溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Mysql怎么查看執行計劃”,在日常操作中,相信很多人在Mysql怎么查看執行計劃問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Mysql怎么查看執行計劃”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
使用explain關鍵字可以模擬優化器執行SQL查詢語句,從而知道MySQL是如何處理你的SQL語句的,分析你的查詢語句或是表結構的性能瓶頸。
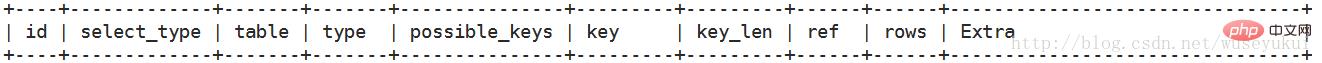
其中最重要的字段為:id、type、key、rows、Extra
select查詢的序列號,包含一組數字,表示查詢中執行select子句或操作表的順序
三種情況:
1、id相同:執行順序由上至下

2、id不同:如果是子查詢,id的序號會遞增,id值越大優先級越高,越先被執行

3、id相同又不同(兩種情況同時存在):id如果相同,可以認為是一組,從上往下順序執行;在所有組中,id值越大,優先級越高,越先執行

查詢的類型,主要是用于區分普通查詢、聯合查詢、子查詢等復雜的查詢
1、SIMPLE:簡單的select查詢,查詢中不包含子查詢或者union
2、PRIMARY:查詢中包含任何復雜的子部分,最外層查詢則被標記為primary
3、SUBQUERY:在select 或 where列表中包含了子查詢
4、DERIVED:在from列表中包含的子查詢被標記為derived(衍生),mysql或遞歸執行這些子查詢,把結果放在零時表里
5、UNION:若第二個select出現在union之后,則被標記為union;若union包含在from子句的子查詢中,外層select將被標記為derived
6、UNION RESULT:從union表獲取結果的select
訪問類型,sql查詢優化中一個很重要的指標,結果值從好到壞依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般來說,好的sql查詢至少達到range級別,最好能達到ref
1、system:表只有一行記錄(等于系統表),這是const類型的特例,平時不會出現,可以忽略不計
2、const:表示通過索引一次就找到了,const用于比較primary key 或者 unique索引。因為只需匹配一行數據,所有很快。如果將主鍵置于where列表中,mysql就能將該查詢轉換為一個const

