溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
在MySQL中,我們可以通過EXPLAIN命令獲取MySQL如何執行SELECT語句的信息,包括在SELECT語句執行過程中表如何連接和連接的順序。

下面分別對EXPLAIN命令結果的每一列進行說明:
.select_type:表示SELECT的類型,常見的取值有:
| 類型 | 說明 |
|---|---|
| SIMPLE | 簡單表,不使用表連接或子查詢 |
| PRIMARY | 主查詢,即外層的查詢 |
| UNION | UNION中的第二個或者后面的查詢語句 |
| SUBQUERY | 子查詢中的第一個 |
.table:輸出結果集的表(表別名)
.type:表示MySQL在表中找到所需行的方式,或者叫訪問類型。常見訪問類型如下,從上到下,性能由差到最好:
| ALL | 全表掃描 |
|---|---|
| index | 索引全掃描 |
| range | 索引范圍掃描 |
| ref | 非唯一索引掃描 |
| eq_ref | 唯一索引掃描 |
| const,system | 單表最多有一個匹配行 |
| NULL | 不用掃描表或索引 |
1、type=ALL,全表掃描,MySQL遍歷全表來找到匹配行
一般是沒有where條件或者where條件沒有使用索引的查詢語句
EXPLAIN SELECT * FROM customer WHERE active=0;

2、type=index,索引全掃描,MySQL遍歷整個索引來查詢匹配行,并不會掃描表
一般是查詢的字段都有索引的查詢語句
EXPLAIN SELECT store_id FROM customer;

3、type=range,索引范圍掃描,常用于<、<=、>、>=、between等操作
EXPLAIN SELECT * FROM customer WHERE customer_id>=10 AND customer_id<=20;

注意這種情況下比較的字段是需要加索引的,如果沒有索引,則MySQL會進行全表掃描,如下面這種情況,create_date字段沒有加索引:
EXPLAIN SELECT * FROM customer WHERE create_date>='2006-02-13' ;

4、type=ref,使用非唯一索引或唯一索引的前綴掃描,返回匹配某個單獨值的記錄行
store_id字段存在普通索引(非唯一索引)
EXPLAIN SELECT * FROM customer WHERE store_id=10;

ref類型還經常會出現在join操作中:
customer、payment表關聯查詢,關聯字段customer.customer_id(主鍵),payment.customer_id(非唯一索引)。表關聯查詢時必定會有一張表進行全表掃描,此表一定是幾張表中記錄行數最少的表,然后再通過非唯一索引尋找其他關聯表中的匹配行,以此達到表關聯時掃描行數最少。
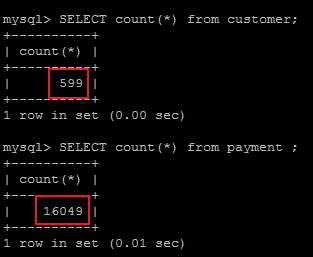
因為customer、payment兩表中customer表的記錄行數最少,所以customer表進行全表掃描,payment表通過非唯一索引尋找匹配行。
EXPLAIN SELECT * FROM customer customer INNER JOIN payment payment ON customer.customer_id = payment.customer_id;

5、type=eq_ref,類似ref,區別在于使用的索引是唯一索引,對于每個索引鍵值,表中只有一條記錄匹配
eq_ref一般出現在多表連接時使用primary key或者unique index作為關聯條件。
film、film_text表關聯查詢和上一條所說的基本一致,只不過關聯條件由非唯一索引變成了主鍵。
EXPLAIN SELECT * FROM film film INNER JOIN film_text film_text ON film.film_id = film_text.film_id;

6、type=const/system,單表中最多有一條匹配行,查詢起來非常迅速,所以這個匹配行的其他列的值可以被優化器在當前查詢中當作常量來處理
const/system出現在根據主鍵primary key或者 唯一索引 unique index 進行的查詢
根據主鍵primary key進行的查詢:
EXPLAIN SELECT * FROM customer WHERE customer_id =10;

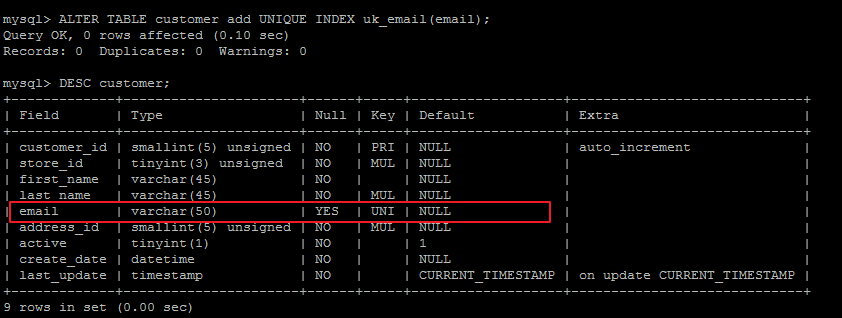
根據唯一索引unique index進行的查詢:
EXPLAIN SELECT * FROM customer WHERE email ='MARY.SMITH@sakilacustomer.org';

7、type=NULL,MySQL不用訪問表或者索引,直接就能夠得到結果

.possible_keys: 表示查詢可能使用的索引
.key: 實際使用的索引
.key_len: 使用索引字段的長度
.ref: 使用哪個列或常數與key一起從表中選擇行。
.rows: 掃描行的數量
.filtered: 存儲引擎返回的數據在server層過濾后,剩下多少滿足查詢的記錄數量的比例(百分比)
.Extra: 執行情況的說明和描述,包含不適合在其他列中顯示但是對執行計劃非常重要的額外信息
最主要的有一下三種:
| Using Index | 表示索引覆蓋,不會回表查詢 |
|---|---|
| Using Where | 表示進行了回表查詢 |
| Using Index Condition | 表示進行了ICP優化 |
| Using Flesort | 表示MySQL需額外排序操作, 不能通過索引順序達到排序效果 |
什么是ICP?
MySQL5.6引入了Index Condition Pushdown(ICP)的特性,進一步優化了查詢。Pushdown表示操作下放,某些情況下的條件過濾操作下放到存儲引擎。
EXPLAIN SELECT * FROM rental WHERE rental_date='2005-05-25' AND customer_id>=300 AND customer_id<=400;
在5.6版本之前:
優化器首先使用復合索引idx_rental_date過濾出符合條件rental_date='2005-05-25'的記錄,然后根據復合索引idx_rental_date回表獲取記錄,最終根據條件customer_id>=300 AND customer_id<=400過濾出最后的查詢結果(在服務層完成)。
在5.6版本之后:
MySQL使用了ICP來進一步優化查詢,在檢索的時候,把條件customer_id>=300 AND customer_id<=400也推到存儲引擎層完成過濾,這樣能夠降低不必要的IO訪問。Extra為Using index condition就表示使用了ICP優化。

參考
《深入淺出MySQL》
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,如果有疑問大家可以留言交流,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





