就會打印出查詢的SQL語句。
N+1問題
首先意識到的是ORM查詢的N+1問題。
比如有個Order表,里面有個外鍵user_id是關聯User表.當我們
for order in Order.objects.all(): order.user.id
的時候,Order.objects.all()只有1條sql語句,獲取Order表本身的字段到內存,而不會將關聯的外鍵也獲取。
當我們order.user_id的時候,不會觸發額外的sql查詢,而order.user.id的時候,會額外查詢User表。
for循環執行了N次,就額外sql查詢了N次。故叫N+1問題。
解決N+1的方法:
如果是只用到id字段,則可以直接用user_id代替user.id
select_related。將相關的表也一同查詢。select_related如果不傳參數,表示查詢所有外鍵的表。
又節省了幾秒的時間。
只查詢需要的字段
繼續看log,發現sql查詢次數是減少了很多,然而sql查詢語句很長,看來是把所有字段都查詢出來。
然而我很多時候只需要某幾個字段而已,這樣全查出來就浪費了。
解決方法:
only()。只查詢想要的字段。比如Order.objects.only(‘user_id', ‘pay_date', ‘price')
annotate()。 可指定虛擬字段,如果外鍵關聯的表只用到小部分字段,可以直接annotate過來。比如將User表的realname字段賦給Order表叫user_realname虛擬字段.這樣就不需要order.user.realname查詢,只需要order.user_realname來查詢,不用select_related把user表全部字段給取出來。Order.objects.annotate(user_realname=F(‘user__realname'))。注意還用到了F(),表示純數據庫層面的操作,不需要拉到python內存進行處理。
An F() object represents the value of a model field or annotated column. It makes it possible to refer to model field values and perform database operations using them without actually having to pull them out of the database into Python memory.
至此,將整段代碼的執行時間減少到了1.5秒。
以上是“Django代碼性能優化與使用Pycharm Profile的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