3、eq_ref:唯一性索引掃描,對于每個索引鍵,表中只有一條記錄與之匹配。常見于主鍵 或 唯一索引掃描。

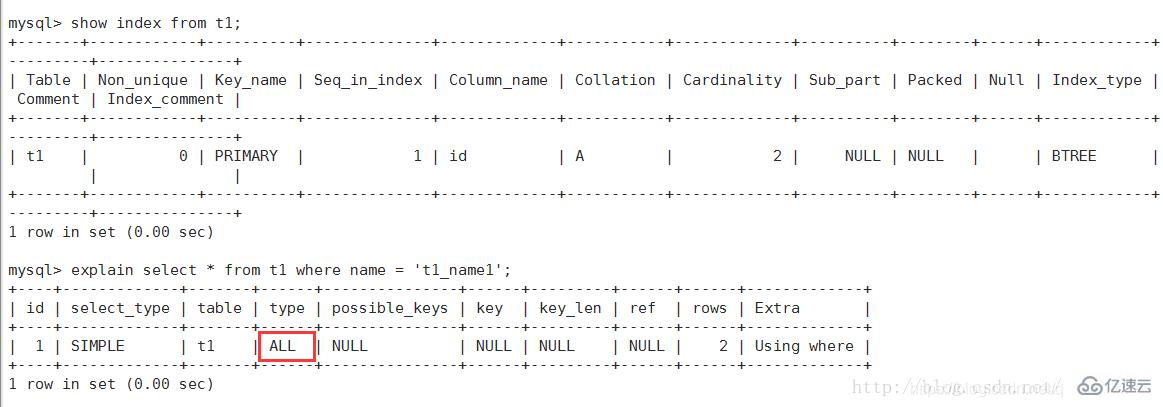
注意:ALL全表掃描的表記錄最少的表如t1表
4、ref:非唯一性索引掃描,返回匹配某個單獨值的所有行。本質是也是一種索引訪問,它返回所有匹配某個單獨值的行,然而他可能會找到多個符合條件的行,所以它應該屬于查找和掃描的混合體
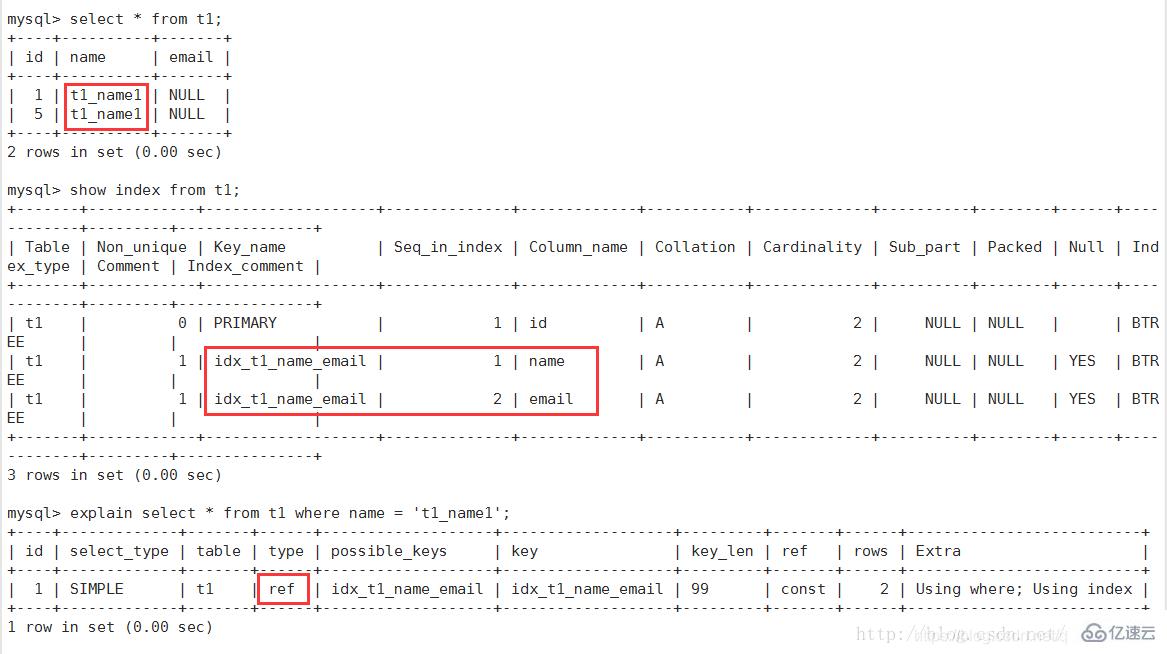
5、range:只檢索給定范圍的行,使用一個索引來選擇行。key列顯示使用了那個索引。一般就是在where語句中出現了bettween、<、>、in等的查詢。這種索引列上的范圍掃描比全索引掃描要好。只需要開始于某個點,結束于另一個點,不用掃描全部索引

6、index:Full Index Scan,index與ALL區別為index類型只遍歷索引樹。這通常為ALL塊,應為索引文件通常比數據文件小。(Index與ALL雖然都是讀全表,但index是從索引中讀取,而ALL是從硬盤讀取)

7、ALL:Full Table Scan,遍歷全表以找到匹配的行
查詢涉及到的字段上存在索引,則該索引將被列出,但不一定被查詢實際使用
實際使用的索引,如果為NULL,則沒有使用索引。
查詢中如果使用了覆蓋索引,則該索引僅出現在key列表中
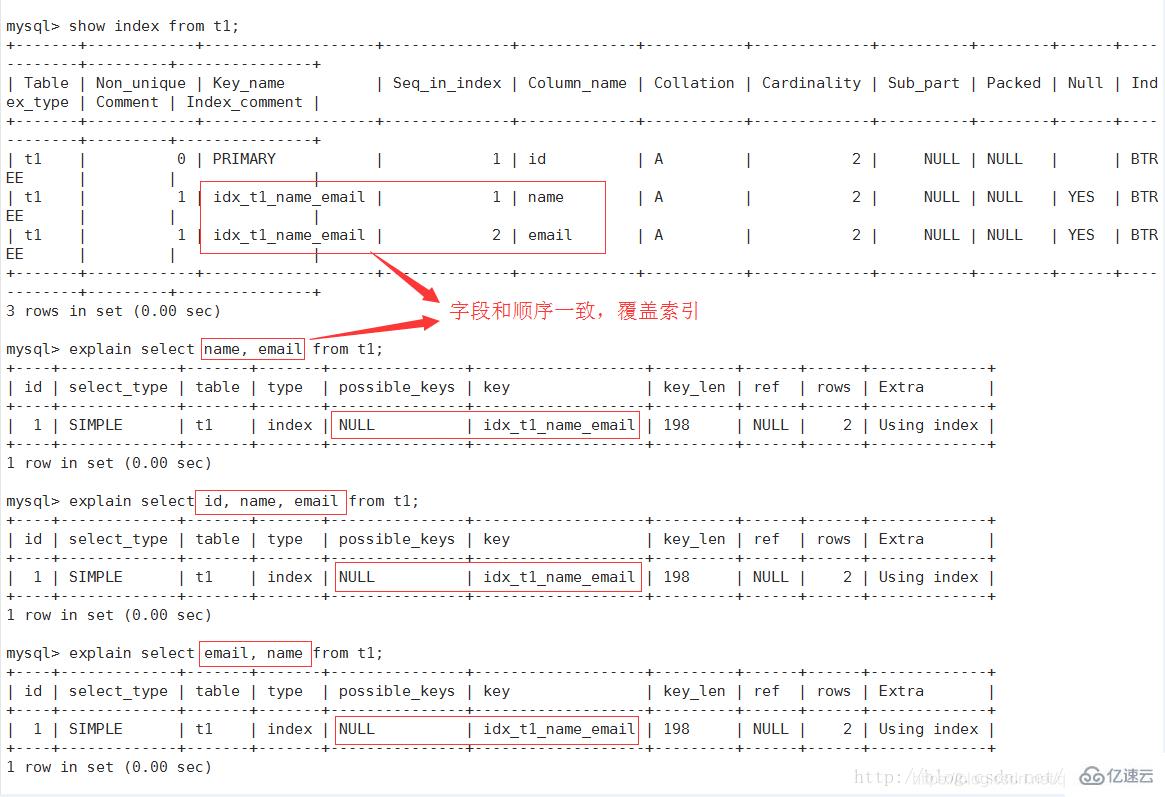

