溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下如何使用python實現語音文件的特征提取,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
概述
語音識別是當前人工智能的比較熱門的方向,技術也比較成熟,各大公司也相繼推出了各自的語音助手機器人,如百度的小度機器人、阿里的天貓精靈等。語音識別算法當前主要是由RNN、LSTM、DNN-HMM等機器學習和深度學習技術做支撐。但訓練這些模型的第一步就是將音頻文件數據化,提取當中的語音特征。
MP3文件轉化為WAV文件
錄制音頻文件的軟件大多數都是以mp3格式輸出的,但mp3格式文件對語音的壓縮比例較重,因此首先利用ffmpeg將轉化為wav原始文件有利于語音特征的提取。其轉化代碼如下:
from pydub import AudioSegment import pydub def MP32WAV(mp3_path,wav_path): """ 這是MP3文件轉化成WAV文件的函數 :param mp3_path: MP3文件的地址 :param wav_path: WAV文件的地址 """ pydub.AudioSegment.converter = "D:\\ffmpeg\\bin\\ffmpeg.exe" MP3_File = AudioSegment.from_mp3(file=mp3_path) MP3_File.export(wav_path,format="wav")
讀取WAV語音文件,對語音進行采樣
利用wave庫對語音文件進行采樣。
代碼如下:
import wave
import json
def Read_WAV(wav_path):
"""
這是讀取wav文件的函數,音頻數據是單通道的。返回json
:param wav_path: WAV文件的地址
"""
wav_file = wave.open(wav_path,'r')
numchannel = wav_file.getnchannels() # 聲道數
samplewidth = wav_file.getsampwidth() # 量化位數
framerate = wav_file.getframerate() # 采樣頻率
numframes = wav_file.getnframes() # 采樣點數
print("channel", numchannel)
print("sample_width", samplewidth)
print("framerate", framerate)
print("numframes", numframes)
Wav_Data = wav_file.readframes(numframes)
Wav_Data = np.fromstring(Wav_Data,dtype=np.int16)
Wav_Data = Wav_Data*1.0/(max(abs(Wav_Data))) #對數據進行歸一化
# 生成音頻數據,ndarray不能進行json化,必須轉化為list,生成JSON
dict = {"channel":numchannel,
"samplewidth":samplewidth,
"framerate":framerate,
"numframes":numframes,
"WaveData":list(Wav_Data)}
return json.dumps(dict)繪制聲波折線圖與頻譜圖
代碼如下:
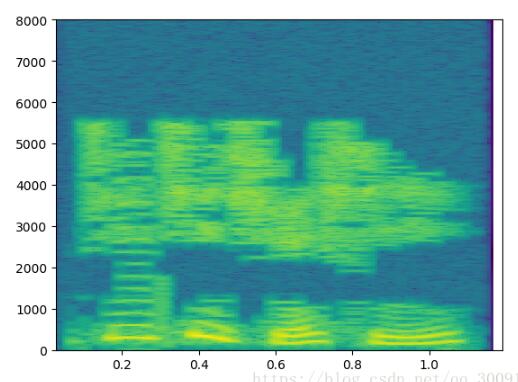
from matplotlib import pyplot as plt def DrawSpectrum(wav_data,framerate): """ 這是畫音頻的頻譜函數 :param wav_data: 音頻數據 :param framerate: 采樣頻率 """ Time = np.linspace(0,len(wav_data)/framerate*1.0,num=len(wav_data)) plt.figure(1) plt.plot(Time,wav_data) plt.grid(True) plt.show() plt.figure(2) Pxx, freqs, bins, im = plt.specgram(wav_data,NFFT=1024,Fs = 16000,noverlap=900) plt.show() print(Pxx) print(freqs) print(bins) print(im)
首先利用百度AI開發平臺的語音合API生成的MP3文件進行上述過程的結果。
聲波折線圖

頻譜圖
全部代碼
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2018/7/5 13:11
# @Author : DaiPuwei
# @FileName: VoiceExtract.py
# @Software: PyCharm
# @E-mail :771830171@qq.com
# @Blog :https://blog.csdn.net/qq_30091945
import numpy as np
from pydub import AudioSegment
import pydub
import os
import wave
import json
from matplotlib import pyplot as plt
def MP32WAV(mp3_path,wav_path):
"""
這是MP3文件轉化成WAV文件的函數
:param mp3_path: MP3文件的地址
:param wav_path: WAV文件的地址
"""
pydub.AudioSegment.converter = "D:\\ffmpeg\\bin\\ffmpeg.exe" #說明ffmpeg的地址
MP3_File = AudioSegment.from_mp3(file=mp3_path)
MP3_File.export(wav_path,format="wav")
def Read_WAV(wav_path):
"""
這是讀取wav文件的函數,音頻數據是單通道的。返回json
:param wav_path: WAV文件的地址
"""
wav_file = wave.open(wav_path,'r')
numchannel = wav_file.getnchannels() # 聲道數
samplewidth = wav_file.getsampwidth() # 量化位數
framerate = wav_file.getframerate() # 采樣頻率
numframes = wav_file.getnframes() # 采樣點數
print("channel", numchannel)
print("sample_width", samplewidth)
print("framerate", framerate)
print("numframes", numframes)
Wav_Data = wav_file.readframes(numframes)
Wav_Data = np.fromstring(Wav_Data,dtype=np.int16)
Wav_Data = Wav_Data*1.0/(max(abs(Wav_Data))) #對數據進行歸一化
# 生成音頻數據,ndarray不能進行json化,必須轉化為list,生成JSON
dict = {"channel":numchannel,
"samplewidth":samplewidth,
"framerate":framerate,
"numframes":numframes,
"WaveData":list(Wav_Data)}
return json.dumps(dict)
def DrawSpectrum(wav_data,framerate):
"""
這是畫音頻的頻譜函數
:param wav_data: 音頻數據
:param framerate: 采樣頻率
"""
Time = np.linspace(0,len(wav_data)/framerate*1.0,num=len(wav_data))
plt.figure(1)
plt.plot(Time,wav_data)
plt.grid(True)
plt.show()
plt.figure(2)
Pxx, freqs, bins, im = plt.specgram(wav_data,NFFT=1024,Fs = 16000,noverlap=900)
plt.show()
print(Pxx)
print(freqs)
print(bins)
print(im)
def run_main():
"""
這是主函數
"""
# MP3文件和WAV文件的地址
path2 = './MP3_File'
path3 = "./WAV_File"
paths = os.listdir(path2)
mp3_paths = []
# 獲取mp3文件的相對地址
for mp3_path in paths:
mp3_paths.append(path2+"/"+mp3_path)
print(mp3_paths)
# 得到MP3文件對應的WAV文件的相對地址
wav_paths = []
for mp3_path in mp3_paths:
wav_path = path3+"/"+mp3_path[1:].split('.')[0].split('/')[-1]+'.wav'
wav_paths.append(wav_path)
print(wav_paths)
# 將MP3文件轉化成WAV文件
for(mp3_path,wav_path) in zip(mp3_paths,wav_paths):
MP32WAV(mp3_path,wav_path)
for wav_path in wav_paths:
Read_WAV(wav_path)
# 開始對音頻文件進行數據化
for wav_path in wav_paths:
wav_json = Read_WAV(wav_path)
print(wav_json)
wav = json.loads(wav_json)
wav_data = np.array(wav['WaveData'])
framerate = int(wav['framerate'])
DrawSpectrum(wav_data,framerate)
if __name__ == '__main__':
run_main()以上是“如何使用python實現語音文件的特征提取”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





