溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關如何從多方面了解Python代碼性能優化,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
代碼優化能夠讓程序運行更快,它是在不改變程序運行結果的情況下使得程序的運行效率更高,根據 80/20 原則,實現程序的重構、優化、擴展以及文檔相關的事情通常需要消耗 80% 的工作量。優化通常包含兩方面的內容:減小代碼的體積,提高代碼的運行效率。
改進算法,選擇合適的數據結構
一個良好的算法能夠對性能起到關鍵作用,因此性能改進的首要點是對算法的改進。在算法的時間復雜度排序上依次是:
O(1) -> O(lg n) -> O(n lg n) -> O(n^2) -> O(n^3) -> O(n^k) -> O(k^n) -> O(n!)
因此如果能夠在時間復雜度上對算法進行一定的改進,對性能的提高不言而喻。但對具體算法的改進不屬于本文討論的范圍,讀者可以自行參考這方面資料。下面的內容將集中討論數據結構的選擇。
字典 (dictionary) 與列表 (list)
Python 字典中使用了 hash table,因此查找操作的復雜度為 O(1),而 list 實際是個數組,在 list 中,查找需要遍歷整個 list,其復雜度為 O(n),因此對成員的查找訪問等操作字典要比 list 更快。
清單 1. 代碼 dict.py
from time import time t = time() list = ['a','b','is','python','jason','hello','hill','with','phone','test', 'dfdf','apple','pddf','ind','basic','none','baecr','var','bana','dd','wrd'] #list = dict.fromkeys(list,True) print list filter = [] for i in range (1000000): for find in ['is','hat','new','list','old','.']: if find not in list: filter.append(find) print "total run time:" print time()-t
上述代碼運行大概需要 16.09seconds。如果去掉行 #list = dict.fromkeys(list,True) 的注釋,將 list 轉換為字典之后再運行,時間大約為 8.375 seconds,效率大概提高了一半。因此在需要多數據成員進行頻繁的查找或者訪問的時候,使用 dict 而不是 list 是一個較好的選擇。
集合 (set) 與列表 (list)
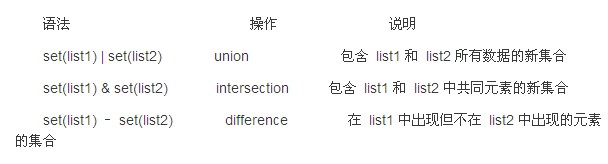
set 的 union, intersection,difference 操作要比 list 的迭代要快。因此如果涉及到求 list 交集,并集或者差的問題可以轉換為 set 來操作。
清單 2. 求 list 的交集:
from time import time t = time() lista=[1,2,3,4,5,6,7,8,9,13,34,53,42,44] listb=[2,4,6,9,23] intersection=[] for i in range (1000000): for a in lista: for b in listb: if a == b: intersection.append(a) print "total run time:" print time()-t
上述程序的運行時間大概為:
total run time:38.4070000648
清單 3. 使用 set 求交集
from time import time t = time() lista=[1,2,3,4,5,6,7,8,9,13,34,53,42,44] listb=[2,4,6,9,23] intersection=[] for i in range (1000000): list(set(lista)&set(listb)) print "total run time:" print time()-t
改為 set 后程序的運行時間縮減為 8.75,提高了 4 倍多,運行時間大大縮短。讀者可以自行使用表 1 其他的操作進行測試。
表 1. set 常見用法
對循環的優化
對循環的優化所遵循的原則是盡量減少循環過程中的計算量,有多重循環的盡量將內層的計算提到上一層。 下面通過實例來對比循環優化后所帶來的性能的提高。程序清單 4 中,如果不進行循環優化,其大概的運行時間約為 132.375。
清單 4. 為進行循環優化前
from time import time t = time() lista = [1,2,3,4,5,6,7,8,9,10] listb =[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.01] for i in range (1000000): for a in range(len(lista)): for b in range(len(listb)): x=lista[a]+listb[b] print "total run time:" print time()-t
現在進行如下優化,將長度計算提到循環外,range 用 xrange 代替,同時將第三層的計算 lista[a] 提到循環的第二層。
清單 5. 循環優化后
from time import time t = time() lista = [1,2,3,4,5,6,7,8,9,10] listb =[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.01] len1=len(lista) len2=len(listb) for i in xrange (1000000): for a in xrange(len1): temp=lista[a] for b in xrange(len2): x=temp+listb[b] print "total run time:" print time()-t
上述優化后的程序其運行時間縮短為 102.171999931。在清單 4 中 lista[a] 被計算的次數為 1000000*10*10,而在優化后的代碼中被計算的次數為 1000000*10,計算次數大幅度縮短,因此性能有所提升。