表示索引中使用的字節數,查詢中使用的索引的長度(最大可能長度),并非實際使用長度,理論上長度越短越好。key_len是根據表定義計算而得的,不是通過表內檢索出的
顯示索引的那一列被使用了,如果可能,是一個常量const。
根據表統計信息及索引選用情況,大致估算出找到所需的記錄所需要讀取的行數
不適合在其他字段中顯示,但是十分重要的額外信息
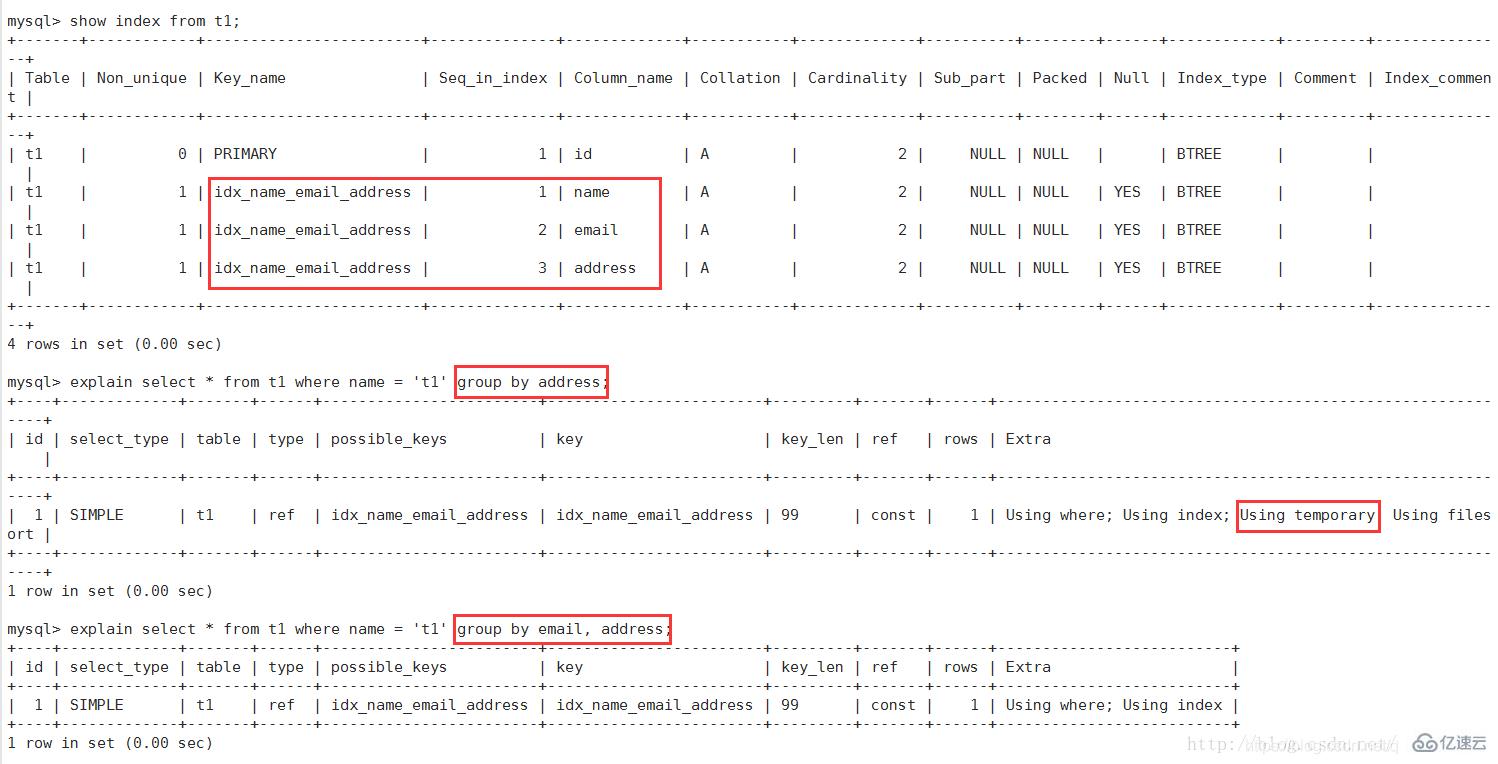
1、Using filesort :
mysql對數據使用一個外部的索引排序,而不是按照表內的索引進行排序讀取。也就是說mysql無法利用索引完成的排序操作成為“文件排序”

