溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了MySQL執行計劃的示例分析,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
執行計劃是什么?
執行計劃,簡單的來說,是SQL在數據庫中執行時的表現情況,通常用于SQL性能分析,優化等場景。
一. 執行計劃能告訴我們什么?
SQL如何使用索引
聯接查詢的執行順序
查詢掃描的數據函數
二. 執行計劃中的內容
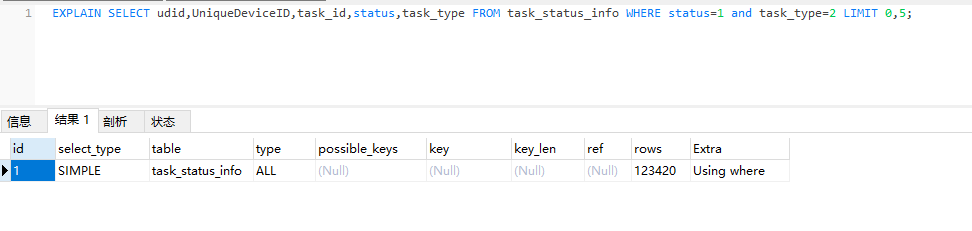
SQL執行計劃的輸出可能為多行,每一行代表對一個數據庫對象的操作
1. ID列
ID列中的如果數據為一組數字,表示執行SELECT語句的順序;如果為NULL,則說明這一行數據是由另外兩個SQL語句進行 UNION操作后產生的結果集
ID值相同時,說明SQL執行順序是按照顯示的從上至下執行的
ID值不同時,ID值越大代表優先級越高,則越先被執行
演示
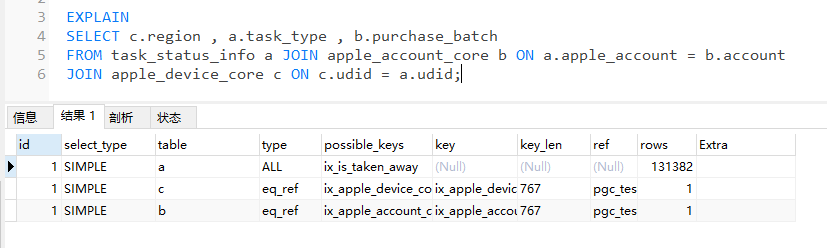
可以看到上面的執行計劃返回了3行結果,id列的值可以看作是SQL中所具有的SELECT操作的序號
由于上述SQL中只有一個SELECT,所以id全為1,因此,我們就要按照由上至下讀取執行計劃
按照我們的SQL語句,我們會認為執行順序是a,b,c,但是通過上圖可以發現,Mysql并不是完成按照SQL中所寫的順序來進行表的關聯操作的
執行對表的執行順序為a,c,b,這是由于MySQL優化器會根據表中的索引的統計信息來調整表關聯的實際順序
2. SELECT_TYPE列
| 值 | 含義 |
|---|---|
| SIMPLE | 不包含子查詢或是UNION操作的查詢 |
| PRIMARY | 查詢中如果包含任何子查詢,那么最外層的查詢則被標記為PRIMARY |
| SUBQUERY | SELECT 列表中的子查詢 |
| DEPENDENT SUBQUERY | 依賴外部結果的子查詢 |
| UNION | Union操作的第二個或是之后的查詢的值為union |
| DEPENDENT UNION | 當UNION作為子查詢時,第二或是第二個后的查詢的select_type值 |
| UNION RESULT | UNION產生的結果集 |
| DERIVED | 出現在FROM子句中的子查詢 |
3. TABLE列
包含以下幾種結果:
輸出去數據行所在表的名稱,如果表取了別名,則顯示的是別名
<union M,N>: 由ID為M,N查詢union產生的結果集
<derived N>/<subquery N> :由ID為N的查詢產生的結果
4. PARTITIONS列:
查詢匹配的記錄來自哪一個分區
對于分區表,顯示查詢的分區ID
對于非分區表,顯示為NULL
5. TYPE列
按性能從高至低排列如下:
| 值 | 含義 |
|---|---|
| system | 這是const聯接類型的一個特例,當查詢的表只有一行時使用 |
| const | 表中有且只有一個匹配的行時使用,如對主鍵或是唯一索引的查詢,這是效率最高的聯接方式 |
| eq_ref | 唯一索引或主鍵索引查詢,對應每個索引鍵,表中只有一條記錄與之匹配 |
| ref | 非唯一索引查找,返回匹配某個單獨值的所有行 |
| ref_or_null | 類似于ref類型的查詢,但是附加了對NULL值列的查詢 |
| index_merge | 該聯接類型表示使用了索引合并優化方法 |
| range | 索引范圍掃描,常見于between、>、<這樣的查詢條件 |
| index | FULL index Scan 全索引掃描,同ALL的區別是,遍歷的是索引樹 |
| ALL | FULL TABLE Scan 全表掃描,這是效率最差的聯接方式 |
6. Extra列
包含MySQL如何執行查詢的附加信息
| 值 | 含義 |
|---|---|
| Distinct | 優化distinct操作,在找到第一個匹配的元素后即停止查找 |
| Not exists | 使用not exists來優化查詢 |
| Using filesort | 使用額外操作進行排序,通常會出現在order by或group by查詢中 |
| Using index | 使用了覆蓋索引進行查詢 |
| Using temporary | MySQL需要使用臨時表來處理查詢,常見于排序,子查詢,和分組查詢 |
| Using where | 需要在MySQL服務器層使用WHERE條件來過濾數據 |
| select tables optimized away | 直接通過索引來獲得數據,不用訪問表,這種情況通常效率是最高的 |
7. POSSIBLE_KEYS列
指出MySQL能使用哪些索引來優化查詢
查詢列所涉及到的列上的索引都會被列出,但不一定會被使用
8. KEY列
查詢優化器優化查詢實際所使用的索引
如果表中沒有可用的索引,則顯示為NULL
如果查詢使用了覆蓋索引,則該索引僅出現在Key列中
9. KEY_LEN列
顯示MySQL索引所使用的字節數,在聯合索引中如果有3列,假如3列字段總長度為100個字節,Key_len顯示的可能會小于100字節,比如30字節,這就說明在查詢過程中沒有使用到聯合索引的所有列,只是利用到了前面的一列或2列
表示索引字段的最大可能長度
Key_len的長度由字段定義計算而來,并非數據的實際長度
10. Ref列
表示當前表在利用Key列記錄中的索引進行查詢時所用到的列或常量
11. rows列
表示MySQL通過索引的統計信息,估算出來的所需讀取的行數(關聯查詢時,顯示的是每次嵌套查詢時所需要的行數)
Rows值的大小是個統計抽樣結果,并不十分準確
12. Filtered列
表示返回結果的行數占需讀取行數的百分比
Filtered列的值越大越好(值越大,表明實際讀取的行數與所需要返回的行數越接近)
Filtered列的值依賴統計信息,所以同樣也不是十分準確,只是一個參考值
三. 執行計劃的限制
無法展示存儲過程,觸發器,UDF對查詢的影響
無法使用EXPLAIN對存儲過程進行分析
早期版本的MySQL只支持對SELECT語句進行分析
感謝你能夠認真閱讀完這篇文章,希望小編分享的“MySQL執行計劃的示例分析”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