充分利用 Lazy if-evaluation 的特性
python 中條件表達式是 lazy evaluation 的,也就是說如果存在條件表達式 if x and y,在 x 為 false 的情況下 y 表達式的值將不再計算。因此可以利用該特性在一定程度上提高程序效率。
清單 6. 利用 Lazy if-evaluation 的特性
from time import time t = time() abbreviations = ['cf.', 'e.g.', 'ex.', 'etc.', 'fig.', 'i.e.', 'Mr.', 'vs.'] for i in range (1000000): for w in ('Mr.', 'Hat', 'is', 'chasing', 'the', 'black', 'cat', '.'): if w in abbreviations: #if w[-1] == '.' and w in abbreviations: pass print "total run time:" print time()-t在未進行優化之前程序的運行時間大概為 8.84,如果使用注釋行代替***個 if,運行的時間大概為 6.17。
字符串的優化
python 中的字符串對象是不可改變的,因此對任何字符串的操作如拼接,修改等都將產生一個新的字符串對象,而不是基于原字符串,因此這種持續的 copy 會在一定程度上影響 python 的性能。對字符串的優化也是改善性能的一個重要的方面,特別是在處理文本較多的情況下。字符串的優化主要集中在以下幾個方面:
1、在字符串連接的使用盡量使用 join() 而不是 +:在代碼清單 7 中使用 + 進行字符串連接大概需要 0.125 s,而使用 join 縮短為 0.016s。因此在字符的操作上 join 比 + 要快,因此要盡量使用 join 而不是 +。
清單 7. 使用 join 而不是 + 連接字符串
from time import time t = time() s = "" list = ['a','b','b','d','e','f','g','h','i','j','k','l','m','n'] for i in range (10000): for substr in list: s+= substr print "total run time:" print time()-t
同時要避免:
s = "" for x in list: s += func(x)
而是要使用:
slist = [func(elt) for elt in somelist] s = "".join(slist)
2、當對字符串可以使用正則表達式或者內置函數來處理的時候,選擇內置函數。如 str.isalpha(),str.isdigit(),str.startswith((‘x’, ‘yz’)),str.endswith((‘x’, ‘yz’))
3、對字符進行格式化比直接串聯讀取要快,因此要使用
out = "%s%s%s%s" % (head, prologue, query, tail)
而避免
out = "" + head + prologue + query + tail + ""
使用列表解析(list comprehension)和生成器表達式(generator expression)
列表解析要比在循環中重新構建一個新的 list 更為高效,因此我們可以利用這一特性來提高運行的效率。
from time import time t = time() list = ['a','b','is','python','jason','hello','hill','with','phone','test', 'dfdf','apple','pddf','ind','basic','none','baecr','var','bana','dd','wrd'] total=[] for i in range (1000000): for w in list: total.append(w) print "total run time:" print time()-t
使用列表解析:
for i in range (1000000): a = [w for w in list]
上述代碼直接運行大概需要 17s,而改為使用列表解析后 ,運行時間縮短為 9.29s。將近提高了一半。生成器表達式則是在 2.4 中引入的新內容,語法和列表解析類似,但是在大數據量處理時,生成器表達式的優勢較為明顯,它并不創建一個列表,只是返回一個生成器,因此效率較高。在上述例子上中代碼 a = [w for w in list] 修改為 a = (w for w in list),運行時間進一步減少,縮短約為 2.98s。
其他優化技巧
1、如果需要交換兩個變量的值使用 a,b=b,a 而不是借助中間變量 t=a;a=b;b=t;
>>> from timeit import Timer >>> Timer("t=a;a=b;b=t","a=1;b=2").timeit() 0.25154118749729365 >>> Timer("a,b=b,a","a=1;b=2").timeit() 0.17156677734181258 >> >2、在循環的時候使用 xrange 而不是 range;使用 xrange 可以節省大量的系統內存,因為 xrange() 在序列中每次調用只產生一個整數元素。而 range() 將直接返回完整的元素列表,用于循環時會有不必要的開銷。在 python3 中 xrange 不再存在,里面 range 提供一個可以遍歷任意長度的范圍的 iterator。
3、使用局部變量,避免”global” 關鍵字。python 訪問局部變量會比全局變量要快得多,因 此可以利用這一特性提升性能。
4、if done is not None 比語句 if done != None 更快,讀者可以自行驗證;
5、在耗時較多的循環中,可以把函數的調用改為內聯的方式;
6、使用級聯比較 “x < y < z” 而不是 “x < y and y < z”;
7、while 1 要比 while True 更快(當然后者的可讀性更好);
8、build in 函數通常較快,add(a,b) 要優于 a+b。
定位程序性能瓶頸
對代碼優化的前提是需要了解性能瓶頸在什么地方,程序運行的主要時間是消耗在哪里,對于比較復雜的代碼可以借助一些工具來定位,python 內置了豐富的性能分析工具,如 profile,cProfile 與 hotshot 等。其中 Profiler 是 python 自帶的一組程序,能夠描述程序運行時候的性能,并提供各種統計幫助用戶定位程序的性能瓶頸。Python 標準模塊提供三種 profilers:cProfile,profile 以及 hotshot。