由于索引是先按email排序、再按address排序,所以查詢時如果直接按address排序,索引就不能滿足要求了,mysql內部必須再實現一次“文件排序”
2、Using temporary:
使用臨時表保存中間結果,也就是說mysql在對查詢結果排序時使用了臨時表,常見于order by 和 group by
3、Using index:
表示相應的select操作中使用了覆蓋索引(Covering Index),避免了訪問表的數據行,效率高
如果同時出現Using where,表明索引被用來執行索引鍵值的查找(參考上圖)
如果沒用同時出現Using where,表明索引用來讀取數據而非執行查找動作
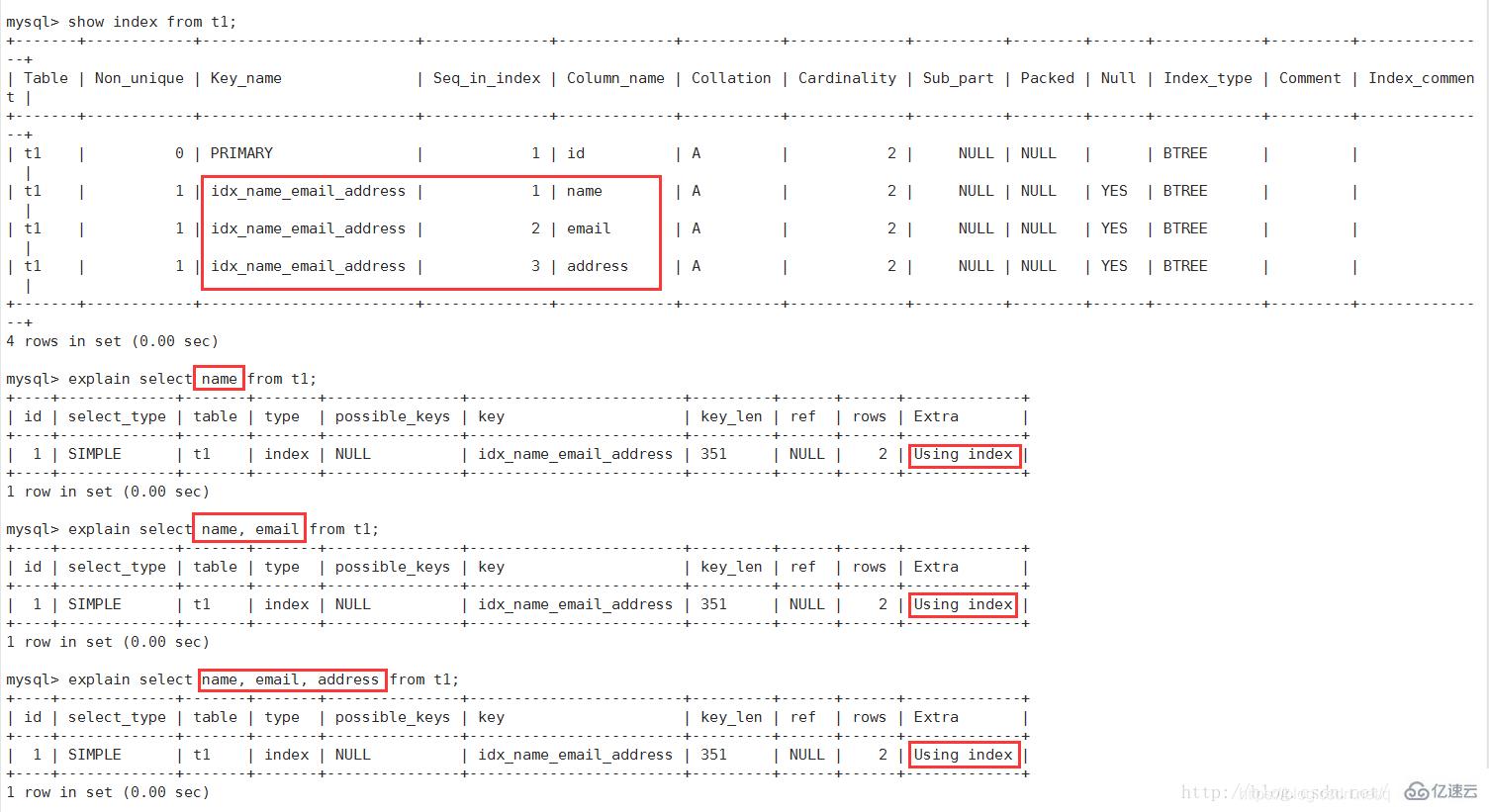
覆蓋索引(Covering Index):也叫索引覆蓋。就是select列表中的字段,只用從索引中就能獲取,不必根據索引再次讀取數據文件,換句話說查詢列要被所建的索引覆蓋。
注意:
a、如需使用覆蓋索引,select列表中的字段只取出需要的列,不要使用select *
b、如果將所有字段都建索引會導致索引文件過大,反而降低crud性能
4、Using where :
使用了where過濾
5、Using join buffer :
使用了鏈接緩存
6、Impossible WHERE:
where子句的值總是false,不能用來獲取任何元祖

7、select tables optimized away:
在沒有group by子句的情況下,基于索引優化MIN/MAX操作或者對于MyISAM存儲引擎優化COUNT(*)操作,不必等到執行階段在進行計算,查詢執行計劃生成的階段即可完成優化
8、distinct:
優化distinct操作,在找到第一個匹配的元祖后即停止找同樣值得動作

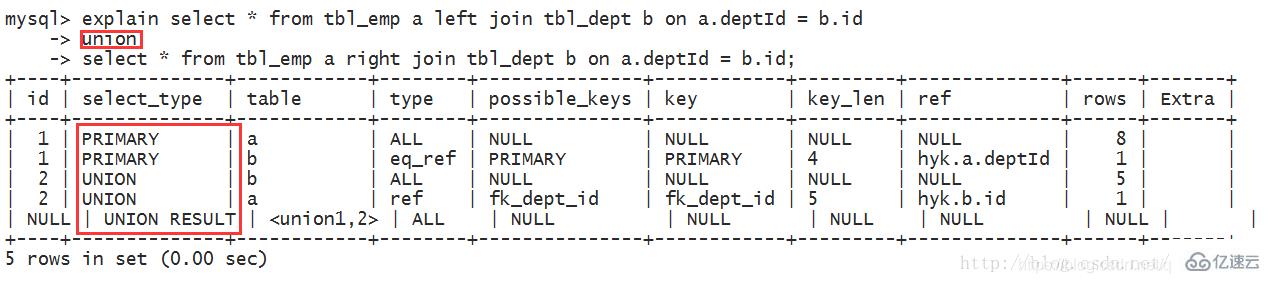
1(id = 4)、【select id, name from t2】:select_type 為union,說明id=4的select是union里面的第二個select。
2(id = 3)、【select id, name from t1 where address = ‘11’】:因為是在from語句中包含的子查詢所以被標記為DERIVED(衍生),where address = ‘11’ 通過復合索引idx_name_email_address就能檢索到,所以type為index。
3(id = 2)、【select id from t3】:因為是在select中包含的子查詢所以被標記為SUBQUERY。
4(id = 1)、【select d1.name, … d2 from … d1】:select_type為PRIMARY表示該查詢為最外層查詢,table列被標記為 “derived3”表示查詢結果來自于一個衍生表(id = 3 的select結果)。
5(id = NULL)、【 … union … 】:代表從union的臨時表中讀取行的階段,table列的 “union 1, 4”表示用id=1 和 id=4 的select結果進行union操作。
到此,關于“Mysql怎么查看執行計劃”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