profile 的使用非常簡單,只需要在使用之前進行 import 即可。具體實例如下:
清單 8. 使用 profile 進行性能分析
import profile def profileTest(): Total =1; for i in range(10): Total=Total*(i+1) print Total return Total if __name__ == "__main__": profile.run("profileTest()")程序的運行結果如下:
圖 1. 性能分析結果
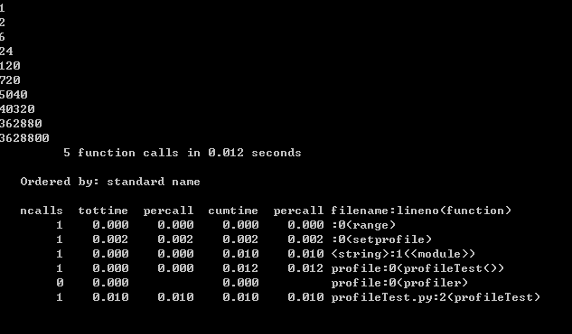
其中輸出每列的具體解釋如下:
ncalls:表示函數調用的次數;
tottime:表示指定函數的總的運行時間,除掉函數中調用子函數的運行時間;
percall:(***個 percall)等于 tottime/ncalls;
cumtime:表示該函數及其所有子函數的調用運行的時間,即函數開始調用到返回的時間;
percall:(第二個 percall)即函數運行一次的平均時間,等于 cumtime/ncalls;
filename:lineno(function):每個函數調用的具體信息;
如果需要將輸出以日志的形式保存,只需要在調用的時候加入另外一個參數。如 profile.run(“profileTest()”,”testprof”)。
對于 profile 的剖析數據,如果以二進制文件的時候保存結果的時候,可以通過 pstats 模塊進行文本報表分析,它支持多種形式的報表輸出,是文本界面下一個較為實用的工具。使用非常簡單:
import pstats p = pstats.Stats('testprof') p.sort_stats("name").print_stats()其中 sort_stats() 方法能夠對剖分數據進行排序, 可以接受多個排序字段,如 sort_stats(‘name’, ‘file’) 將首先按照函數名稱進行排序,然后再按照文件名進行排序。常見的排序字段有 calls( 被調用的次數 ),time(函數內部運行時間),cumulative(運行的總時間)等。此外 pstats 也提供了命令行交互工具,執行 python – m pstats 后可以通過 help 了解更多使用方式。
對于大型應用程序,如果能夠將性能分析的結果以圖形的方式呈現,將會非常實用和直觀,常見的可視化工具有 Gprof2Dot,visualpytune,KCacheGrind 等,讀者可以自行查閱相關官網,本文不做詳細討論。
Python 性能優化工具
Python 性能優化除了改進算法,選用合適的數據結構之外,還有幾種關鍵的技術,比如將關鍵 python 代碼部分重寫成 C 擴展模塊,或者選用在性能上更為優化的解釋器等,這些在本文中統稱為優化工具。python 有很多自帶的優化工具,如 Psyco,Pypy,Cython,Pyrex 等,這些優化工具各有千秋,本節選擇幾種進行介紹。
Psyco
psyco 是一個 just-in-time 的編譯器,它能夠在不改變源代碼的情況下提高一定的性能,Psyco 將操作編譯成有點優化的機器碼,其操作分成三個不同的級別,有”運行時”、”編譯時”和”虛擬時”變量。并根據需要提高和降低變量的級別。運行時變量只是常規 Python 解釋器處理的原始字節碼和對象結構。一旦 Psyco 將操作編譯成機器碼,那么編譯時變量就會在機器寄存器和可直接訪問的內存位置中表示。同時 python 能高速緩存已編譯的機器碼以備今后重用,這樣能節省一點時間。但 Psyco 也有其缺點,其本身運行所占內存較大。目前 psyco 已經不在 python2.7 中支持,而且不再提供維護和更新了,對其感興趣的可以參考 http://psyco.sourceforge.net/
Pypy
PyPy 表示 “用 Python 實現的 Python”,但實際上它是使用一個稱為 RPython 的 Python 子集實現的,能夠將 Python 代碼轉成 C, .NET, Java 等語言和平臺的代碼。PyPy 集成了一種即時 (JIT) 編譯器。和許多編譯器,解釋器不同,它不關心 Python 代碼的詞法分析和語法樹。 因為它是用 Python 語言寫的,所以它直接利用 Python 語言的 Code Object.。 Code Object 是 Python 字節碼的表示,也就是說, PyPy 直接分析 Python 代碼所對應的字節碼 ,,這些字節碼即不是以字符形式也不是以某種二進制格式保存在文件中, 而在 Python 運行環境中。目前版本是 1.8. 支持不同的平臺安裝,windows 上安裝 Pypy 需要先下載https://bitbucket.org/pypy/pypy/downloads/pypy-1.8-win32.zip,然后解壓到相關的目錄,并將解壓后的路徑添加到環境變量 path 中即可。在命令行運行 pypy,如果出現如下錯誤:”沒有找到 MSVCR100.dll, 因此這個應用程序未能啟動,重新安裝應用程序可能會修復此問題”,則還需要在微軟的官網上下載 VS 2010 runtime libraries 解決該問題。具體地址為http://www.microsoft.com/download/en/details.aspx?displaylang=en&id=5555
安裝成功后在命令行里運行 pypy,輸出結果如下:
C:\Documents and Settings\Administrator>pypy Python 2.7.2 (0e28b379d8b3, Feb 09 2012, 18:31:47) [PyPy 1.8.0 with MSC v.1500 32 bit] on win32 Type "help", "copyright", "credits" or "license" for more information. And now for something completely different: ``PyPy is vast, and contains multitudes'' >>>>
以清單 5 的循環為例子,使用 python 和 pypy 分別運行,得到的運行結果分別如下:
C:\Documents and Settings\Administrator\ 桌面 \doc\python>pypy loop.py total run time: 8.42199993134 C:\Documents and Settings\Administrator\ 桌面 \doc\python>python loop.py total run time: 106.391000032
可見使用 pypy 來編譯和運行程序,其效率大大的提高。
Cython
Cython 是用 python 實現的一種語言,可以用來寫 python 擴展,用它寫出來的庫都可以通過 import 來載入,性能上比 python 的快。cython 里可以載入 python 擴展 ( 比如 import math),也可以載入 c 的庫的頭文件 ( 比如 :cdef extern from “math.h”),另外也可以用它來寫 python 代碼。將關鍵部分重寫成 C 擴展模塊
Linux Cpython 的安裝:
***步:下載
[root@v5254085f259 cpython]# wget -N http://cython.org/release/Cython-0.15.1.zip --2012-04-16 22:08:35-- http://cython.org/release/Cython-0.15.1.zip Resolving cython.org... 128.208.160.197 Connecting to cython.org|128.208.160.197|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 2200299 (2.1M) [application/zip] Saving to: `Cython-0.15.1.zip' 100%[======================================>] 2,200,299 1.96M/s in 1.1s 2012-04-16 22:08:37 (1.96 MB/s) - `Cython-0.15.1.zip' saved [2200299/2200299]
第二步:解壓
[root@v5254085f259 cpython]# unzip -o Cython-0.15.1.zip
第三步:安裝
python setup.py install
安裝完成后直接輸入 cython,如果出現如下內容則表明安裝成功。
[root@v5254085f259 Cython-0.15.1]# cython Cython (http://cython.org) is a compiler for code written in the Cython language. Cython is based on Pyrex by Greg Ewing. Usage: cython [options] sourcefile.{pyx,py} ... Options: -V, --version Display version number of cython compiler -l, --create-listing Write error messages to a listing file -I, --include-dir <directory> Search for include files in named directory (multiple include directories are allowed). -o, --output-file <filename> Specify name of generated C file -t, --timestamps Only compile newer source files -f, --force Compile all source files (overrides implied -t) -q, --quiet Don't print module names in recursive mode -v, --verbose Be verbose, print file names on multiple compil ation -p, --embed-positions If specified, the positions in Cython files of each function definition is embedded in its docstring. --cleanup <level> Release interned objects on python exit, for memory debugging. Level indicates aggressiveness, default 0 releases nothing. -w, --working <directory> Sets the working directory for Cython (the directory modules are searched from) --gdb Output debug information for cygdb -D, --no-docstrings Strip docstrings from the compiled module. -a, --annotate Produce a colorized HTML version of the source. --line-directives Produce #line directives pointing to the .pyx source --cplus Output a C++ rather than C file. --embed[=<method_name>] Generate a main() function that embeds the Python interpreter. -2 Compile based on Python-2 syntax and code seman tics. -3 Compile based on Python-3 syntax and code seman tics. --fast-fail Abort the compilation on the first error --warning-error, -Werror Make all warnings into errors --warning-extra, -Wextra Enable extra warnings -X, --directive <name>=<value> [,<name=value,...] Overrides a compiler directive其他平臺上的安裝可以參考文檔:http://docs.cython.org/src/quickstart/install.html
Cython 代碼與 python 不同,必須先編譯,編譯一般需要經過兩個階段,將 pyx 文件編譯為 .c 文件,再將 .c 文件編譯為 .so 文件。編譯有多種方法:
通過命令行編譯:
假設有如下測試代碼,使用命令行編譯為 .c 文件。
def sum(int a,int b): print a+b [root@v5254085f259 test]# cython sum.pyx [root@v5254085f259 test]# ls total 76 4 drwxr-xr-x 2 root root 4096 Apr 17 02:45 . 4 drwxr-xr-x 4 root root 4096 Apr 16 22:20 .. 4 -rw-r--r-- 1 root root 35 Apr 17 02:45 1 60 -rw-r--r-- 1 root root 55169 Apr 17 02:45 sum.c 4 -rw-r--r-- 1 root root 35 Apr 17 02:45 sum.pyx
在 linux 上利用 gcc 編譯為 .so 文件
[root@v5254085f259 test]# gcc -shared -pthread -fPIC -fwrapv -O2 -Wall -fno-strict-aliasing -I/usr/include/python2.4 -o sum.so sum.c [root@v5254085f259 test]# ls total 96 4 drwxr-xr-x 2 root root 4096 Apr 17 02:47 . 4 drwxr-xr-x 4 root root 4096 Apr 16 22:20 .. 4 -rw-r--r-- 1 root root 35 Apr 17 02:45 1 60 -rw-r--r-- 1 root root 55169 Apr 17 02:45 sum.c 4 -rw-r--r-- 1 root root 35 Apr 17 02:45 sum.pyx 20 -rwxr-xr-x 1 root root 20307 Apr 17 02:47 sum.so
使用 distutils 編譯
建立一個 setup.py 的腳本:
from distutils.core import setup from distutils.extension import Extension from Cython.Distutils import build_ext ext_modules = [Extension("sum", ["sum.pyx"])] setup( name = 'sum app', cmdclass = {'build_ext': build_ext}, ext_modules = ext_modules ) [root@v5254085f259 test]# python setup.py build_ext --inplace running build_ext cythoning sum.pyx to sum.c building 'sum' extension gcc -pthread -fno-strict-aliasing -fPIC -g -O2 -DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes -fPIC -I/opt/ActivePython-2.7/include/python2.7 -c sum.c -o build/temp.linux-x86_64-2.7/sum.o gcc -pthread -shared build/temp.linux-x86_64-2.7/sum.o -o /root/cpython/test/sum.so編譯完成之后可以導入到 python 中使用:
[root@v5254085f259 test]# python ActivePython 2.7.2.5 (ActiveState Software Inc.) based on Python 2.7.2 (default, Jun 24 2011, 11:24:26) [GCC 4.0.2 20051125 (Red Hat 4.0.2-8)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import pyximport; pyximport.install() >>> import sum >>> sum.sum(1,3)
下面來進行一個簡單的性能比較:
清單 9. Cython 測試代碼
from time import time def test(int n): cdef int a =0 cdef int i for i in xrange(n): a+= i return a t = time() test(10000000) print "total run time:" print time()-t
測試結果:
[GCC 4.0.2 20051125 (Red Hat 4.0.2-8)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import pyximport; pyximport.install() >>> import ctest total run time: 0.00714015960693
清單 10. Python 測試代碼
from time import time def test(n): a =0; for i in xrange(n): a+= i return a t = time() test(10000000) print "total run time:" print time()-t [root@v5254085f259 test]# python test.py total run time: 0.971596002579
從上述對比可以看到使用 Cython 的速度提高了將近 100 多倍。
初步探討了 python 常見的性能優化技巧以及如何借助工具來定位和分析程序的性能瓶頸,并提供了相關可以進行性能優化的工具或語言。
看完上述內容,你們對如何從多方面了解Python代碼性能優化有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





